DuckDB as an OLAP Cache: Database Simplicity, Cache Speed
Explore how DuckDB and its ecosystem provide high-performance OLAP caching, combining database simplicity with cache-like speed. Discover practical implementations and strategies to overcome common data analytics bottlenecks without complex infrastructure.
The Simplicity of a Database, The Speed of a Cache: OLAP Caches for DuckDB
In the realm of data analytics, a persistent challenge is achieving rapid performance across the entire data lifecycle, from ingestion and processing to visualization. Business Intelligence (BI) dashboards, in particular, often struggle with slow response times due to complex SQL queries involving extensive groupings and aggregations over multiple dimensions, especially as data volumes grow.
While pre-computation in data pipelines (e.g., using dbt) is an option, it's not always feasible. Users frequently need to aggregate data on-the-fly, dynamically switching between dimensions like region, date, or product lines, making it impractical to pre-store every possible aggregation. Traditional OLAP cubes offer a solution, optimizing for these types of queries with internal cache layers and pre-aggregation. However, they introduce another system, additional ingestion pipelines, and significant engineering effort for integration and maintenance.
Why Implement a Cache (with DuckDB)?
Investing in OLAP or database caching primarily addresses the critical need for speed and convenience. In today's fast-paced development environments, where immediate results are prioritized, slow query execution and unresponsive dashboards quickly become bottlenecks.
The typical scenario involves a sluggish BI query. Requesting an index or a persistent table from BI or data engineering teams can be a lengthy process. While re-architecting the data flow with dedicated stages for ingestion, transformation, historization, and presentation (following classical data warehouse architectures like Kimball) is the ideal long-term solution, time constraints often prevent this. A pragmatic approach, even within traditional architectures, is to introduce a fast cache directly in front of the BI or visualization layer.
The easier this cache is to implement, update, and retrieve results from, the more valuable it becomes. Caching remains highly sought after because it can mitigate shortcomings in initial architectural designs, ensuring quick response times and enhancing the user experience.
Are Traditional OLAP Cubes Obsolete?
Historically, OLAP cubes or modern OLAP systems were the go-to for achieving sub-second response times for analytical queries. However, they can be challenging to maintain, especially regarding data ingestion, schema evolution, and the general data engineering plumbing required for frequent updates.
At their core, OLAP cubes function as a cache. The goal now is to achieve similar caching benefits with significantly less effort. This is where modern solutions like DuckDB and MotherDuck shine, offering quick and easy deployment. DuckDB, a lightweight, embeddable binary database, can run almost anywhere—even in a web browser. MotherDuck extends this by providing scalable, shareable capabilities simply by changing a path (e.g., md: instead of a local DuckDB path).
Essentially, a modern cache should offer:
- Speed: Deliver fast answers to user-facing dashboards, reports, and web applications.
- Convenience: Simplify data access, eliminating the need for manual materialization of BI queries.
- Utilization: Be easy to run and move, acting as a versatile tool that adapts to various environments.
For customer-facing or business-critical data, speed is paramount. Adding an extra OLAP layer often incurs higher costs and demands additional ingestion steps and data engineering. In contrast, a simple cache offers the advantage of simplicity, with much of the complexity handled transparently.
Diverse Approaches to Data Caching
The data landscape offers a multitude of caching options, which can be applied at various levels of the data flow and lifecycle. These range from application-level caching within BI tools to pre-persisting data mart tables, and solutions like Dremio or Presto that incorporate caching mechanisms.
The effectiveness of caching generally increases the closer it is positioned to the visualization or frontend used by the end-user. Caching earlier in the ETL process primarily speeds up pipelines and batch jobs, but does not directly benefit dashboard response times.
Here are potential caching points, moving from customer-facing visualization towards logical and varying "temperatures" of data:
- Data Applications: Application-level caches within BI tools, notebooks, or frontend web apps.
- WASM (WebAssembly): An open standard for executing binary code in web browsers. This enables advanced, in-browser caches using single-binary databases like SQLite or DuckDB, providing instant analytical speed. For example, Evidence is using this technology to power its universal SQL engine directly in the browser.
- Hot Cache: Typically found in an Operational Data Store (ODS), where data is prepared for daily, fast consumption, especially when the main data warehouse is too slow due to extensive historical data or source databases cannot be directly queried. Any frequently accessed, cached data could be considered "hot." Message queues storing short-term data (e.g., for weeks) are another example.
- SQL Intermediate Storage: The most widespread approach involves persistent SQL-based tables, often implemented as materialized views or dbt models. These are most effective at the data mart level, where data is prepared and aggregated to the correct granularity for fast, convenient consumption.
- Logical Caches:
- Virtualization and Federation: Data tables are logically joined across different sources without physical storage, then cached within data virtualization tools like Trino, Presto, or Dremio.
- Semantic Layer or OLAP Cubes: Data is modeled within a logical layer, which then optimizes cache usage for potential and actual queries, efficiently caching aggregate data.
- Cold Cache: While not strictly a cache, data lakes often store dbt results, backups, and active data. Other technologies (e.g., MotherDuck, Starlake) are then used to "warm up" this data for faster consumption.
- Zero-Copy ETL: Approaches like DuckDB and Apache Arrow can act as intermediate utilities to query any data quickly or facilitate zero-copy cloning, minimizing data duplication.
While these categories are not entirely distinct, they offer a comprehensive view of caching strategies and how they can be applied, particularly for OLAP caches.
The Evolution of Caching for BI Workloads
Examining the history of BI workload caching, a complex problem for decades, offers valuable insights. Past solutions for analytics performance provide inspiration for current implementations of persistent data layers and caches.
The chronological progression, though simplified, illustrates a fascinating trend:
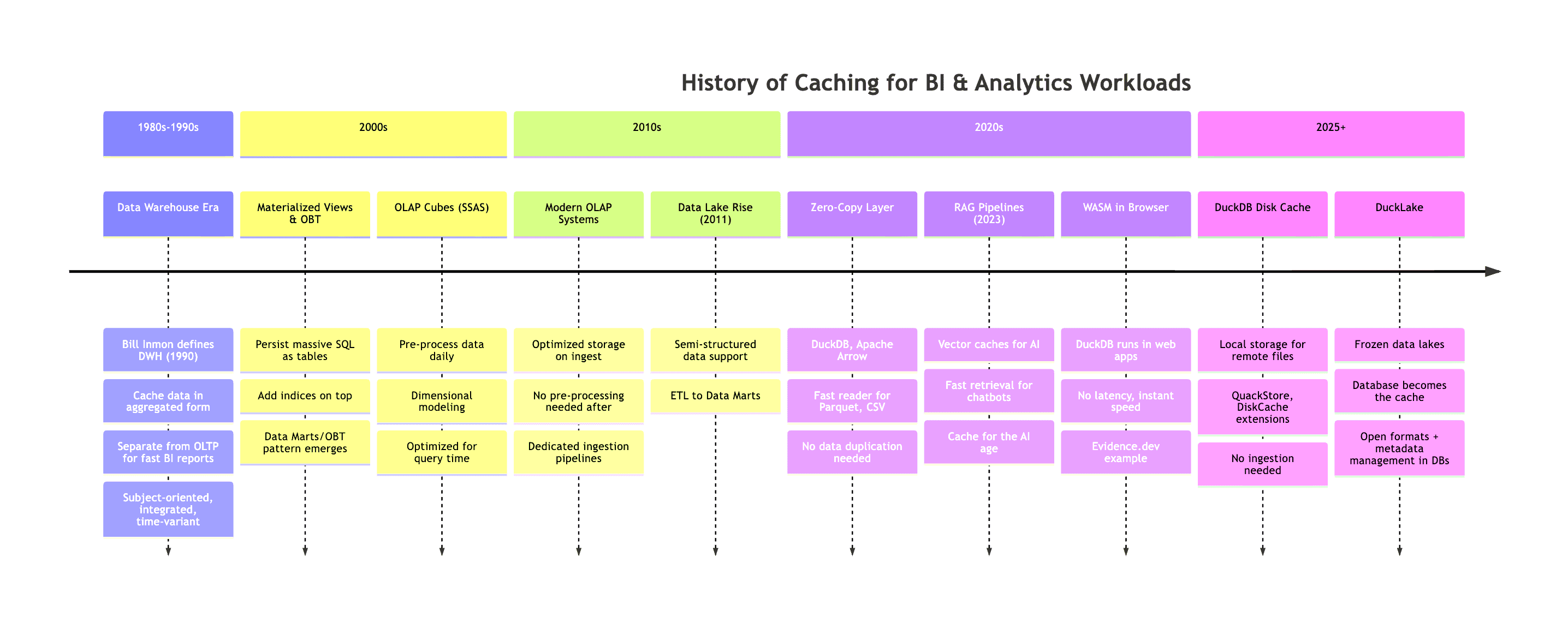
This image highlights a recurring "pendulum swing" between server-side and client-side caching. We’ve moved from server-side data warehouses with materialized views (MVs) and "one-big-table" (OBT) approaches to bringing data directly to web applications (e.g., via WASM), sometimes eliminating the need for traditional caching altogether due to fast client-side data availability or zero-copy layers with DuckDB leveraging powerful client hardware.
However, independent and automated data caching remains a significant challenge. Caching inherently involves duplicating data, optimizing its storage, and ensuring updates when source data changes. Despite these complexities, caching is indispensable in almost every data engineering solution due to its profound impact on performance. The broader historical context of data architecture, as presented by Hannes Mühleisen, shows that while cloud servers were added, the fundamental architecture from 1985 to 2015 didn't change drastically, but with more powerful clients, there's a shift towards client-side and smaller data processing.
Key Insights: Positioning, Metadata Management, and Freshness
Crucial aspects of effective caching include cache positioning. A semantic layer, for instance, resides between the data warehouse and the customer, but a web application might have another cache layer preceding it. Determining the optimal placement for a cache is always a key consideration.
Equally important is querying data efficiently. This necessitates robust metadata detailing data storage, indices, partitions, table widths, and row counts. In traditional databases, this is declaratively managed via SQL and a sophisticated query planner. Every database includes a query planner that interprets SQL queries, leveraging existing metadata to find the fastest execution path, avoiding full table scans or other performance traps that could significantly increase response times.
This is, in essence, metadata management. A query planner also uses statistics from indices to address one of caching's biggest challenges: data freshness (or staleness). It determines whether statistics are reliable enough to avoid a full table scan or if the data is outdated, requiring a complete re-read. Strategies to manage this include Time To Live (TTL), cache invalidation patterns, and incremental materialization. Hot/Warm/Cold data tiering, which moves data between storage tiers based on access patterns and cost optimization, is another common approach.
DuckDB and DuckLake: Modern Caching Options
DuckDB introduces a new array of caching possibilities. As mentioned, DuckDB WASM enables in-browser caching. Furthermore, DuckDB's fast query engine (for CSV, Parquet, etc.) can store data directly or query data stored on S3 or other locations via extensions.
A significant new feature is the ability to easily add an additional storage location for a cache. This is configurable and convenient, as querying remains transparent, requiring minimal management beyond specifying a cache storage location. With DuckLake, even more advanced options become available.
Overcoming Obstacles in Cache Implementation
Implementing a cache effectively presents inherent challenges: ensuring data is always up-to-date, avoiding outdated or inconsistent information when querying the cache instead of the source. For example, Cube's journey with their custom Cube Store cache initially used Redis but quickly hit limitations, leading to a Rust-based implementation leveraging Apache Arrow.
Fortunately, DuckDB's ecosystem offers open-source implementations that simplify this process. Extensions like QuackStore and DuckDB Diskcache provide maximal convenience for adding a cache, especially for SQL interfaces. If you use SQL (or DuckDB) to query remote data (e.g., S3, other databases), these extensions can provide out-of-the-box caching benefits.
The objective is to achieve the simplicity of a database with the speed of a cache. Let's explore some examples.
How It Works: Practical Examples
This section examines four DuckDB caching extensions: QuackStore by Coginiti, cache_httpfs from the community, DiskCache by Peter Boncz (CWI), and an in-process columnar caching implementation by Striim.
QuackStore
QuackStore enhances data query speed by caching remote files locally. This extension utilizes block-based caching to automatically store frequently accessed file portions, significantly reducing load times for repeated queries on the same data.
How it Works:
First, install and load the extension:
INSTALL quackstore FROM community;
LOAD quackstore;
Next, set the path for cache storage (a file system location) using the GLOBAL command:
SET GLOBAL quackstore_cache_path = '/tmp/my_duckdb_cache.bin';
SET GLOBAL quackstore_cache_enabled = true;
To demonstrate, a timer was used to count rows on a public dataset:
.timer on
-- Slow on first try (cold)
SELECT COUNT(*) FROM read_csv('https://noaa-ghcn-pds.s3.amazonaws.com/csv.gz/by_year/2025.csv.gz');
The initial run without cache took 49.366 seconds, returning:
count_star()
------------
26016543
Run Time (s): real 49.366 user 51.777825 sys 0.449690
The second run, leveraging the cache, completed in 3.304 seconds:
count_star()
------------
26016543
Run Time (s): real 3.304 user 7.630344 sys 0.237343
For this 26 million-row dataset, the cache size was 116 MB. A SUMMARIZE query, which typically takes a while to read metadata and counts, also returned much faster:
SUMMARIZE FROM read_csv('quackstore://https://noaa-ghcn-pds.s3.amazonaws.com/csv.gz/by_year/2025.csv.gz');
This specific query, even on its first run, was faster at 4.100 seconds, despite not being cached itself yet.
QuackStore also allows caching files from remote servers like GitHub or S3:
-- Cache a CSV file from GitHub
SELECT * FROM 'quackstore://https://raw.githubusercontent.com/owner/repo/main/data.csv';
-- Cache a single Parquet file from S3
SELECT * FROM parquet_scan('quackstore://s3://example_bucket/data/file.parquet');
-- Cache entire Iceberg catalog from S3
SELECT * FROM iceberg_scan('quackstore://s3://example_bucket/iceberg/catalog');
-- Cache any web resource
SELECT content FROM read_text('quackstore://https://example.com/file.txt');
Note: Peter Boncz's duckdb-diskcache repository does not currently offer a working community extension or clear installation instructions, appearing more experimental. The cache_httpfs extension (by dentiny) is the actively maintained community alternative.
cache_httpfs (DiskCache for Remote Files)
The cache_httpfs extension integrates a local disk cache layer on top of DuckDB's httpfs extension. When querying remote files from S3, HTTP, or Hugging Face, it automatically caches data blocks locally. This reduces bandwidth costs, improves latency, and enhances reliability, especially with unstable connections.
How it Works:
Install and load the extension:
INSTALL cache_httpfs FROM community;
LOAD cache_httpfs;
The extension transparently wraps httpfs, meaning existing S3/HTTP queries benefit from caching without any code modifications. By default, it uses on-disk caching with sensible default settings.
Example: Querying S3 with Caching
-- First query: downloads from S3
SELECT COUNT(*) FROM read_csv('https://noaa-ghcn-pds.s3.amazonaws.com/csv.gz/by_year/2025.csv.gz');
-- Run Time: 42.407s (example)
-- Configure cache location (optional - sensible defaults are provided)
SET cache_httpfs_cache_directory = '/tmp/duckdb_cache';
-- Second query: data might be partially cached locally depending on access patterns
SELECT COUNT(*) FROM 's3://my-bucket/large-dataset/*.parquet';
-- Run Time: 44.028s (example)
-- Third query: served primarily from local disk cache
SELECT COUNT(*) FROM 's3://my-bucket/large-dataset/*.parquet';
-- Run Time: 1.995s (example)
You can monitor cache behavior and statistics:
Check cache hit/miss ratio:
SELECT cache_httpfs_get_profile();
Output:
┌────────────────────────────┐
│ cache_httpfs_get_profile() │
│ varchar │
├────────────────────────────┤
│ (noop profile collector) │
└────────────────────────────┘
See current cache size on disk:
SELECT cache_httpfs_get_ondisk_data_cache_size();
Output:
┌───────────────────────────────────────────┐
│ cache_httpfs_get_ondisk_data_cache_size() │
│ int64 │
├───────────────────────────────────────────┤
│ 131048289 │
│ (131.05 million) │
└───────────────────────────────────────────┘
Clear the cache if needed:
SELECT cache_httpfs_clear_cache();
Output:
┌────────────────────────────┐
│ cache_httpfs_clear_cache() │
│ boolean │
├────────────────────────────┤
│ true │
└────────────────────────────┘
The extension supports three cache modes via SET cache_httpfs_type:
on_disk(default): Persists cache locally, surviving restarts.in_mem: Fast, but cache is lost when DuckDB closes.noop: Disables caching entirely.
What Gets Cached:
Beyond raw data blocks, cache_httpfs also caches:
- File metadata: Avoids repeated HEAD requests.
- Glob results: Speeds up pattern matching (e.g.,
s3://bucket/*.parquet). - File handles: Reduces connection overhead.
This is particularly effective for Data Lake patterns (Iceberg, Delta, DuckLake) where Parquet files are immutable, allowing the cache to be trusted indefinitely.
DiskCache
DiskCache is a DuckDB extension that extends DuckDB's built-in RAM cache with a local disk (SSD) caching layer. DuckDB already caches remote Parquet data in RAM via its ExternalFileCache. DiskCache adds a secondary disk layer, so when RAM capacity is reached, data spills to SSD instead of requiring a new network fetch.
Note: No easy way to install yet
DiskCache currently requires building from source and is more research-oriented. It may become a community extension in the future; keep an eye on the repository for updates.
How it Works:
By default, DiskCache primarily caches files accessed through Data Lakes (Iceberg, Delta, DuckLake) where Parquet files are immutable. For other remote files, caching can be enabled using URL regex patterns:
-- Configure cache with regex to match NYC taxi data
FROM diskcache_config('/tmp/diskcache', 8192, 24, '.*d37ci6vzurychx.cloudfront.net.*');
-- First query: downloads ~450MB of parquet files
SELECT COUNT(*) FROM read_parquet([
'https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2024-01.parquet',
'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-01.parquet',
'https://d37ci6vzurychx.cloudfront.net/trip-data/green_tripdata_2024-01.parquet'
]);
-- Second query: served from disk cache
SELECT COUNT(*) FROM read_parquet([...]);
-- Inspect cache contents
FROM diskcache_stats();
In-Process Columnar Caching with DuckDB by Striim
Striim demonstrated an excellent example of how to go Beyond Materialized Views using DuckDB for in-process columnar caching. They opted against PostgreSQL materialized views for their use case due to a high volume of dynamic queries, necessitating imperative languages for cache maintenance logic. Additionally, PostgreSQL MVs presented infrastructure overhead and limited flexibility, speeding up complex queries but requiring manual refreshes and lacking incremental updates for frequent data changes.
A key advantage for Striim was the ability to control cache maintenance logic using Python with DuckDB. DuckDB runs embedded within their control plane, refreshing static data (users, tenants) daily and dynamic metrics every minute. PostgreSQL remains the source of truth for writes, while DuckDB efficiently handles all analytical reads.
On modest hardware (4 vCPUs, 7GB RAM), Striim showcased a 5–10x speedup with zero additional infrastructure costs:
| Metric | Before | After |
|---|---|---|
| Throughput | 3.95 tasks/sec | 11.71 tasks/sec |
| Execution Time | ~4 sec | ~0.8 sec |
| Latency | — | 0.19–0.2 sec |
As John Kutay notes in the above article, this isn't true HTAP (Hybrid Transactional/Analytical Processing) due to a lack of real-time consistency between systems. However, for operational analytics where slight data staleness is acceptable, it offers a pragmatic middle ground: pluggable OLAP performance without the typical complexity.
Can We Replace Redis? Exploring Immutable DataLakes
Redis is commonly used as a key-value store cache for fast data access. Could DuckDB serve as a replacement?
For immutable data (frozen data), solutions like DiskCache could potentially replace Redis. While benchmarks would be needed for direct speed comparison, from a functional and simplicity perspective, it offers a pragmatic solution.
This concept can be extended with an immutable DuckLake, termed a Frozen DuckLake: a read-only, serverless data lake with minimal moving parts. It consists simply of a DuckDB file on cloud storage, incurring near-zero cost overhead. With no servers, refresh jobs, or cache invalidation mechanisms, because the data never changes, it simplifies operations significantly.
This pattern is particularly well-suited for caching historical reference data (e.g., past fiscal years, archived reports), lookup tables that rarely update, or snapshots for auditing and compliance. In this scenario, the cache effectively becomes the database, or rather, the database serves as the cache.
Other Caching Approaches
Beyond these, numerous other caching examples exist. Apache Arrow can be used for an in-memory cache, though this requires custom application logic. Alternatively, pg_duckdb enables running an HTAP (Hybrid Transactional/Analytical Processing) database directly on top of an OLTP (Online Transaction Processing) source database, potentially eliminating the need for ETL and data duplication.
For an out-of-the-box, managed cloud solution, MotherDuck offers server-side caching that "just works." It seamlessly integrates with the DuckDB examples discussed, allowing easy switching from local to cloud operations by simply changing your local path to md:.
Wrapping Up
Caching remains an indispensable tool in a data engineer's toolkit, particularly in imperfect data architectures where rapid results are needed for common queries. This article has shown how DuckDB and its ecosystem provide a remarkably simple path to high performance, requiring minimal configuration, no separate ingestion pipelines, and no new systems to maintain.
QuackStore and DiskCache implement transparent read-through caching. The concept of a Frozen DuckLake elegantly sidesteps the notoriously difficult problem of cache invalidation by embracing immutability—no TTL strategies to tune, no stale data to worry about. Sometimes, the most effective cache pattern is a set of well-defined principles or a simple extension easily installed via DuckDB's community extensions. This can reduce query times from minutes to seconds, making dashboards responsive again.
A broader insight is that the pendulum of caching strategies has come full circle. From early data warehouses and OLAP cubes, through materialized views and semantic layers, we've arrived at a surprisingly simple notion: the database as the cache. With DuckDB's fast readers, WASM support for browser-based analytics, and patterns like Frozen DuckLake for immutable reference data, we can often bypass the complexity of traditional cache infrastructure. Metadata management, query planning, and freshness strategies are inherently included when using an actual database as our cache, delivered in a lightweight and portable binary format.
For those seeking a solution that works effortlessly without wrestling with cache invalidation or spinning up additional infrastructure, MotherDuck provides fast, out-of-the-box server-side caching. Simply replace your local path with md: to leverage cloud-based performance benefits.
Explore these options to discover how straightforward high-performance analytics can truly be. Read more in the Docs.