Cache-Augmented Generation (CAG) vs. Retrieval-Augmented Generation (RAG): A Visual Guide
Explore the differences between Retrieval-Augmented Generation (RAG) and Cache-Augmented Generation (CAG). Learn how combining these approaches can enhance LLM performance by strategically caching stable knowledge and dynamically retrieving fresh data, leading to faster, more efficient AI systems.
Retrieval-Augmented Generation (RAG) has revolutionized the development of knowledge-grounded AI systems. However, it presents a common challenge: for every query, the model frequently re-fetches identical context from the vector database. This repetitive retrieval can lead to increased costs, redundancy, and slower performance.
Cache-Augmented Generation (CAG) offers an elegant solution to this limitation. CAG enables the model to "remember" stable information by caching it directly within its key-value memory. This approach can be further optimized by seamlessly integrating RAG and CAG, as illustrated in the diagram below:
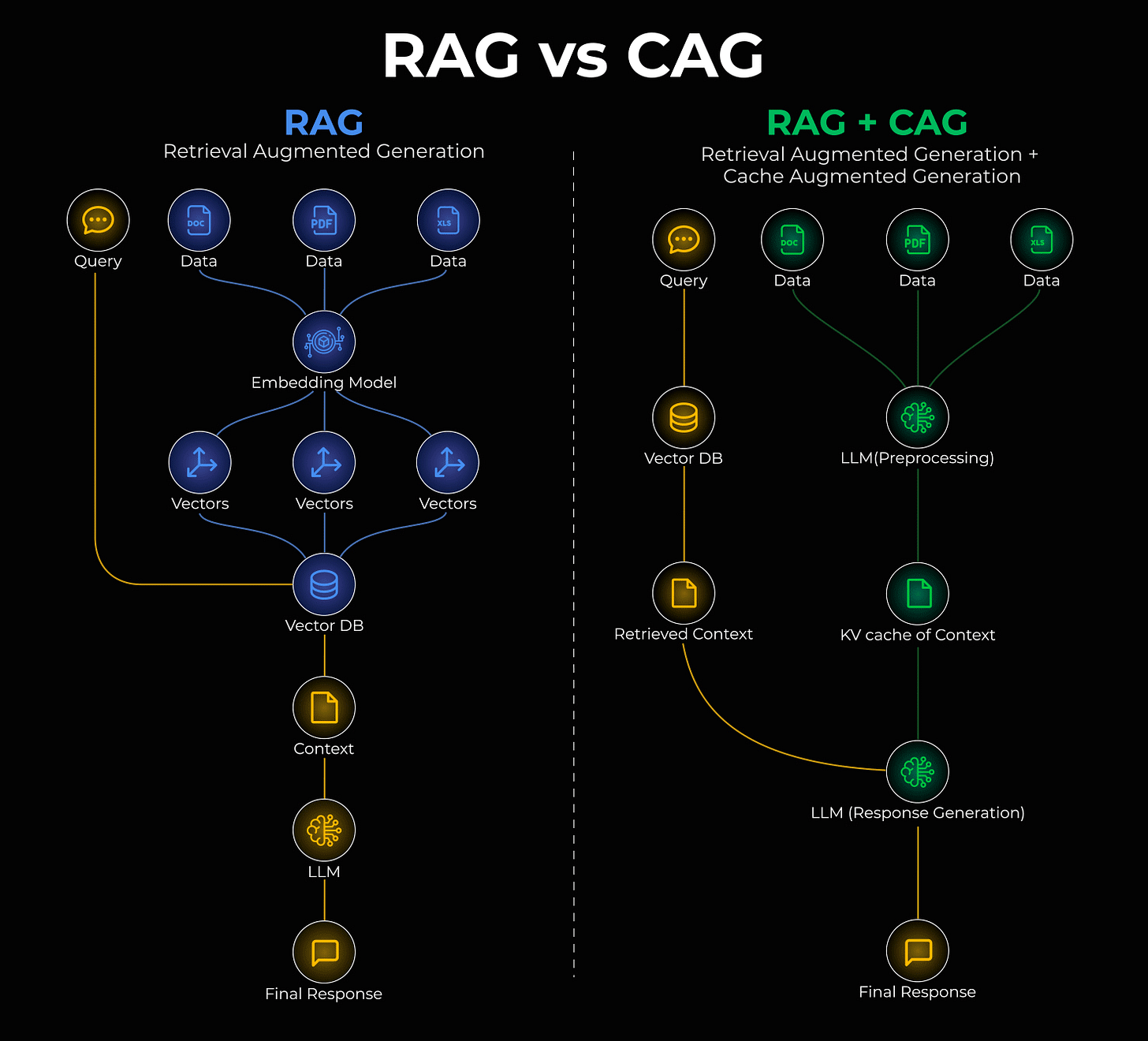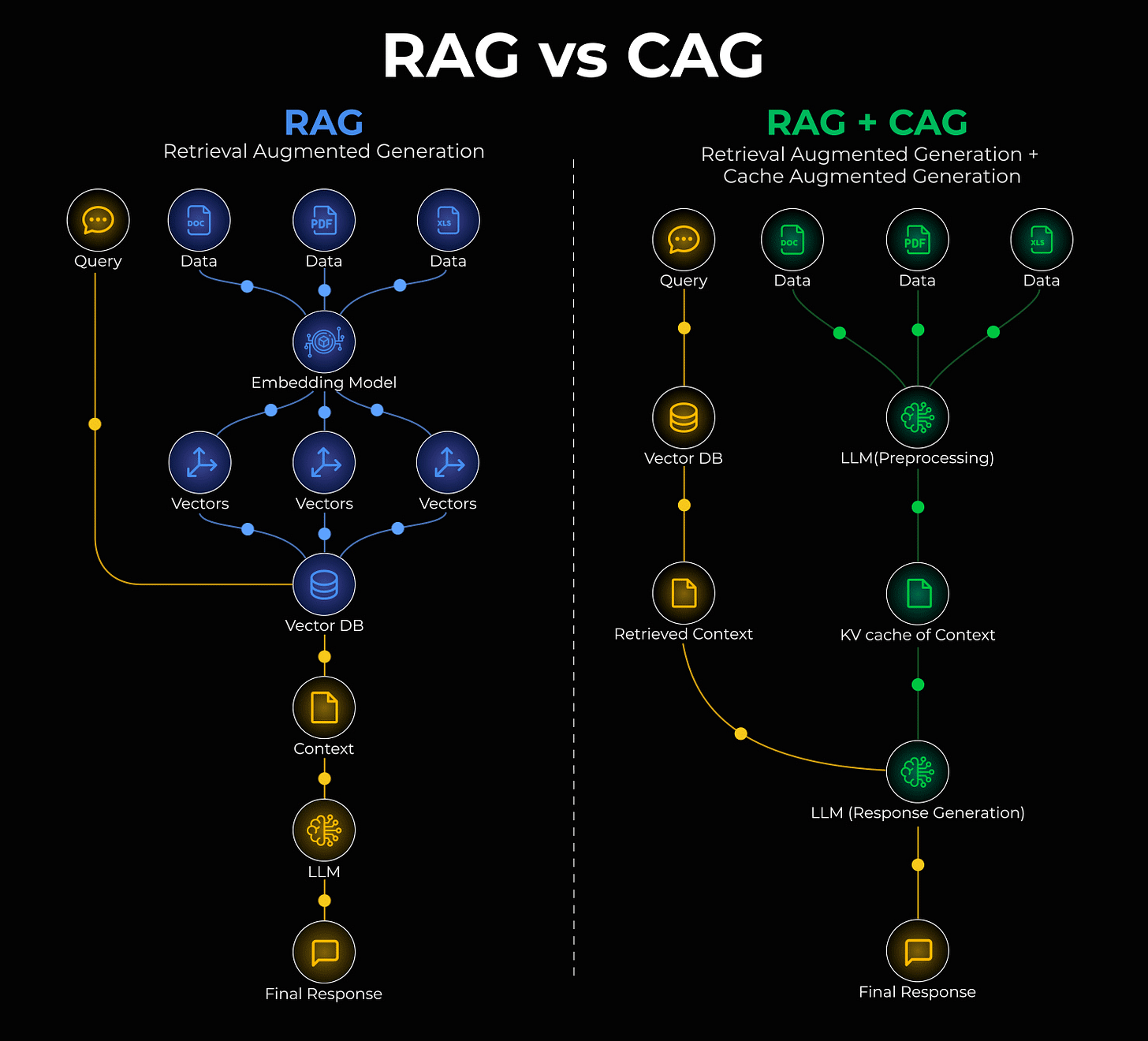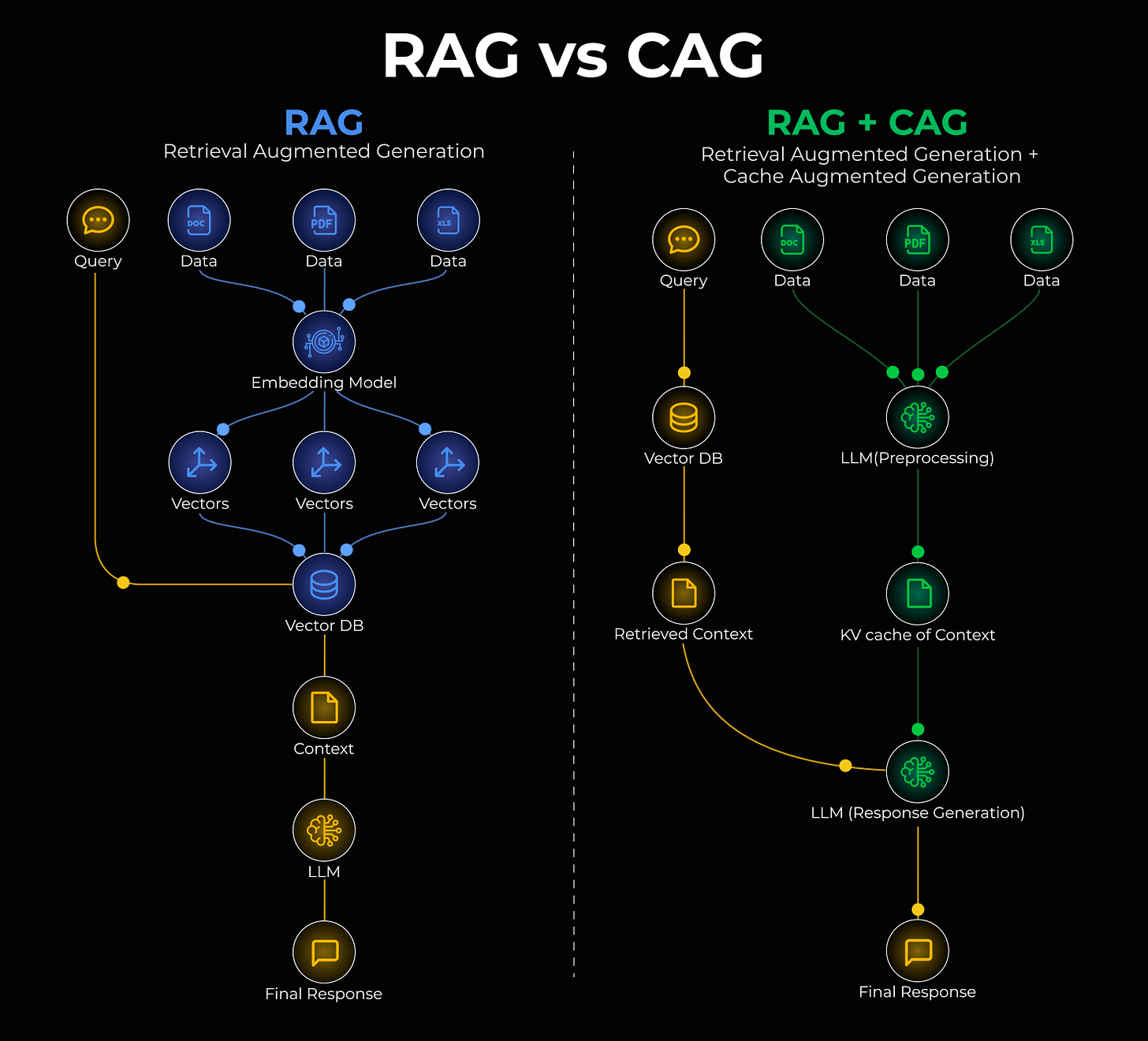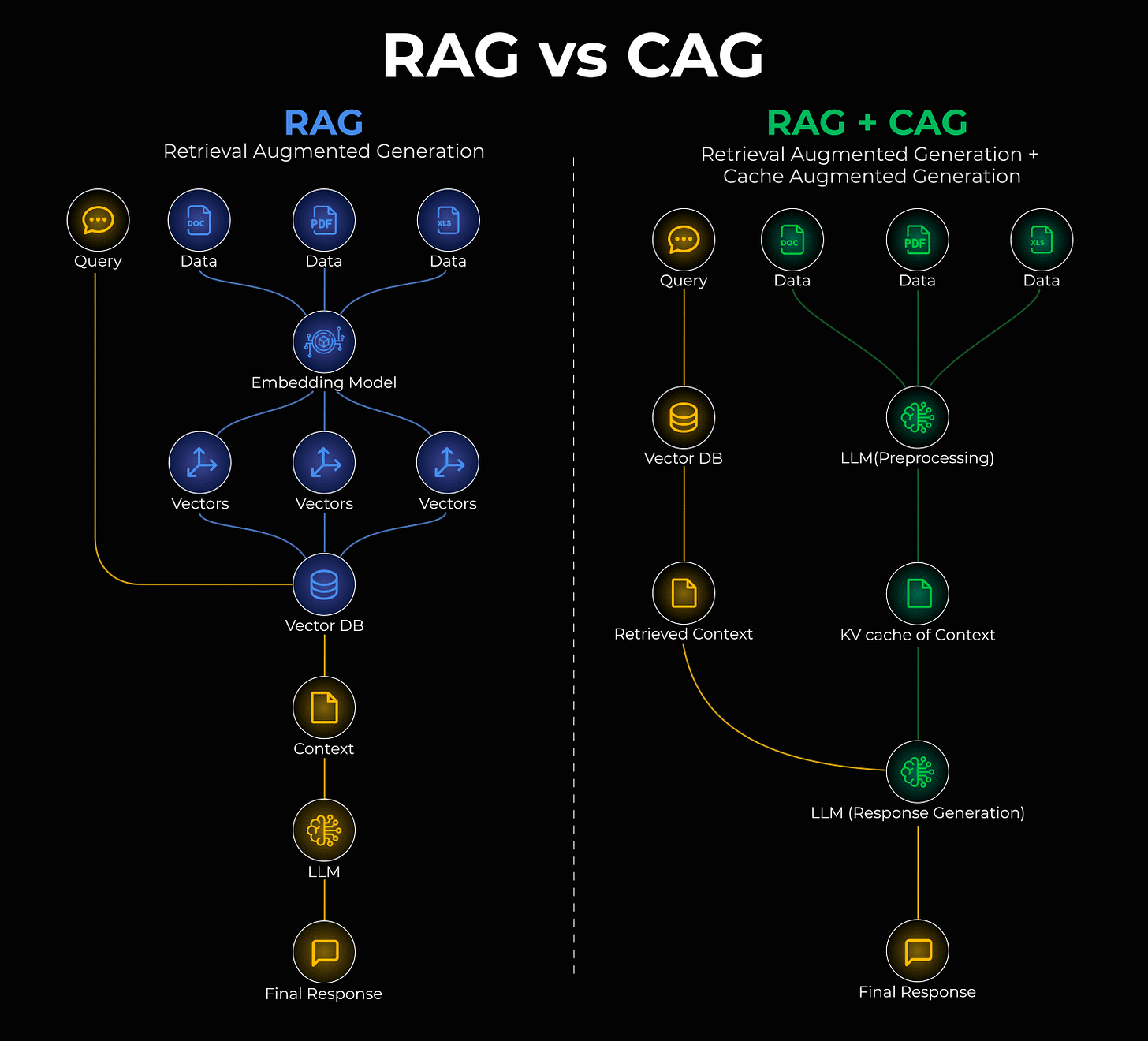
Here’s a simplified explanation of how this hybrid system operates:
In a conventional RAG setup, an incoming query is directed to a vector database, which then retrieves relevant data chunks to be fed into the Large Language Model (LLM).
With the RAG + CAG fusion, your knowledge base is intelligently structured into two distinct layers:
- Static Layer: Stable, infrequently changing data, such as company policies or foundational reference guides, is cached once within the model's KV memory.
- Dynamic Layer: Frequently updated information, like recent customer interactions or live documents, continues to be fetched through the standard retrieval process.
This dual-layer approach eliminates the need for the model to reprocess static information repeatedly. It accesses cached data instantly and augments it with fresh, retrieved content, resulting in significantly faster inference times.
The effectiveness of this system hinges on selective caching. It is crucial to cache only stable, high-value knowledge that exhibits minimal change over time. Attempting to cache all data would quickly lead to context limits. Therefore, the strategic separation of "cold" (cacheable) and "hot" (retrievable) data is fundamental to maintaining system reliability and efficiency.
Many modern LLM APIs, including those from OpenAI and Anthropic, already incorporate prompt caching functionalities, allowing developers to experiment with these concepts immediately.