Elasticsearch vs. Meilisearch: A Comprehensive Review for 2025
Compare Elasticsearch and Meilisearch to determine the best search solution for your needs. This review covers their architecture, features, scalability, and operational complexity, helping developers choose between enterprise-grade power and developer-friendly simplicity for optimal search implementation in 2025.

Elasticsearch has long been a dominant force in enterprise search and analytics, serving over 18,000 customers globally for applications ranging from website search to log analysis. Its distributed architecture and extensive features, covering search, analytics, machine learning, and security, make it a preferred choice for organizations managing vast datasets and intricate requirements.
This comprehensive review offers an in-depth analysis of Elasticsearch, identifying it as an ideal solution for specific scenarios:
- Managing billions of documents across distributed clusters.
- Requiring advanced analytics and machine learning capabilities.
- Possessing dedicated DevOps resources for cluster management.
- Having use cases that encompass search, security, and observability.
- Needing enterprise-grade reliability and support.
Conversely, Elasticsearch may not be the optimal choice for organizations that:
- Seek an out-of-the-box search solution.
- Prefer minimal operational overhead.
- Work with datasets in the millions rather than billions of documents.
- Aim to avoid the complexities inherent in distributed systems.
- Require flexible pricing options with predictable costs.
For these situations, Meilisearch presents a compelling alternative. This modern search engine is founded on the principle that effective search should not demand extensive knowledge of distributed systems. It boasts lightning-fast performance, an intuitive API, and minimal configuration, delivering enterprise-quality search results in under 50 milliseconds. It is designed to be simple enough for a single developer to implement rapidly.
This article will later provide a detailed examination of Meilisearch, positioning it as an excellent alternative for teams prioritizing simplicity without compromising search quality. Those interested in a more streamlined search solution can explore Meilisearch Cloud with a 14-day free trial or deploy its open-source version at no cost.
What is Elasticsearch?
Elasticsearch is a distributed search and analytics engine built on Apache Lucene, first released in February 2010. Its origins trace back to 2004 when Shay Banon created a recipe search application named Compass. Recognizing the demand for a more scalable and user-friendly search solution, Banon completely redeveloped Compass, leading to the creation of Elasticsearch.
The platform has since evolved from a pure search engine into a comprehensive data platform. As the core component of the Elastic Stack (formerly ELK Stack), it integrates seamlessly with Kibana for visualization, and Logstash and Beats for data ingestion, forming a complete ecosystem for search-powered solutions. In 2012, Shay Banon co-founded Elastic to offer commercial products and services centered around Elasticsearch.
Today, Elastic is positioned as a "search AI company," with Elasticsearch primarily serving three use cases: Enterprise Search (for workplace and application search), Observability (for log analytics and monitoring), and Security (for threat detection and response). Its typical customer base includes large enterprises, organizations with complex data requirements, teams needing to analyze petabytes of data, and businesses requiring unified search, analytics, and security functionalities.
Elasticsearch: Advantages & Disadvantages
| Advantages | Disadvantages |
|---|---|
| Massively scalable distributed architecture | Complex cluster management, requiring specialized expertise |
| Comprehensive analytics and aggregation capabilities | Steep learning curve for advanced features |
| Rich ecosystem with Kibana, Logstash, and Beats | Resource-intensive, particularly in terms of memory |
| Powerful machine learning and AI features | Managed cloud offering is limited to a 14-day trial |
| Enterprise-grade security and reliability | Often an over-engineered solution for straightforward search needs |
Elasticsearch Review: Mechanics & Core Features
Distributed Architecture and Scalability
Elasticsearch's distributed design is a cornerstone of its functionality. Data is structured into indices, which are then segmented into shards. These shards can be distributed across numerous nodes within a cluster. To ensure high availability and data redundancy, each shard can have replica shards, safeguarding against node failures. This architectural approach enables Elasticsearch to scale horizontally by simply integrating additional nodes into the cluster.
The cluster autonomously manages data distribution and rebalances shards as nodes are added or removed.
A typical production cluster comprises master nodes for cluster management, data nodes for storing and searching data, and ingest nodes for pre-processing documents. This clear separation of concerns facilitates optimization tailored to specific workload characteristics. Organizations can commence with a modest number of nodes and seamlessly expand to hundreds, managing petabytes of information across thousands of indices as their data volumes grow.
Search and Analytics Capabilities
At its core, Elasticsearch offers sophisticated search capabilities via its Query DSL (Domain Specific Language), a JSON-based language designed for constructing intricate queries.
The platform supports numerous query types, ranging from basic match queries to advanced geo-spatial searches. During indexing, documents undergo analysis using customizable analyzers that manage tokenization, stemming, and synonym expansion.
The powerful aggregations framework facilitates real-time analytics on stored data. Users can compute various metrics, such as averages and sums, create buckets for data grouping by terms or date ranges, and construct pipeline aggregations that operate on the output of other aggregations. This framework supports diverse use cases, from straightforward counting to complex statistical analysis.
Time series analysis features include date histogram aggregations for trend tracking and downsampling to summarize historical data, optimizing storage. Integrated machine learning features provide anomaly detection for identifying unusual patterns in time-series data, outlier detection, and classification/regression for predictive analytics. In 2022, Elasticsearch introduced vector search capabilities to support semantic search and Natural Language Processing tasks.
Elastic Stack Integration
Elasticsearch significantly enhances its capabilities through seamless integration with other Elastic Stack components.
Kibana serves as the visualization layer, offering interactive dashboards, the Discover tool for data exploration, Canvas for precise reports, and Lens for intuitive drag-and-drop visualization creation. It also features robust alerting capabilities and a Dev Tools console for direct API interaction.
Data ingestion is managed via multiple pathways. Beats are lightweight data shippers, encompassing Filebeat for logs, Metricbeat for metrics, Packetbeat for network data, and specialized Beats for other data types. Logstash functions as a more powerful processing pipeline, offering over 200 plugins for various inputs, filters, and outputs. The more recent Elastic Agent provides unified data collection with centralized management through Fleet.
Furthermore, the platform supports webhooks for triggering external actions and delivers comprehensive monitoring of the entire stack through its Stack Monitoring features.
Where Elasticsearch May Not Be the Best Fit
While Elasticsearch is renowned for its capabilities in enterprise-scale search and analytics, it presents certain limitations for many organizations. These constraints highlight a platform optimized for extensive functionality rather than straightforward simplicity.
Operational Complexity
Managing an Elasticsearch cluster demands considerable expertise. Administrators must grasp concepts such as shards, replicas, and node roles, undertake capacity planning and performance tuning, manage index lifecycle policies, and resolve complex issues like split-brain scenarios. Many organizations find they require dedicated Elasticsearch specialists or costly consultants, transforming a search solution into a continuous operational challenge.
Resource Demands and Costs
Elasticsearch's memory-intensive nature significantly increases infrastructure costs. The platform necessitates substantial RAM for efficient operation, with recommended resources often exceeding what smaller organizations can readily provide. Coupled with the requirement for multiple nodes in production deployments and a managed cloud service limited to a 14-day trial, the total cost of ownership can become prohibitive for teams primarily seeking robust search functionality.
Steep Learning Curve
Although basic searches are intuitive, mastering Elasticsearch demands a considerable time investment. Developers must become proficient in the Query DSL syntax, comprehend mapping and analysis concepts, understand aggregation frameworks, and navigate cluster administration. This steep learning curve can delay implementation and heighten the risk of misconfigurations impacting performance or stability.
Over-Engineering for Simpler Requirements
For applications requiring search functionality without the need for complex analytics or massive scale, Elasticsearch often introduces unnecessary complexity. The process of setting up a cluster, configuring mappings, tuning analyzers, and managing indices can feel excessive when the primary goal is simply to add search to a website or application dealing with thousands or millions of documents, not billions.
Pricing Inflexibility
Unlike modern alternatives that offer both subscription and usage-based pricing models, Elasticsearch's pricing structure can lead to unpredictable costs at scale. Organizations frequently encounter unexpected overages or find themselves paying for capacity they don't consistently utilize, complicating budget planning.

These limitations are not inherent flaws but rather a consequence of designing a platform for enterprise scale and comprehensive functionality. However, they underscore a clear demand for alternatives that prioritize developer experience and simplicity without compromising search quality.
Meilisearch: A Simpler Alternative
Meilisearch tackles the complexity challenges of Elasticsearch by presenting a search engine that emphasizes ease of use.
Founded by Quentin de Quelen, Clément Renault, and Thomas Payet, Meilisearch arose from their shared frustrations with existing search solutions while working at major e-commerce firms. They built their search engine from the ground up in Rust, concentrating on delivering a solution that is both rapid to deploy and straightforward to maintain.
Lightning-Fast, Developer-First Design
Meilisearch delivers search results in under 50 milliseconds, making it perfectly suited for 'search-as-you-type' experiences. This exceptional performance stems from its architecture, which is built entirely in Rust and leverages optimized data structures, including finite state transducers for rapid word lookups. The platform employs a Lightning Memory-Mapped Database (LMDB) for efficient storage with minimal memory overhead.
The REST-ful API is intuitive and consistent across all endpoints. Creating an index, adding documents, and executing searches requires only a few API calls, yielding clear and predictable responses. Official SDKs are provided for JavaScript, Python, Ruby, PHP, Go, Rust, Swift, and other languages, each adhering to language-specific conventions while ensuring API consistency. A web interface offers a convenient dashboard for testing searches without writing code.
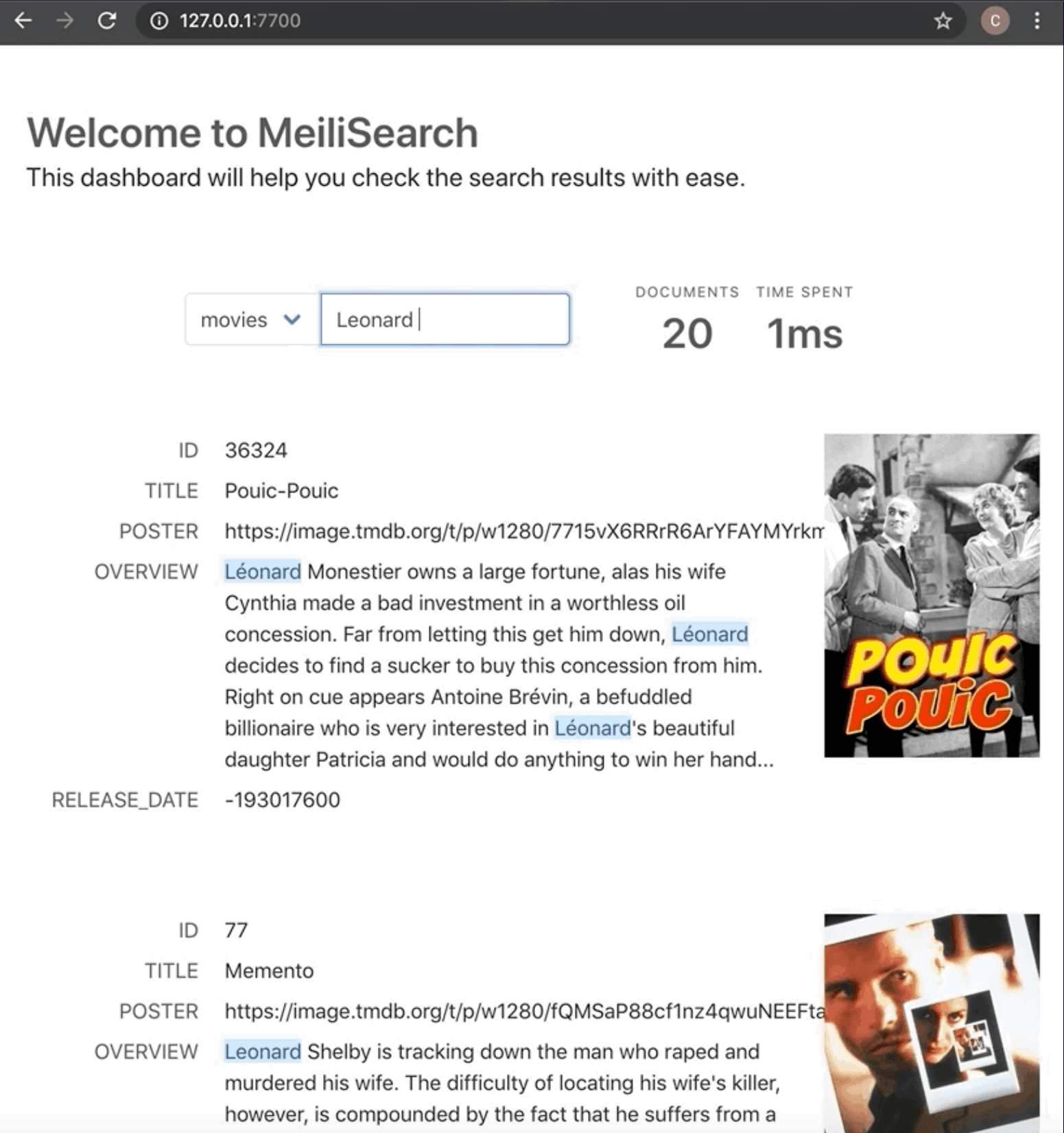
Out-of-the-Box Excellence
Meilisearch delivers highly relevant search results with minimal configuration. Its default ranking rules account for matched words, typo tolerance, term proximity, attribute importance, exactness of matches, and sort parameters. These rules are synergistically applied through a bucket sort algorithm, ensuring consistently relevant results across various datasets.
Typo tolerance is enabled by default, accommodating one typo in words of five or more characters and two typos in words of nine or more characters. This significantly enhances user experience without requiring any manual setup.

Features such as filtering, faceted search, and highlighting function immediately upon defining the relevant attributes as filterable or searchable. There is no need for complex configurations of analyzers, tokenizers, or mappings.
The platform automatically supports multiple languages through its Charabia tokenizer, including Latin, Chinese, Japanese, Korean, Thai, and Hebrew scripts. Synonyms and stop words can be easily defined using simple JSON configurations.
Modern Search Capabilities
Meilisearch has incorporated AI-powered search capabilities to remain competitive with leading enterprise platforms. Its hybrid search feature intelligently combines traditional keyword matching with semantic vector search, ensuring contextually relevant results even when exact keywords are not present. The platform offers straightforward integration with OpenAI, Hugging Face, and custom embedding providers via simple configuration.
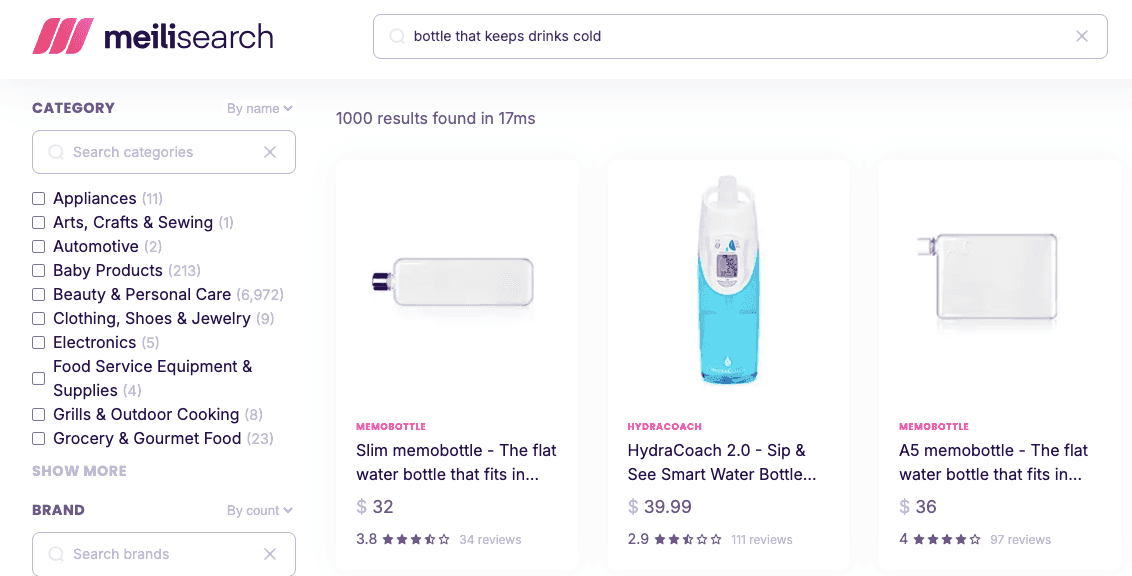
Vector search facilitates a semantic understanding of queries, enabling the retrieval of documents based on their meaning rather than merely keywords. Document templates assist in generating superior embeddings by supplying additional context to AI models. The semanticRatio parameter allows for granular control over result relevance by fine-tuning the balance between keyword and semantic search outcomes.
Geosearch capabilities permit filtering and sorting results by geographic location using the _geoRadius filter. Multi-index search supports querying across multiple indexes in a single request, yielding federated results. Furthermore, tenant tokens provide secure, multi-tenant search functionality, ensuring users only access authorized documents.
Accessible Pricing and Deployment
Meilisearch is open-source under the MIT license, permitting free use, modification, and distribution. Self-hosting is simplified through Docker images, cloud marketplace offerings, and comprehensive deployment guides for platforms like DigitalOcean, AWS, and Kubernetes. A standalone binary can be downloaded and executed without dependencies, enabling search functionality within seconds.
Meilisearch Cloud provides managed hosting with a 14-day free trial, with plans starting at $30/month for 100,000 documents and 50,000 searches. The Pro plan, priced at $300/month, includes 1 million documents and 250,000 searches, along with priority support. A key differentiator for Meilisearch is its dual pricing model: users can opt for subscription-based plans for predictable monthly costs or resource-based pricing that scales with actual usage. This flexibility ensures users only pay for what they need, circumventing unexpected overages often associated with single-model pricing. The self-managed open-source version remains perpetually free, although it offers fewer features than the Cloud offering.
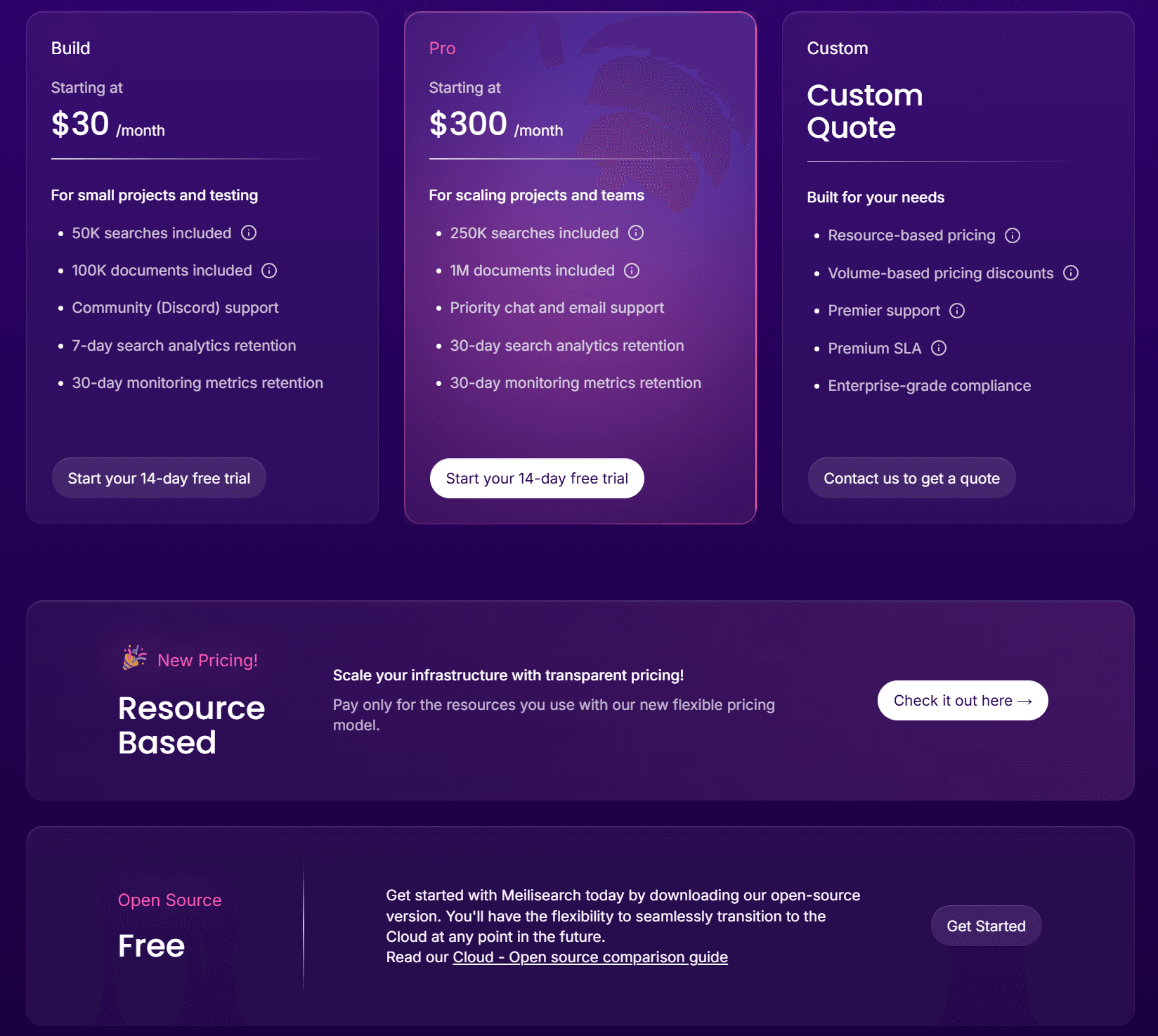
Infrastructure requirements for Meilisearch are minimal; it operates efficiently on a single server, making it a cost-effective choice for most use cases. Memory usage is optimized via LMDB, generally requiring less RAM than Elasticsearch for comparable datasets, as indicated by community benchmarks.
Elasticsearch vs. Meilisearch: Comparison Summary
| Aspect | Elasticsearch | Meilisearch |
|---|---|---|
| Architecture | Distributed, multi-node clusters | Single-node (Community); experimental sharding (Enterprise) |
| Setup Complexity | Requires significant planning and configuration | Works efficiently out-of-the-box |
| Learning Curve | Demands significant time investment | Quick to learn and implement |
| Maximum Scale | Billions of documents | Billions of documents (4.3 billion max per index) |
| Feature Depth | Comprehensive analytics, machine learning, security | Focused on core search excellence |
| Resource Needs | High memory and CPU requirements | Efficient, lightweight operation |
| Free Options | 14-day cloud trial; self-managed open-source | 14-day cloud trial; full open-source version |
| Pricing Flexibility | Single pricing model | Dual model: subscription or resource-based |
| Best For | Enterprise-scale with complex data and analytical needs | Rapid, simple search implementation with high relevance |
Final Verdict
The decision between Elasticsearch and Meilisearch hinges on your organization's specific complexity requirements and available resources.
Choose Elasticsearch if you are developing enterprise-scale systems that demand functionalities beyond basic search. It represents a suitable investment when your needs encompass diverse domains such as security analytics, log aggregation, and machine learning, and when you possess the technical expertise to manage distributed systems. The platform's extensive capabilities and maturity are invaluable for organizations where search is an integral component of a broader data strategy.
Choose Meilisearch if you seek outstanding search performance without the burden of extensive operational overhead. It is an ideal choice for teams that need to deploy search features rapidly, prioritize developer productivity, and favor solutions that perform excellently with minimal configuration. The blend of fast performance, intuitive APIs, modern AI capabilities, and flexible pricing options makes it perfect for applications where search quality is paramount but complexity is undesirable. Its dual pricing model particularly benefits organizations seeking cost predictability as they scale.
Both platforms effectively cater to their intended audiences. Elasticsearch provides the robust infrastructure for intricate, data-intensive operations at scale, while Meilisearch fulfills the promise that exceptional search should be both simple to implement and user-friendly.