Achieving Massive Scale: Disney+ Hotstar's Infrastructure for 60 Million Concurrent Streams
Explore how Disney+ Hotstar engineered its infrastructure to support over 60 million concurrent users during major live cricket events, achieving unprecedented scalability.
Achieving Massive Scale: Disney+ Hotstar's Infrastructure for 60 Million Concurrent Streams
In 2023, Disney+ Hotstar (now JioHotstar) faced one of the most ambitious engineering challenges in the history of online streaming: supporting 50 to 60 million concurrent live streams during major cricket events like the Asia Cup and Cricket World Cup. These events attract some of the largest online audiences globally. Previously, Hotstar had managed approximately 25 million concurrent users on two self-managed Kubernetes clusters.
To amplify this challenge, the company launched a "Free on Mobile" initiative, allowing millions to stream live matches without a subscription. This dramatically increased the expected platform load, necessitating a complete re-evaluation of its infrastructure.
Hotstar’s engineers recognized that merely adding more servers would be insufficient. The platform's architecture required fundamental evolution to handle significantly higher traffic while maintaining reliability, speed, and efficiency. This led to the adoption of a new "X architecture," a server-driven design emphasizing flexibility, scalability, and cost-effectiveness at a global scale.
The subsequent journey involved a series of profound technical overhauls. From redesigning network and API gateways to migrating to managed Kubernetes (EKS) and introducing the innovative concept of "Data Center Abstraction," Hotstar’s engineering teams tackled multiple layers of complexity. Each step aimed to ensure millions of cricket fans could enjoy uninterrupted live streams, regardless of the concurrent user count.
This article examines how the Disney+ Hotstar engineering team achieved this monumental scale and the challenges encountered.
Architecture Overview
Disney+ Hotstar serves users across various platforms, including mobile apps (Android and iOS), web browsers, and smart TVs. Irrespective of the device, every user request follows a structured path through the system.
When a user opens the app or starts a video, their request first reaches an external API gateway managed through Content Delivery Networks (CDNs). The CDN layer performs initial security checks, filters unwanted traffic, and routes the request to the internal API gateway. This internal gateway is protected by a fleet of Application Load Balancers (ALBs), which distribute incoming traffic across multiple backend services.
These backend services handle specific features such as video playback, scorecards, chat, or user profiles, retrieving or storing data from either managed (cloud-based) or self-hosted databases. Each of these layers—from CDN to database—requires meticulous tuning and scaling. Overloading even a single layer can degrade or interrupt the streaming experience for millions of viewers.
At massive scale, CDN nodes were not solely caching content like images or video segments; they also functioned as API gateways, verifying security tokens, applying rate limits, and processing each incoming request. These additional responsibilities significantly strained their computing resources, causing the system to approach limits on requests per second.
Compounding this, Hotstar was transitioning to a new server-driven architecture, altering request flow and data fetching mechanisms. This made accurately predicting the CDN layer's traffic load during peak events challenging.
To gain clarity, engineers analyzed traffic data from earlier 2023 tournaments, identifying the top ten APIs generating the most load during live streams. They discovered that API requests were not uniform; some could be cached and reused, while others demanded fresh computation for each interaction.
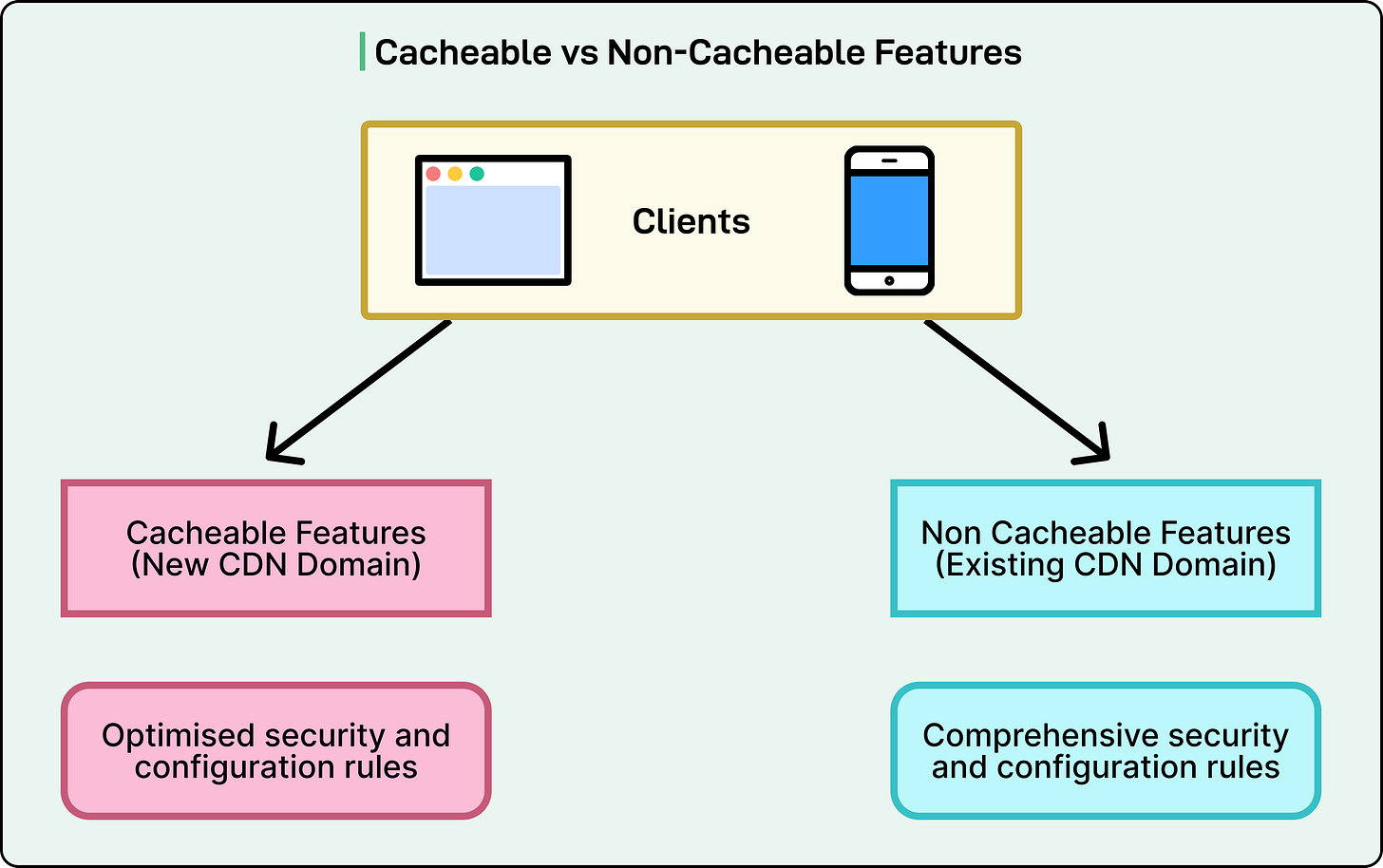
This insight spurred a crucial optimization: separating cacheable APIs from non-cacheable ones. Cacheable APIs included data that didn't change every second, such as live scorecards, match summaries, or key highlights, which could be safely stored and reused for a short period. Non-cacheable APIs managed personalized or time-sensitive data, like user sessions or recommendations, requiring fresh processing for each request.
By segregating these categories, the team optimized request handling. A new CDN domain was dedicated to serving cacheable APIs with lighter security rules and faster routing, reducing unnecessary checks and freeing computing capacity on edge servers. This resulted in significantly higher throughput at the gateway level, enabling more simultaneous users without additional infrastructure.
Hotstar also examined the refresh frequency of various features during live matches. Features like the scorecard or "watch more" suggestions didn't require second-by-second updates. By slightly reducing their refresh rates, the team decreased total network traffic without impacting the viewer experience.
Finally, engineers streamlined complex security and routing configurations at the CDN layer. Recognizing that each additional rule increases processing time, they removed unnecessary ones, conserving further compute resources.
Infrastructure Scaling Layers
With the gateway layer optimized, the team focused on deeper infrastructure layers handling network traffic and computation. Two critical system components demanded significant tuning: NAT gateways for external network connections and Kubernetes worker nodes hosting application pods.
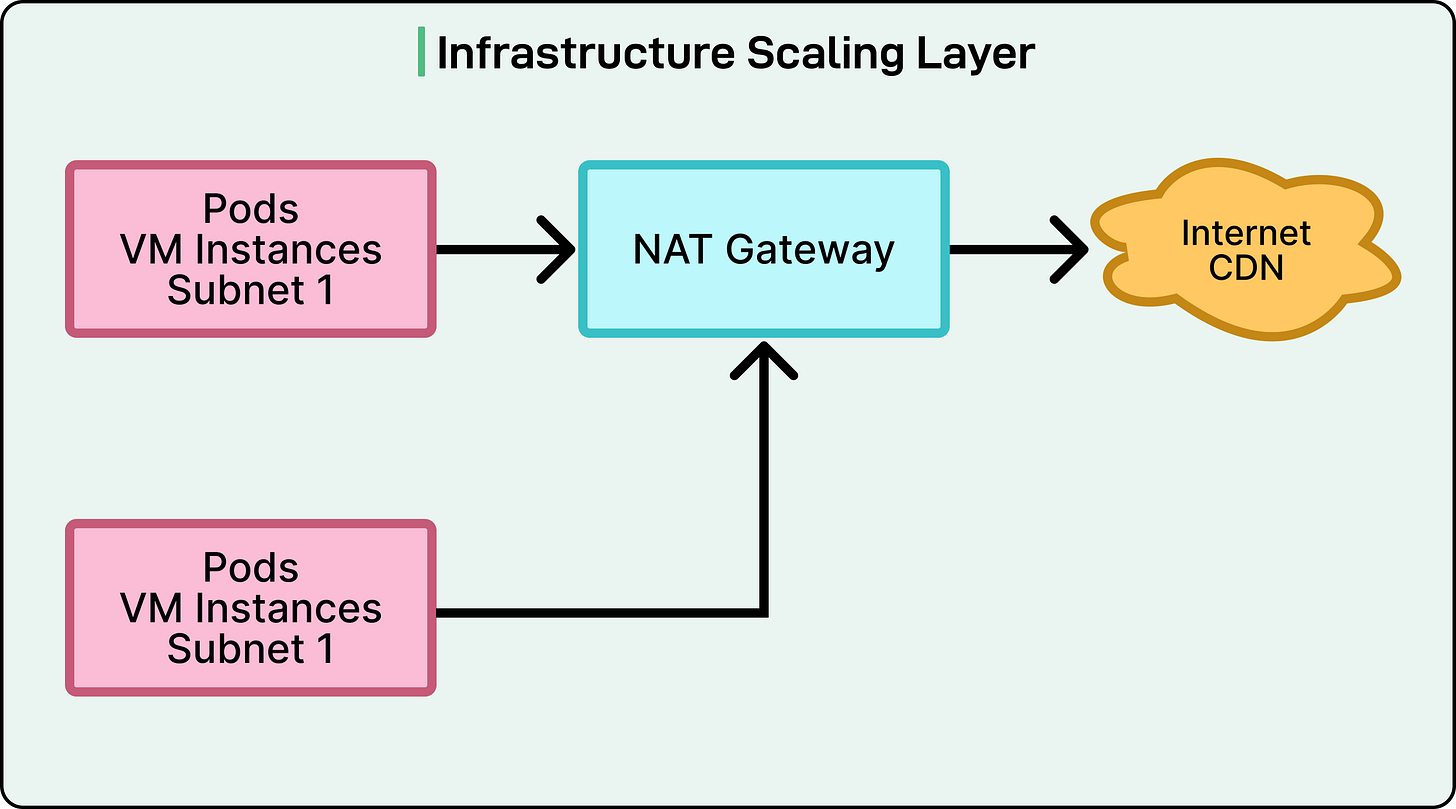
NAT Gateway Scaling
Every cloud application relies on network gateways for outgoing traffic. In Hotstar’s setup, NAT (Network Address Translation) Gateways managed traffic from internal Kubernetes clusters to the outside world, acting as translators for secure communication between private VPC resources and the internet.
During pre-event testing, engineers utilized VPC Flow Logs to collect detailed data, revealing a significant imbalance: one Kubernetes cluster consumed 50% of the total NAT bandwidth while the system operated at only 10% of the expected peak load. This indicated a severe bottleneck if traffic increased fivefold during live matches.
Further investigation uncovered that several services within the same cluster generated unusually high external traffic. Since all traffic from an Availability Zone (AZ) was routed through a single NAT Gateway, that gateway became overloaded.
The solution involved re-architecting from one NAT Gateway per AZ to one per subnet. This meant deploying multiple smaller gateways distributed across subnets instead of a few large ones, enabling more even network load distribution.
Kubernetes Worker Nodes
The next challenge emerged at the Kubernetes worker node level. These nodes run containerized services, each with limits on CPU, memory, and network bandwidth.
The team found that bandwidth-intensive services, particularly the internal API Gateway, consumed 8 to 9 gigabits per second on individual nodes. In some cases, multiple gateway pods on the same node led to contention for network resources, risking unpredictable performance during peak streaming hours.
The solution was two-fold:
- Migrating to high-throughput nodes capable of handling at least 10 Gbps of network traffic.
- Implementing topology spread constraints, a Kubernetes feature, to ensure only one gateway pod ran on each node.
This strategy prevented single node overloads and balanced network usage across the cluster, allowing each node to operate efficiently at a steady 2 to 3 Gbps throughput even during the highest traffic peaks.
EKS Migration
Despite networking and node distribution improvements, the previous setup had a limitation: the two self-managed Kubernetes clusters could not reliably scale beyond approximately 25 million concurrent users. Managing the Kubernetes control plane—responsible for scheduling and scaling workloads—had become increasingly complex and fragile under high loads.
To address this, the engineering team migrated to Amazon Elastic Kubernetes Service (EKS), AWS’s managed Kubernetes offering. This shift offloaded the most sensitive and failure-prone system component (the control plane) to AWS, allowing the team to focus on managing workloads, configurations, and data plane optimizations.
Post-migration, extensive benchmarking tests verified the stability and scalability of the new setup. The EKS clusters performed exceptionally during simulations involving over 400 worker nodes scheduled and scaled concurrently, with the control plane remaining responsive and stable.
However, beyond 400 nodes, engineers observed API server throttling. The Kubernetes API server, which coordinates all cluster communication, slowed down and temporarily limited the rate at which new nodes and pods could be created. While not causing downtime, this introduced minor delays in adding capacity during heavy scaling events.
To mitigate this, the team optimized the scaling configuration by adopting a stepwise approach. The automation system was configured to add 100 to 300 nodes per step, enabling the control plane to keep pace without triggering throttling.
The Next Phase
After migrating to Amazon EKS and stabilizing the control plane, the team achieved reliable scalability for around 25–30 million concurrent users.
However, with the 2023 Cricket World Cup approaching, it became evident that the existing setup would still be insufficient for the projected 50 million-plus users. Although technically stronger, the infrastructure remained complex to operate, difficult to extend, and costly to maintain at scale.
Hotstar managed its workloads on two large, self-managed Kubernetes clusters built using KOPS. These clusters hosted over 800 microservices, each dedicated to features like video playback, personalization, chat, and analytics. Every microservice had its own AWS Application Load Balancer (ALB), utilizing NodePort services to route traffic to pods. The typical request flow was:
Client → CDN (external API gateway) → ALB → NodePort → kube-proxy → Pod
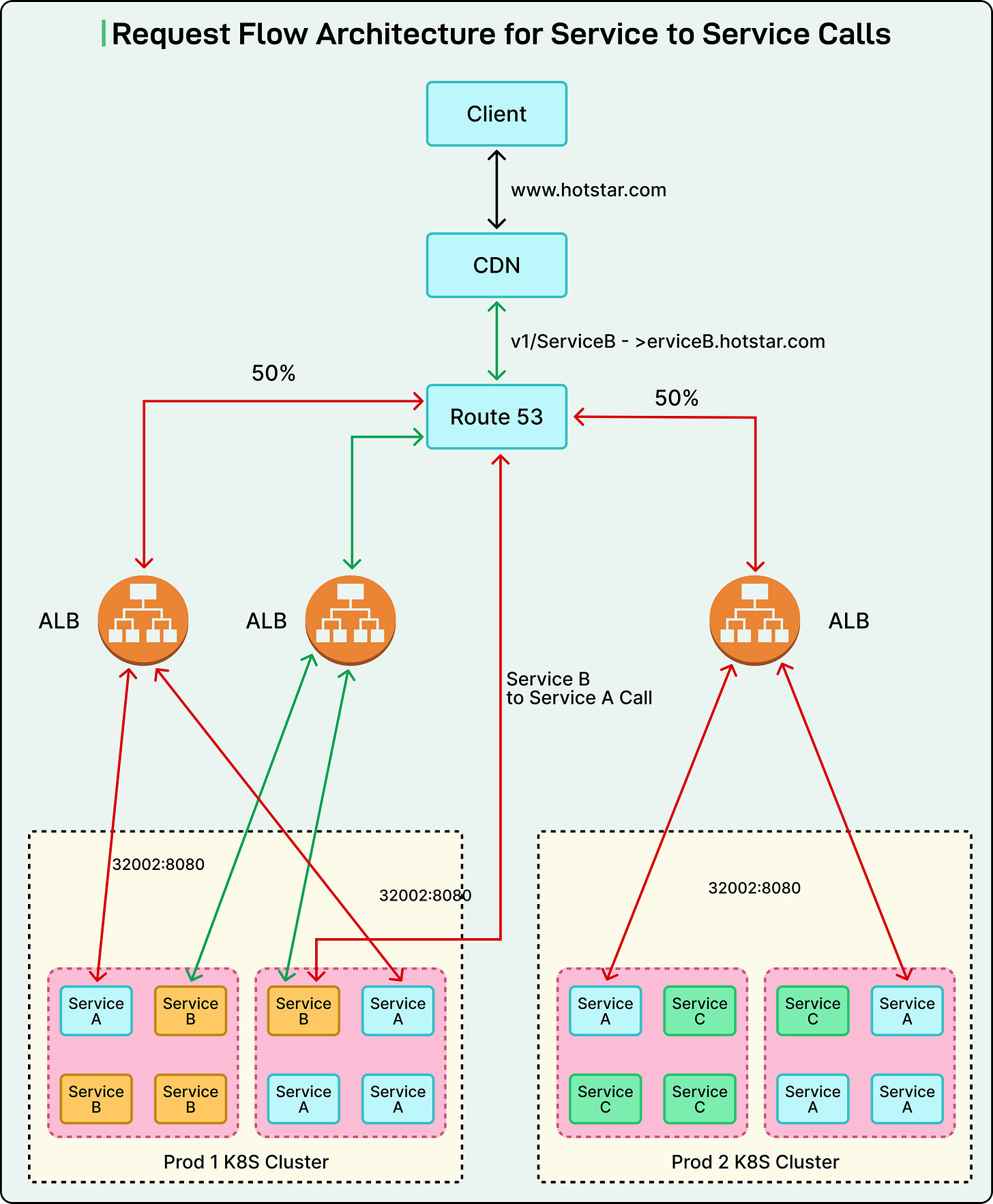
While functional, this architecture presented several inherent constraints that became increasingly problematic with platform growth:
- Port Exhaustion: Kubernetes’ NodePort service type exposes each service on a specific port within a fixed range (typically 30000 to 32767). With over 800 services, Hotstar rapidly depleted available ports, hindering the easy addition of new services or replicas without network configuration changes.
- Hardware and Kubernetes Version Constraints: The KOPS clusters ran on an older Kubernetes version (v1.17) and previous-generation EC2 instances. These versions lacked support for modern instance families like Graviton, C5i, or C6i, which offer superior performance and efficiency. Furthermore, the older version prevented leveraging newer scaling tools such as Karpenter, which automates node provisioning and optimizes costs by quickly shutting down underused instances.
- IP Address Exhaustion: Each deployed service consumed multiple IP addresses—one for the pod, one for the service, and additional ones for the load balancer. As service numbers grew, Hotstar’s VPC subnets began running out of IP addresses, creating scaling bottlenecks. Adding new nodes or services often required purging existing ones, decelerating development and deployments.
- Operational Overhead: Before every major cricket tournament or live event, the operations team had to manually pre-warm hundreds of load balancers to ensure they could handle sudden traffic spikes. This was a time-consuming, error-prone process demanding cross-team coordination.
- Cost Inefficiency: The older cluster autoscaler in the legacy setup was insufficiently fast to consolidate or release nodes efficiently.
Datacenter Abstraction
To overcome these limitations, Disney+ Hotstar introduced a new architectural model: Datacenter Abstraction. In this model, a "data center" denotes not a physical building, but a logical grouping of multiple Kubernetes clusters within a specific region. Collectively, these clusters function as a single large compute unit for deployment and operations.
Each application team is assigned a single logical namespace within a data center. This liberates teams from concern over which specific cluster their application runs on, making deployments cluster-agnostic, with traffic routing automatically managed by the platform.
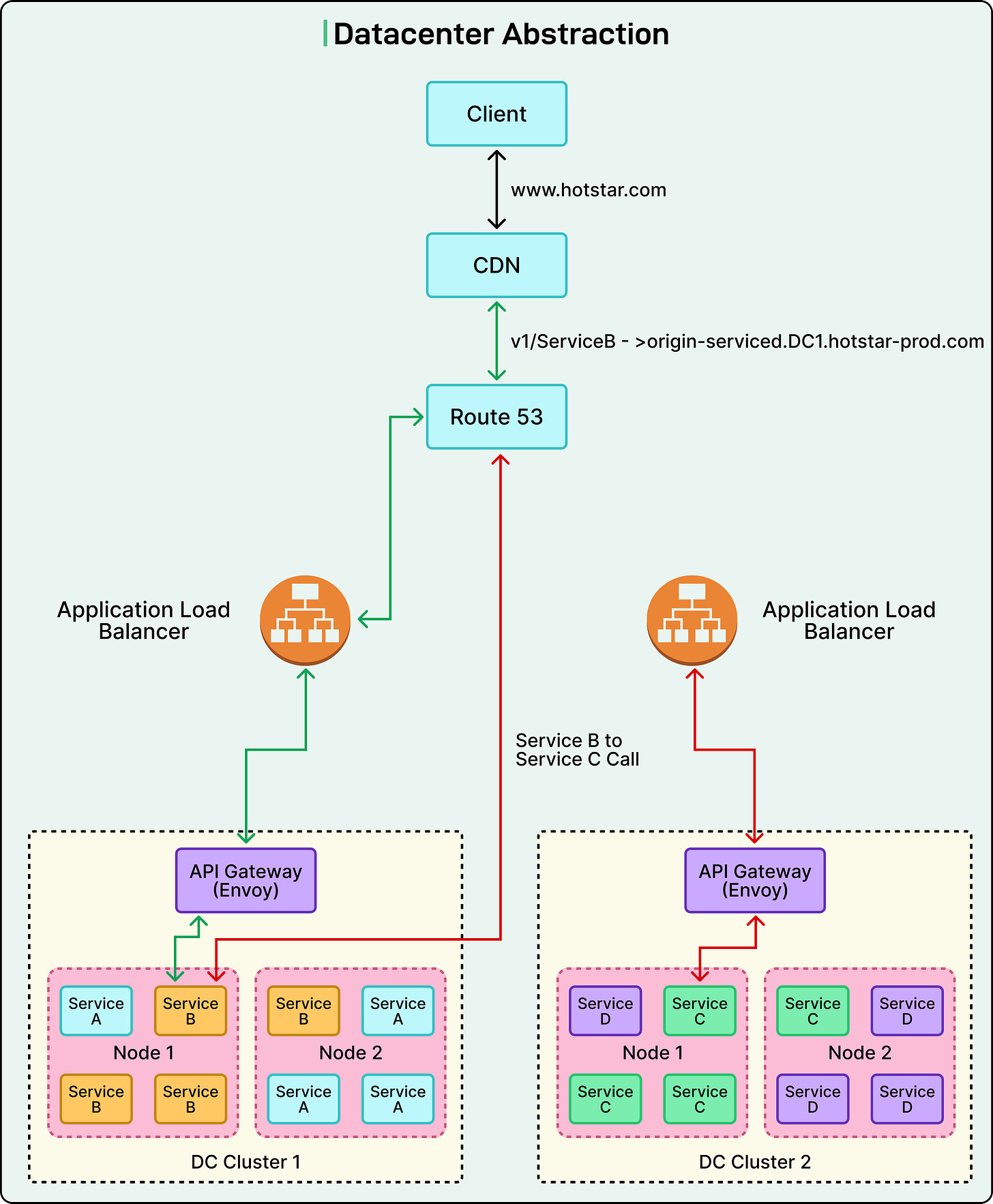
This abstraction profoundly simplified infrastructure management. Instead of dealing with individual clusters, teams operated at the data center level, yielding several significant benefits:
- Simplified failover and recovery: Workloads could shift to another cluster during an issue without configuration changes.
- Uniform scaling and observability: Resources across clusters could be managed and monitored as a unified system.
- Centralized routing and security: Rate limiting, authentication, and routing rules were handled by a common platform layer.
- Reduced management overhead: Engineering teams could concentrate on applications rather than constant infrastructure maintenance.
Key Architectural Innovations
The team implemented several key architectural innovations:
Central Proxy Layer (Internal API Gateway)
A new central proxy layer, powered by Envoy, formed the core of Datacenter Abstraction. This layer served as the single control point for all internal traffic routing.
Previously, each service had its own Application Load Balancer (ALB), requiring management and scaling of over 200 individual load balancers. The new Envoy-based gateway consolidated these into a single, shared fleet of proxy servers.
This gateway managed several critical functions:
- Traffic routing: Directing requests to the correct service, irrespective of its cluster location.
- Authentication and rate limiting: Ensuring all internal and external requests were secure and controlled.
- Load shedding and service discovery: Managing temporary overloads and automatically identifying correct service endpoints.
By embedding this gateway layer within each cluster and centralizing routing, complexity was hidden from developers. Application teams no longer needed to concern themselves with service locations; the platform handled everything transparently.
EKS Adoption
The Datacenter Abstraction model fully embraced Amazon Elastic Kubernetes Service (EKS), completing the transition away from self-managed KOPS clusters. This provided Hotstar with crucial advantages:
- Managed control plane: AWS managed critical control components, reducing maintenance effort and enhancing reliability.
- Access to newer EC2 generations: The team could now utilize the latest high-performance and cost-efficient instance types, such as Graviton and C6i.
- Rapid provisioning: New clusters could be quickly created to meet escalating demand.
- Unified orchestration: Multiple EKS clusters could operate cohesively as part of one logical data center, simplifying cross-environment management.
Standardized Service Endpoints
To streamline service communication, a unified endpoint structure was introduced across all environments. Prior to this, disparate teams created their own internal and external URLs, leading to confusion and configuration errors.
Under the new system, every service adhered to a clear, consistent pattern:
- Intra-DC (within the same data center):
<service>.internal.<domain> - Inter-DC (between data centers):
<service>.internal.<dc>.<domain> - External (public access):
<service>.<public-domain>
This significantly simplified service discovery and allowed engineers to migrate services between clusters without altering their endpoints. It also improved traffic routing and reduced operational friction.
One Manifest
In the earlier architecture, deploying an application necessitated maintaining five or six distinct Kubernetes manifest files for different environments (e.g., staging, testing, production), leading to duplication and cumbersome updates.
To resolve this, the team introduced a single unified manifest template. Each service now defines its configuration in one base file, applying minimal overrides only when necessary (e.g., for adjusting memory or CPU limits). Infrastructure details—such as load balancer configurations, DNS endpoints, and security settings—were abstracted into the platform itself, eliminating manual management.
This approach delivered several benefits:
- Reduced duplication of configuration files.
- Faster and safer deployments across environments.
- Consistent standards across all teams.
Each manifest includes essential parameters like ports, health checks, resource limits, and logging settings, ensuring uniform structure for every service.
Eliminating NodePort Limits
One of the most significant technical improvements involved replacing NodePort services with ClusterIP services using the AWS ALB Ingress Controller.
NodePort required assigning a unique port to each service within a fixed range, imposing a hard limit on simultaneously exposed services. Adopting ClusterIP directly connected services to their pod IPs, removing the need for reserved port ranges.
This change resulted in a more direct traffic flow and simplified overall network configuration. It also allowed the system to scale far beyond previous port limitations, ensuring uninterrupted operation even at massive traffic volumes.
Conclusion
By the completion of its transformation to the Datacenter Abstraction model, Disney+ Hotstar’s infrastructure had evolved into one of the most sophisticated and resilient cloud architectures in the streaming world. The final stage of this evolution centered on a multi-cluster deployment strategy, with decisions driven entirely by real-time data and service telemetry.
For every service, engineers meticulously analyzed CPU, memory, and bandwidth usage to understand performance characteristics. This data guided decisions on service co-location versus isolation. For instance, compute-intensive workloads like advertising systems and personalization engines were placed in dedicated clusters to prevent them from impacting latency-sensitive operations such as live video delivery.
Each cluster was carefully designed to host only one P0 (critical) service stack, guaranteeing that high-priority workloads always had sufficient headroom for unexpected demand spikes. In total, the production environment was reorganized into six well-balanced EKS clusters, each finely tuned for different workload types and network patterns.
The results of this multi-year effort were remarkable. Over 200 microservices were migrated into the new Datacenter Abstraction framework, operating through a unified routing and endpoint system. The platform replaced hundreds of individual load balancers with a single centralized Envoy API Gateway, dramatically simplifying traffic management and observability.
When the 2023 Cricket World Cup commenced, the impact of these changes was evident. The system successfully handled over 61 million concurrent users, establishing new records for online live streaming without major incidents or service interruptions.