Designing Effective Log-Navigation Tools for AI Agents
Explore Buildkite's process of designing robust log-navigation tools for AI agents. Learn how raw CI logs are transformed into structured data, allowing agents to efficiently diagnose build failures and extract critical insights.
Following a recent publication providing a high-level overview of the Buildkite MCP server and the tools it exposes, we highlighted significant work around more efficient log fetching, parsing, and querying. This article delves deeper, detailing the comprehensive process behind presenting logs in a usable format for AI agents, particularly when addressing critical questions like, "Why did my build fail?"
Background on Our MCP Server
When initiating the MCP server project, our primary goals were clear: to provide AI agents with a simple, consistent method for interacting with Buildkite, and to ensure the MCP server utilized the same public REST API that our users already rely on, thereby avoiding new surface areas or differing permission models.
From its inception, the MCP server was developed openly. Customers quickly integrated agents into their real pipelines and began posing questions such as:
- How does this pipeline work?
- What is the current state of this pipeline?
- How can I improve it?
- Can you analyze the last 10 executions and identify any obvious issues?
- Are there any slow steps here that could be split up or made faster?
To empower AI agents to answer these questions, we initially offered a set of MCP tools that simply wrapped and returned the output of our REST API, including a sanitized version of job logs. While these tools largely functioned, a significant challenge emerged: job logs vary wildly in response size, especially during build failures that often produce pages of stack traces or verbose debug output.
Why CI Logs Are a Challenge for AI Agents
Buildkite’s job logs are generated from the raw bytestream of a pseudo-terminal (PTY). We store the complete stream as it’s the most reliable way to capture the exact sequence of events, allowing the UI to accurately replay the job's actual printed output. Consequently, our logs can contain ANSI escape sequences, dynamic progress bars, lines that appear and then clear, timestamps embedded within escape sequences, and UI group markers.
For instance, here's a screenshot of a raw build log from the Bun project's public Buildkite pipeline, illustrating ANSI escape codes and timestamps encoded directly into the output:

However, this same section renders as a single line in the Buildkite dashboard:
2025-09-04 04:19:09 UTC remote: Counting objects: 100% (12374/12374), done.
While the dashboard processes and renders the log to show only the final state, agents working with the raw stream encounter every intermediate update, line clear, and escape sequence.
Our first MCP implementation exposed this output using a basic wrapper around the API endpoint that returned the full terminal stream. This initial approach proved ineffective with large logs. If an LLM is presented with a 200MB terminal stream, it typically starts at the top and fixates on the first error it encounters, often missing the actual root cause of the job failure, which might appear much later in the log.
Our First Attempt: A tail Tool
Once it became evident that returning the full log yielded poor results, our next idea was to provide the LLM with a tail_logs tool, enabling it to fetch only the end of the log. Engineers commonly navigate to the end of a job log and scroll backward, assuming the last error is likely the cause of the failure.
This improvement offered some help, and external contributors further refined the concept by experimenting with saving large logs to disk, allowing the agent to run tail or grep commands independently. However, this approach presented its own set of problems given the requirements for Buildkite’s MCP server:
- Consistent behavior in local and hosted modes: Saving logs to disk works well on a developer’s machine but is incompatible with hosted or Dockerized environments. Furthermore, security concerns led us to avoid direct filesystem access.
- Agent environment independence: We aimed for the server to function with any type of agent—chat agents, coding agents, cloud-hosted, local, etc. Relying on an agent's ability to run
greportailwas too brittle. - Varied agent behavior: This approach largely left log analysis to the agent's discretion, which was effective for some agents but not for others.
After acknowledging that a tail_logs tool alone was insufficient, the crucial question became: What does an agent truly need to navigate a log effectively, similar to how a human would?
Designing Log-Navigation Tools
When an agent is asked, "Why did build 123 fail?", a reasonable investigative path might include:
- Checking the build status to identify any failed jobs.
- Tailing the logs for the associated job steps.
- Paging through the logs around the failure point to understand the breakdown.
- Reviewing any build annotations that might provide additional context.
- Summarizing the events and pointing to relevant tests, source files, or failing commands.
Humans perform these steps instinctively, but getting an agent like Claude Code or Amp to autonomously follow this path can be surprisingly difficult. Building upon the tail tool, we realized the need for a concise set of structured tools that would make logs addressable and allow agents to read them in a controlled manner.
Step 1: Make the Logs Navigable
First, we introduced a preprocessing step within the MCP server to transform the raw stream into a line-oriented format. This process strips out ANSI codes, preserves lines that were printed and subsequently cleared, extracts timestamps, records log groups, and splits the output into clean entries. The goal is to make the log predictable and indexable.
Subsequently, the processed log is written to Parquet. Within the buildkite-logs library, a process converts the parsed log lines, along with metadata extracted from the raw output (such as timestamps), into a Parquet file.
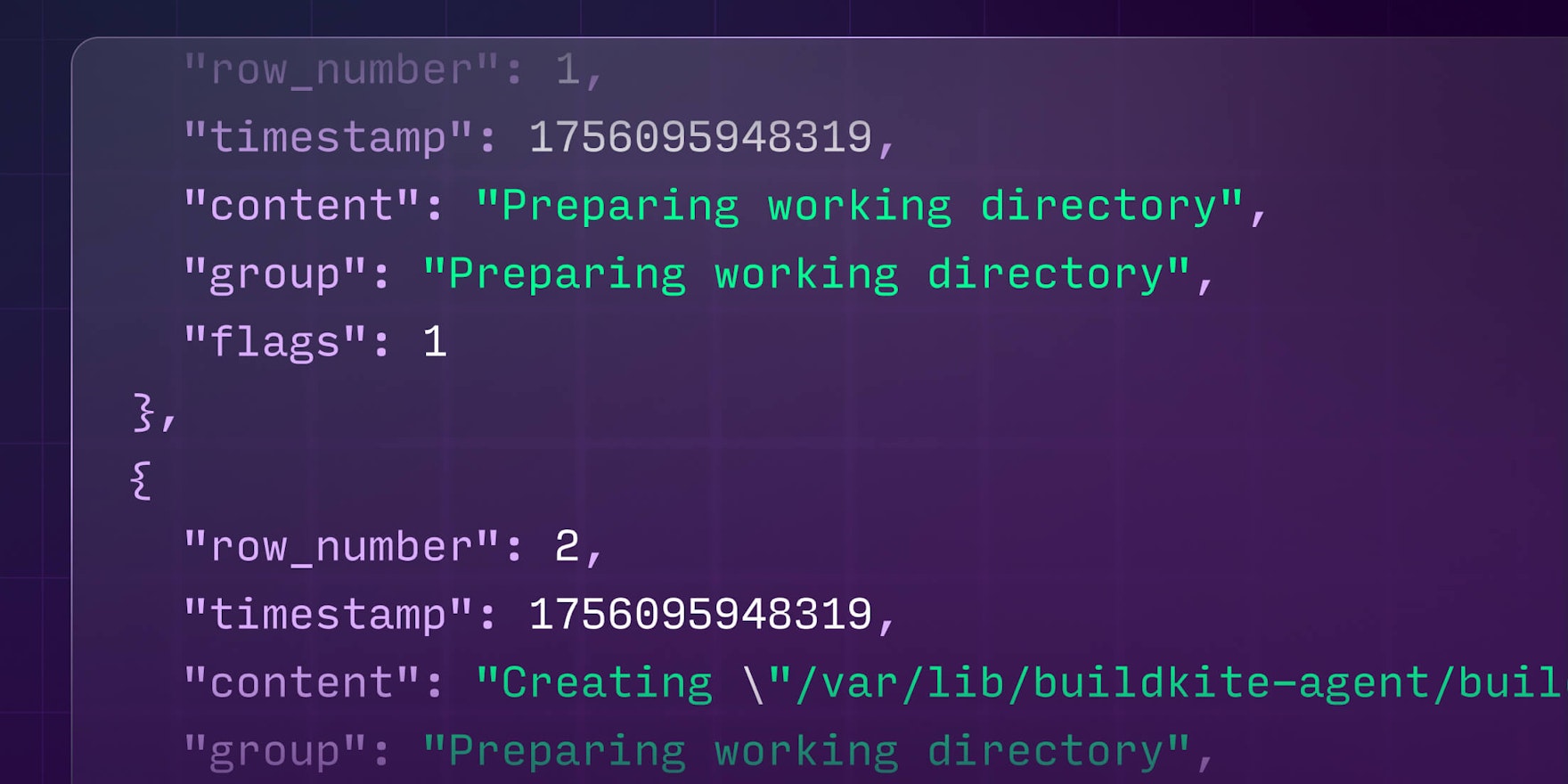
We defined a structured format for log entries with four columns:
timestamp: Milliseconds since epoch (Int64)content: The actual log text (String)group: The section/group name (String)flags: Metadata flags (Int32)
This format enables efficient reading and scanning of one or all columns, which is highly beneficial for filtering or aggregation tasks.
Here's how the processed output appears when queried, with each log entry as a clean, structured record:
[
{"row_number": 1, "timestamp": 1756095948319, "content": "Preparing working directory", "group": "Preparing working directory", "flags": 1},
{"row_number": 2, "timestamp": 1756095948319, "content": "Creating \"/var/lib/buildkite-agent/builds/ip-172-31-90-181/bun/bun\"", "group": "Preparing working directory", "flags": 1},
{"row_number": 3, "timestamp": 1756095948319, "content": "$ cd /var/lib/buildkite-agent/builds/ip-172-31-90-181/bun/bun", "group": "Preparing working directory", "flags": 1},
{"row_number": 8, "timestamp": 1756095949112, "content": "remote: Enumerating objects: 12374, done.", "group": "Preparing working directory", "flags": 1},
{"row_number": 9, "timestamp": 1756095949112, "content": "remote: Counting objects: 100% (12374/12374), done.", "group": "Preparing working directory", "flags": 1}
]
Parquet also offers fast random access and excellent compression, contributing to low latency for agent calls and minimizing token usage.
Step 2: Discover the Right Tools with Help from Claude
Once our logs were in Parquet format, the main challenge was to determine precisely what an agent needed to follow the correct debugging path.
We addressed this using an LLM—essentially employing Claude to critique its own performance. We would provide an agent with logs, allow it to make tool calls to diagnose a build failure, and then feed the entire trace back into a fresh Claude session. We then asked Claude to explain where its reasoning faltered and what additional tools or description adjustments would have prevented that failure. Claude proved exceptionally candid in reviewing its mistakes, consistently highlighting missing primitives and ambiguous tool semantics.
After several iterations of this Claude-auditing-Claude loop, the tool interface converged, resulting in four key log-navigation tools:
tail_logs: Returns the lastNlines of a processed log (the typical starting point for most investigations).search_logs: Performs a regex search with optional before/after context lines.read_logs: Reads a window of lines from an absolute row offset, either forward or backward.get_logs_info: Returns metadata about the processed log (e.g., size, total rows, available groups).
These tools proved sufficient for agents to reliably replicate the human debugging workflow without requiring us to embed that workflow directly into an LLM prompt.
What We Learned
This experience offered several important lessons regarding AI agents:
- It's tempting to wrap your REST API in MCP tools and assume the model will seamlessly integrate everything. However, this approach is rarely optimal.
- When developing an MCP server, you don't control the agent's prompts or overall strategy. Your primary leverage lies in the design and shape of the tools you expose. LLMs, by nature, seek the path of least resistance, so the objective is to make the correct actions the easiest ones to take—much like guiding water to flow downhill.
- When providing information to agents, it is crucial to avoid noisy, ambiguous data. Otherwise, the quality of analysis or summarized information will vary significantly. To maximize the effectiveness of these systems, the challenge is to provide precisely the right amount of information related to a failure or issue.
If you wish to explore it yourself, the Buildkite MCP server is open source and available in both local and fully-hosted versions. We designed it as both a useful integration layer and a reference implementation for anyone building agentic workflows on top of CI systems.
We welcome contributions and feedback from the community! The best way to engage with us is by filing an issue on GitHub.