Elevating DeepSeek LLM Inference: vLLM Reaches 2.2k tok/s/H200 with Wide-EP Optimizations
Explore vLLM's V1 engine advancements, enabling high-throughput DeepSeek model serving at 2.2k tokens/s/H200. This article details Wide-EP, Dual-Batch Overlap, and Expert Parallel Load Balancing for optimized LLM inference.
Introduction
vLLM has achieved a significant milestone with the complete migration to its enhanced V1 engine architecture, as of version v0.11.0. This advancement is a testament to the vibrant community of over 1,969 contributors, who delivered more than 950 commits in the preceding month. The robustness of vLLM's V1 engine is further underscored by its inclusion in the SemiAnalysis open-source InferenceMax performance benchmarks and its adoption in production environments by leading organizations such as Meta, LinkedIn, Red Hat, Mistral, and HuggingFace.
For high-performance Large Language Model (LLM) inference, DeepSeek-style disaggregated serving and sparse Mixture-of-Experts (MoE) model deployments continue to represent state-of-the-art solutions. This article details the core optimizations developed by the vLLM team to significantly boost throughput, including:
- Async scheduling
- Dual-batch overlap (DBO)
- Disaggregated serving
- CUDA graph mode
FULL_AND_PIECEWISE- DeepGEMM enabled by default
- DeepEP kernels integration
- Expert parallel load balancing
- SiLU kernel for DeepSeek-R1
For deeper insights into large-scale serving, disaggregated serving, distributed inference, and Wide-EP using vLLM, refer to the valuable resources provided by the llm-d, PyTorch, Dynamo, and Anyscale teams.
Performance Results
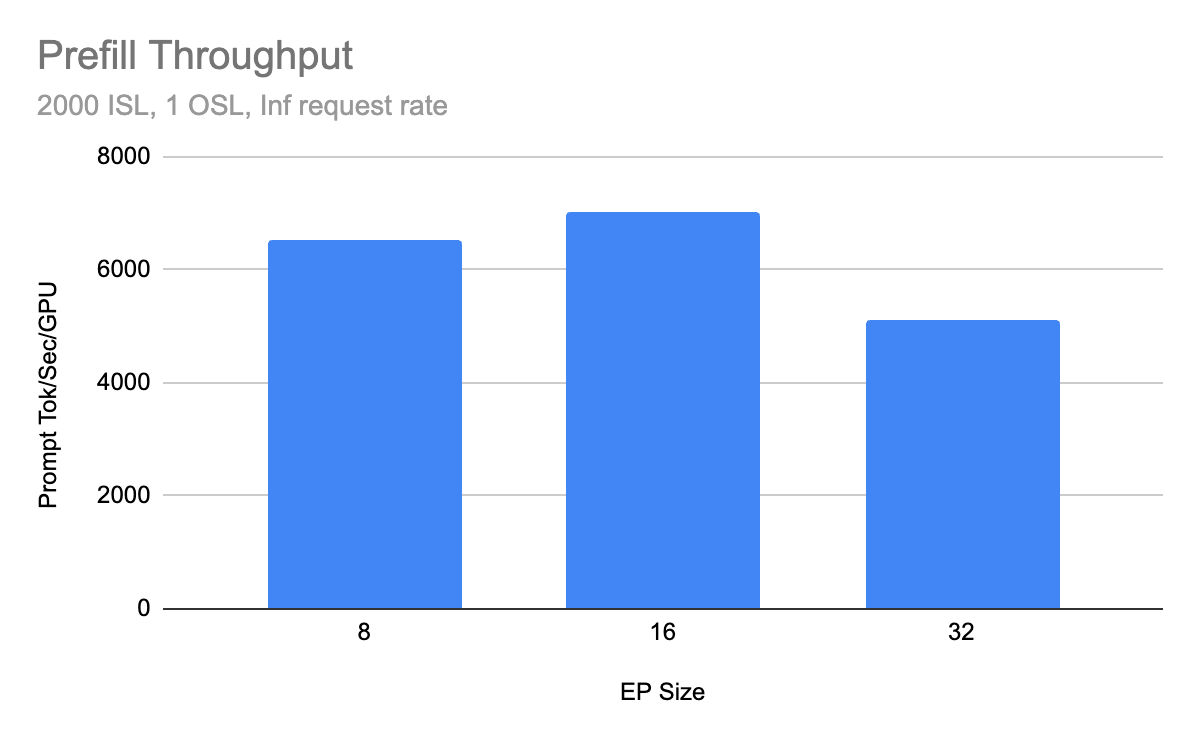
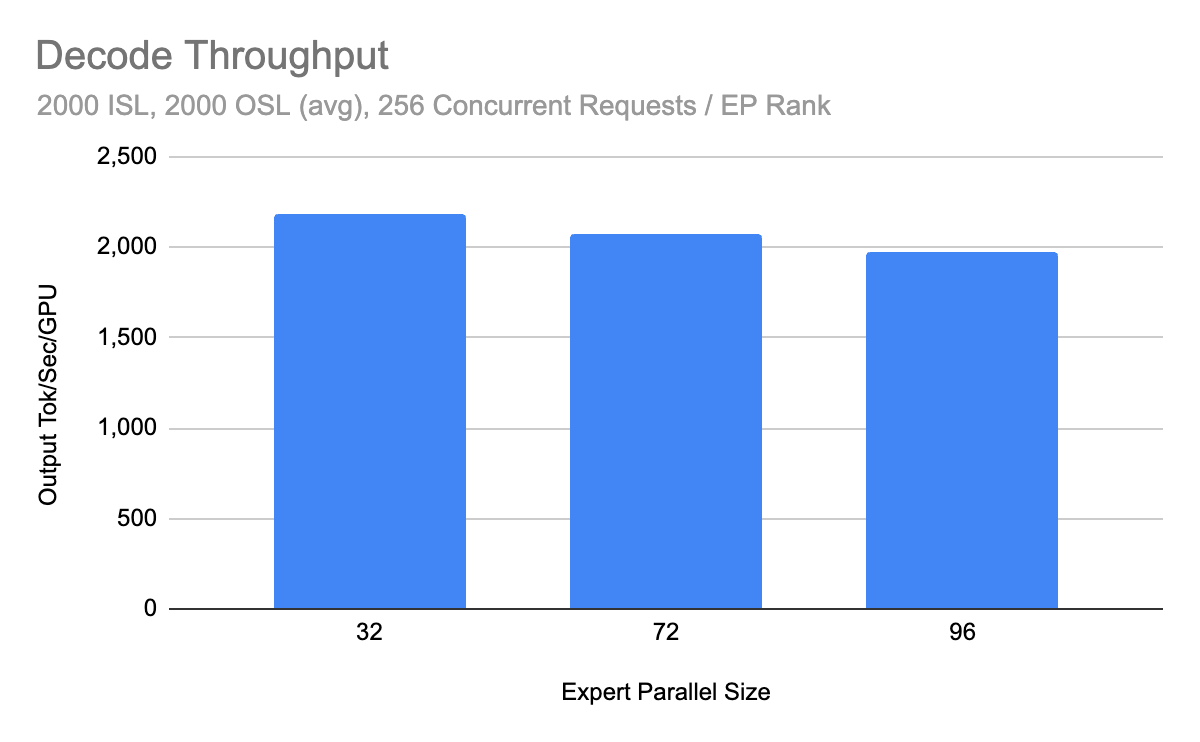
Recent community benchmarks, conducted on a Coreweave H200 cluster utilizing Infiniband with ConnectX-7 NICs, demonstrate a sustained throughput of 2.2k tokens/s per H200 GPU in multi-node, production-like deployments. This represents a substantial improvement from previous benchmarks, which recorded approximately 1.5k tokens/s per GPU.
This performance boost is attributed to continuous optimization efforts, including crucial kernel enhancements like SiLU-Mul-Quant fusion, Cutlass QKV kernels, and Tensor Parallel (TP) attention bug fixes, alongside the introduction of Dual Batch Overlap (DBO) for the decode phase. Such high performance directly benefits operators by enabling workload consolidation and reducing the number of replicas required to meet a target Queries Per Second (QPS), thereby significantly lowering the cost per token.
Prefill Throughput
Decode Throughput
Key Components
Wide-EP
Serving advanced models like the DeepSeek-V3 family at scale necessitates addressing two critical aspects:
- Sparse Expert Activation: In models such as DeepSeek-R1, only a fraction (e.g., 37B out of 671B total parameters) of the model's parameters are active during each forward pass.
- KV Cache Management: Tensor Parallel (TP) deployment is suboptimal for DeepSeek's Multi-Head Latent Attention (MLA) architecture, as latent projections are redundantly duplicated across shards.
Expert Parallelism (EP) is a deployment strategy designed to leverage these characteristics, maximizing effective KV cache utilization. vLLM supports EP via the --enable-expert-parallel flag. In this configuration, a single set of experts is distributed and shared across all ranks within a deployment. During a forward pass, tokens are dynamically routed between ranks to be processed by the appropriate expert.
 Wide-EP token routing visualization
Wide-EP token routing visualization
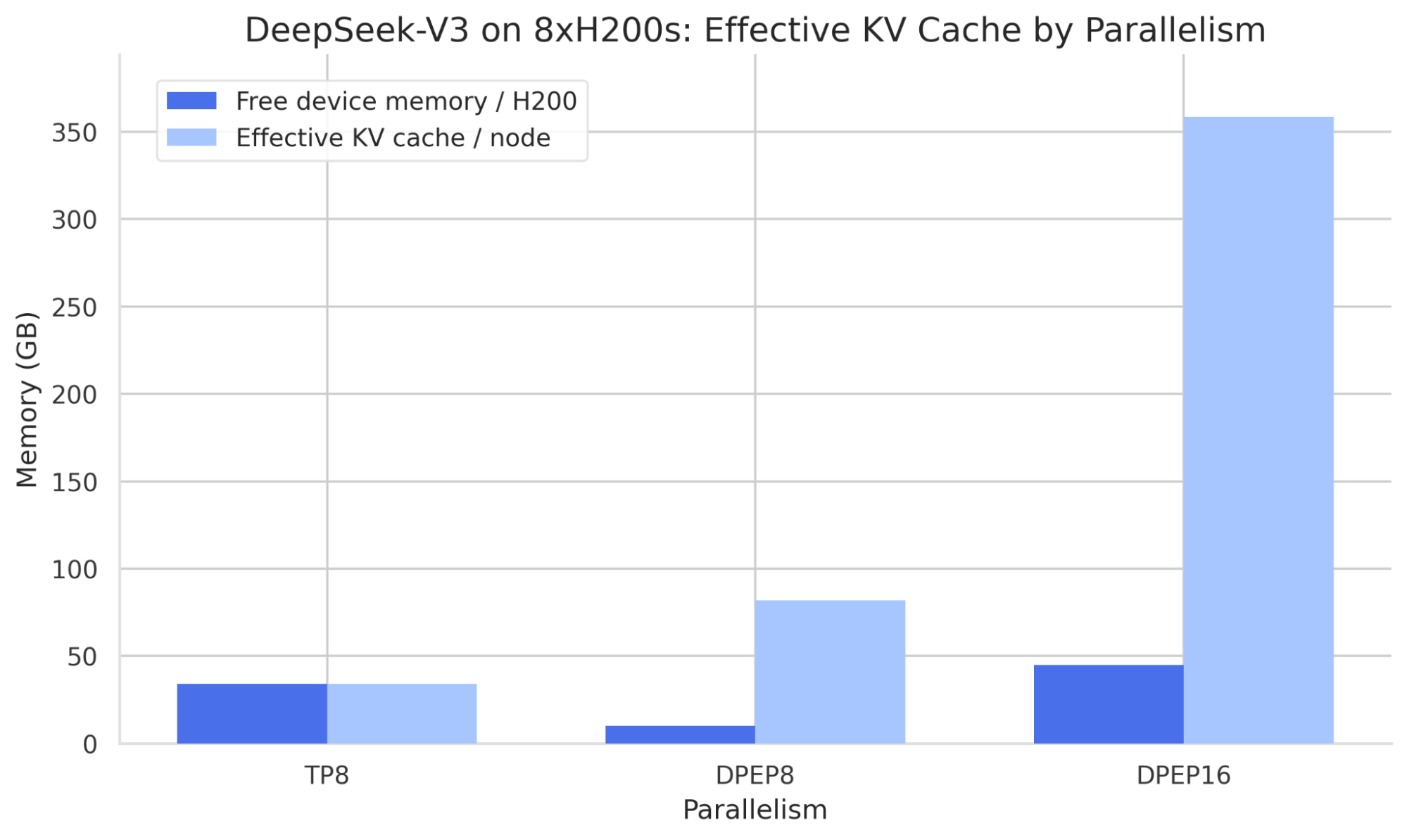
Wide-EP combines Expert Parallelism with Data Parallelism (DP). DP deployments can be initiated using either mp or ray data parallel backends, simplifying setup within a Ray cluster. The advantages of Wide-EP over traditional Tensor Parallelism are evident in memory efficiency, as illustrated by comparing GPU memory usage for DeepSeek-V3 with TP versus EP sharding strategies. While TP leaves 34GB of free device memory per H200, it duplicates latent attention projections for MLA models across ranks. Conversely, DP duplicates attention layers, ensuring latent projections are independent per rank and thereby increasing the effective batch size across the deployment.
Increasing the degree of expert parallelism can introduce higher synchronization overhead between ranks. To mitigate this, vLLM integrates support for DeepEP's high-throughput, low-latency all-to-all kernels. Additionally, vLLM supports Perplexity MoE kernels and an NCCL-based AllGather-ReduceScatter all-to-all mechanism. Comprehensive details on the available all-to-all backends in vLLM can be found in the vLLM MoE kernel documentation.
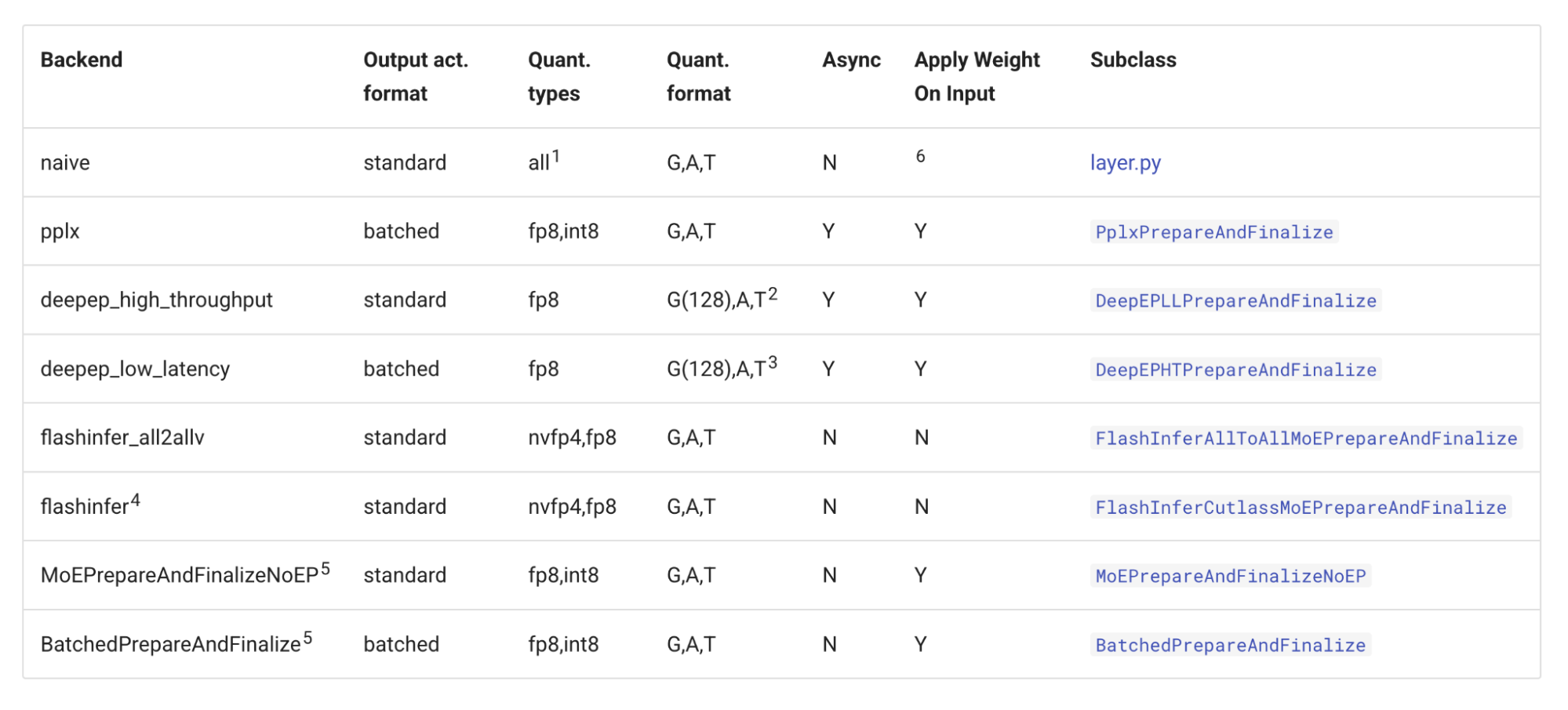 vLLM all-to-all backends overview
vLLM all-to-all backends overview
Dual-Batch Overlap (DBO)
vLLM incorporates DeepSeek's microbatching strategy, termed Dual-Batch Overlap (DBO), which can be activated using the --enable-dbo command-line flag. This strategy is designed to boost GPU utilization by intelligently overlapping compute operations with collective communication. vLLM implements DBO through the following steps:
- A collective
all_reduceoperation across ranks determines if microbatching will be advantageous, with a configurable minimum threshold via--dbo-decode-token-threshold. - The main thread spawns microbatch worker threads, which handle CUDA graph capture.
- vLLM’s modular MoE all-to-all kernel base class orchestrates the launch of these microbatch workers, relinquishing control as it awaits GPU task completion.
Observe a profiling trace from a DeepSeek decode workload without DBO. The 'MoE Dispatch/Combine' section highlights significant time spent in collective communication, disproportionate to the actual compute load.
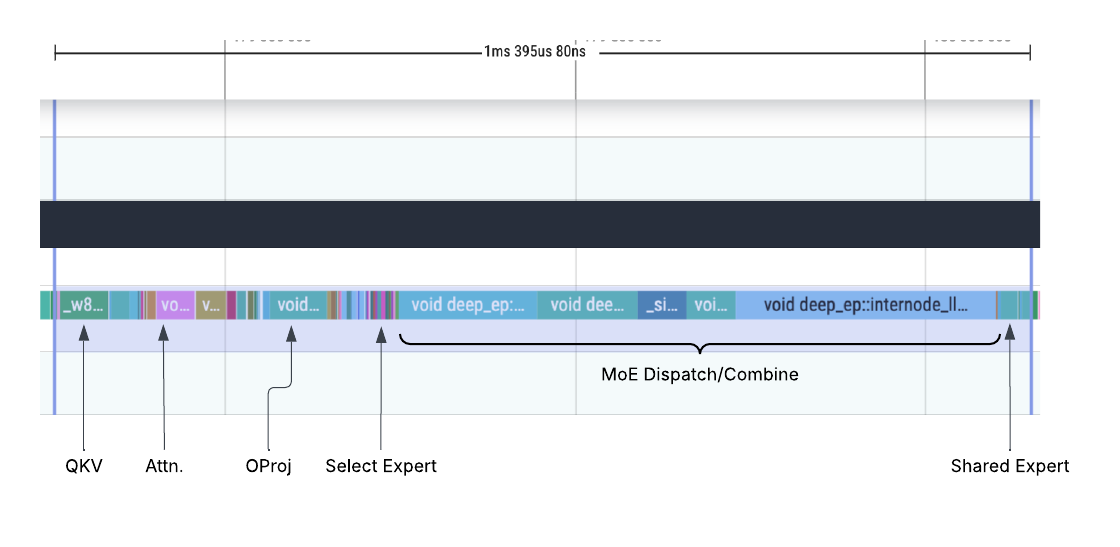 Profiling trace without DBO
Profiling trace without DBO
In contrast, the trace below illustrates the same workload with DBO enabled. The first microbatch worker thread commences and finishes MoE dispatch, then immediately passes control to the second microbatch worker. The second thread subsequently completes its dispatch and yields back to the first. Finally, the first worker finishes its combine operation before yielding back to the second microbatch worker. This dynamic results in superior GPU utilization, particularly in deployments with high communication overhead, common in scenarios with a high degree of expert parallelism.
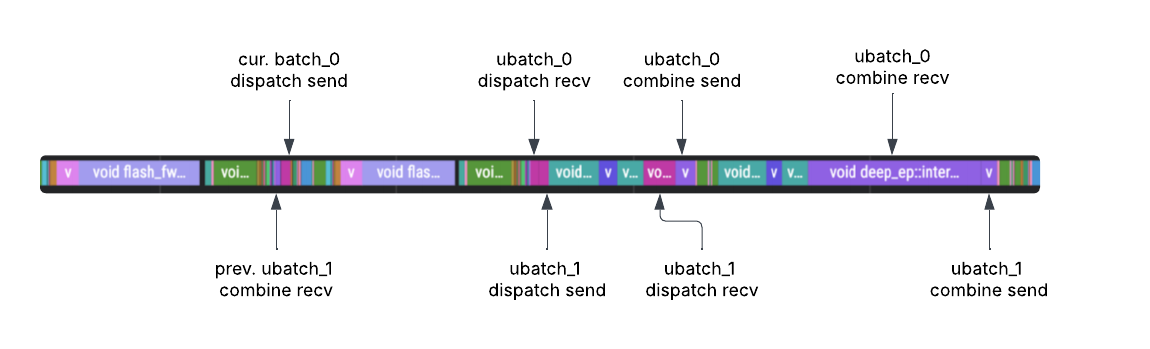 Profiling trace with DBO
Profiling trace with DBO
Expert Parallel Load Balancing (EPLB)
While Mixture-of-Experts (MoE) layers are typically optimized for balanced load distribution during training, inference workloads often lead to imbalanced token routing across experts. NVIDIA's experimental findings on MoE expert routing provide further evidence of these workload-dependent load imbalances.
Within a Wide-EP configuration, such imbalances can result in some Expert Parallel (EP) ranks remaining idle while others are burdened with processing substantial token batches. To address this, vLLM integrates the hierarchical and global load balancing policies derived from DeepSeek's Expert Parallel Load Balancer (EPLB). EPLB is managed via the --enable-eplb CLI flag, offering adjustable parameters such as window size, rebalance interval, redundant experts, and logging options.
 EPLB in action
EPLB in action
EPLB operates by recording per-token load during each MoE forward pass. A sliding window mechanism then aggregates these statistics across all EP ranks. Upon reaching the predefined rebalance interval, the load balancer calculates an optimized new logical-to-physical expert mapping and orchestrates a weight shuffle, ensuring the revised placement takes effect seamlessly without requiring a model restart.
Disaggregated Serving
The disaggregated prefill/decode serving pattern, introduced by Hao AI Lab in the 2024 DistServe paper, offers significant advantages, particularly for expert parallel deployments.
 Prefill/Decode disaggregation visualized
Prefill/Decode disaggregation visualized
Given that experts are distributed across different ranks, tokens from a single request originating on one rank might need processing by an expert residing on another rank within the EP group. This necessitates intricate synchronization between MoE layers, potentially involving dummy passes for inactive ranks, to ensure collective operations are prepared to receive tokens precisely when needed. Consequently, a single compute-bound prefill request has the potential to impede the forward pass of the entire EP group, thereby greatly accentuating the benefits of disaggregated serving. Furthermore, DeepSeek deployments can be fine-tuned to exclusively utilize the DeepEP kernel best suited for their specific workload demands, balancing between high throughput and low latency.
Deployment Paths
Several platforms provide robust pathways for deploying vLLM with Wide-EP optimizations:
llm-d
llm-d is a Kubernetes-native distributed inference serving stack designed to accelerate the deployment of large generative AI models at scale. It aims to deliver state-of-the-art performance for key open-source models across various hardware accelerators and infrastructure providers. For comprehensive guidance on replicating the Wide-EP results discussed in this article, refer to llm-d's dedicated Wide EP deployment path documentation.
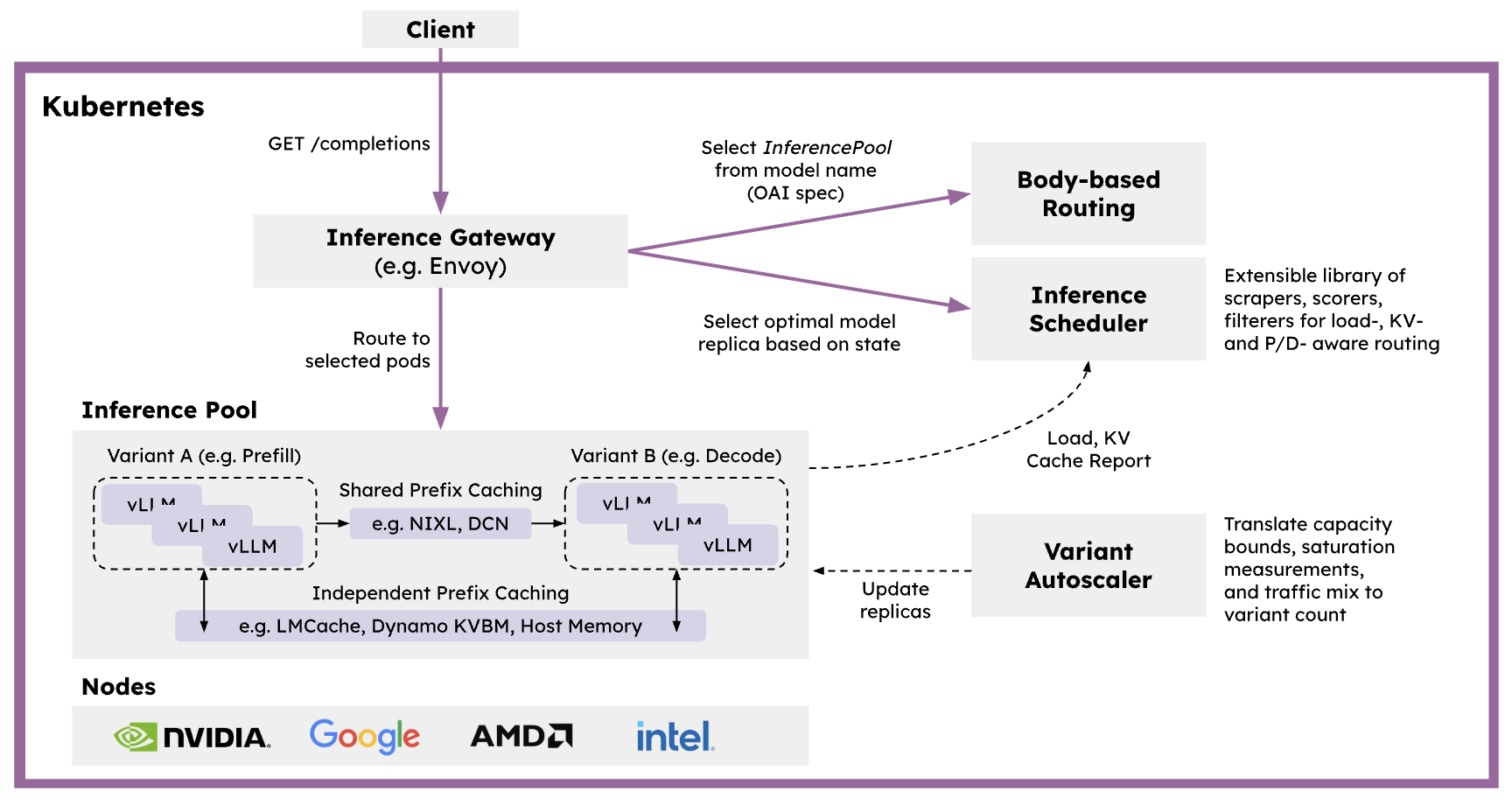
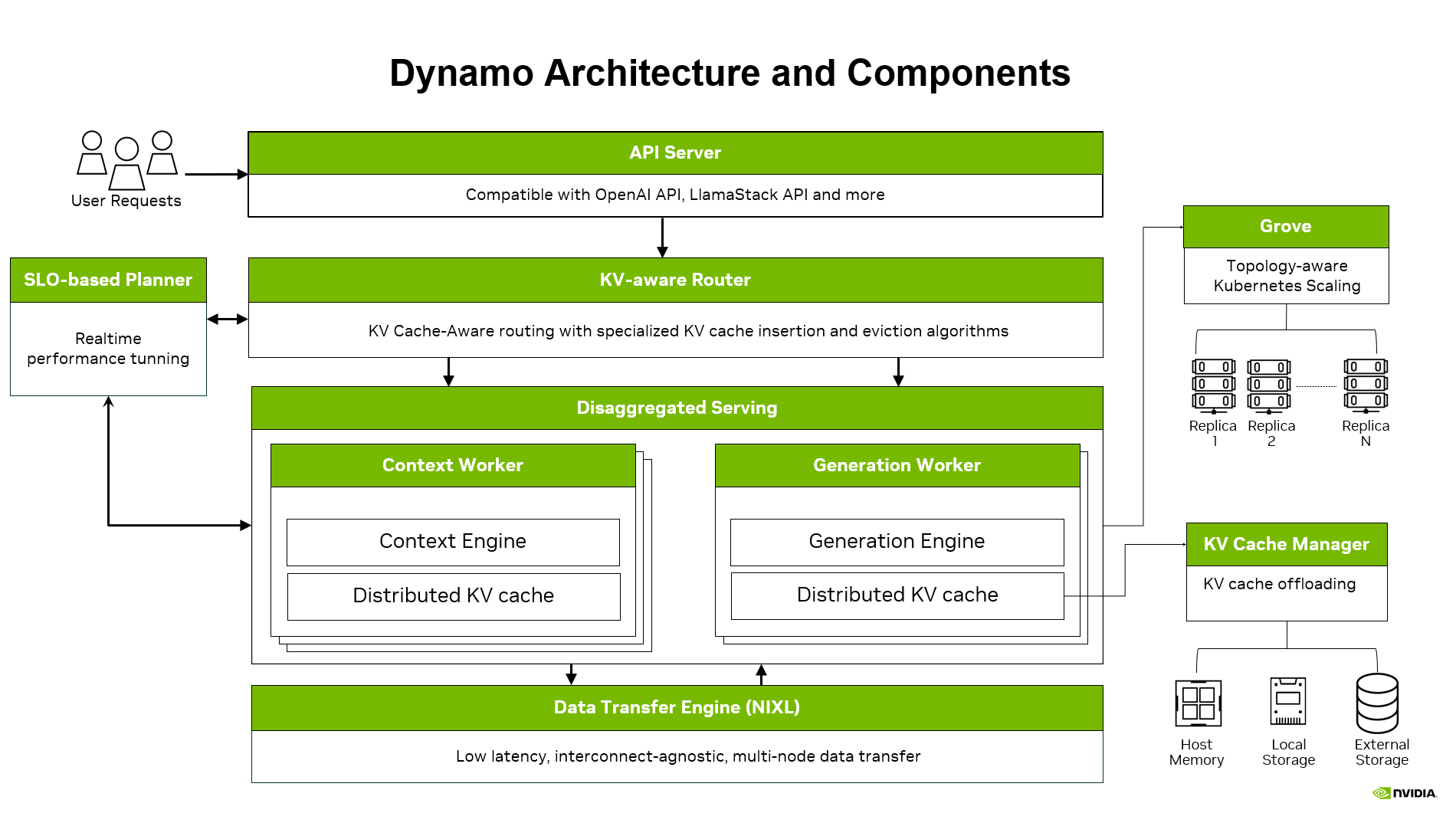
Dynamo
Dynamo is engineered for high-throughput, low-latency production deployments of LLMs. Its features, including KV-aware routing, a KV Block Manager for cache offloading, and a Planner for dynamic load matching, enable tighter Service Level Agreements (SLAs) and scalable operations across multiple GPUs. vLLM and Wide-EP serving are natively supported within Dynamo, leveraging all these advanced capabilities. Detailed information and an example recipe for reproducing the performance outlined here can be found in the Dynamo documentation.
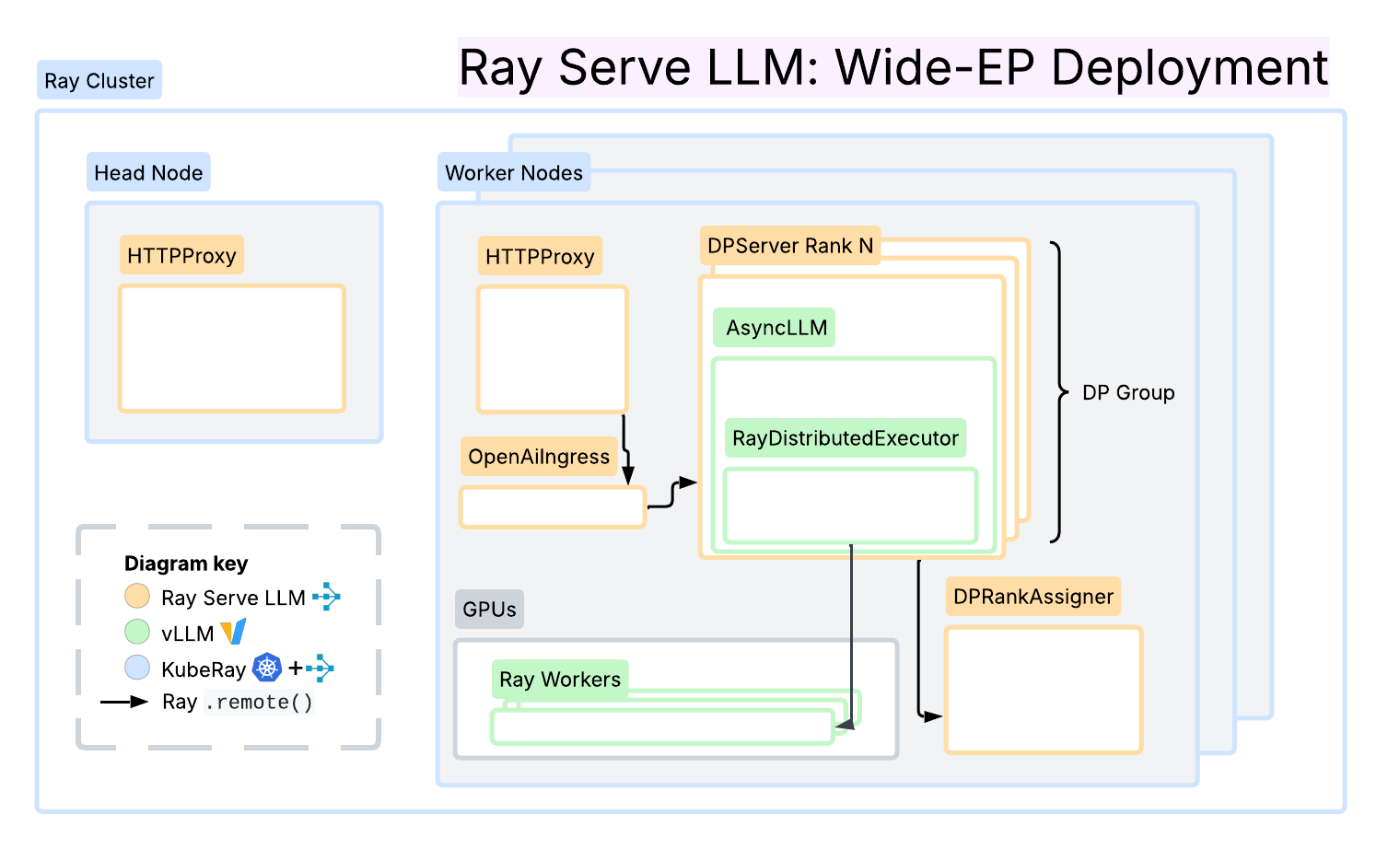
Ray Serve LLM
Built upon Ray Serve primitives, Ray Serve LLM offers first-class serving patterns for prefill/decode disaggregation, data parallel attention, and prefix cache-affinity request routing. It emphasizes modularity and ease of deployment on Ray clusters, including KubeRay on Kubernetes. A key advantage is its seamless integration with the broader Ray ecosystem, encompassing data processing and reinforcement learning (RL).
This framework integrates with NIXL and LMCache connectors for efficient KV cache transfer and utilizes Ray’s distributed computing primitives to enable independent autoscaling for each inference phase based on workload characteristics. Collectively, Ray Serve LLM provides a flexible and programmable layer for inference workloads, easily extensible and composable to support diverse serving patterns.
Roadmap
vLLM is under continuous development, with ongoing efforts focused on further enhancements:
- Elastic expert parallelism
- Long context serving capabilities
- KV cache transfer via CPU
- Achieving full determinism and batch invariance
- Extensive Mixture-of-Experts (MoE) optimizations, including op fusion for DeepSeek-R1 and GPT-OSS models
- Improved FlashInfer integration for the latest kernels, such as SwapAB
- Support for independent Tensor Parallel (TP) sizes in disaggregated serving deployments
- Optimizations for large-scale serving on GB200 hardware
For the most current information regarding vLLM's future directions, please consult the official roadmap at roadmap.vllm.ai.
Conclusion
vLLM has successfully transitioned to its V1 engine, delivering exceptional throughput for DeepSeek-style Mixture-of-Experts (MoE) deployments, achieving an impressive 2.2k tokens/s/H200 with Wide-EP. This advanced framework leverages Wide-EP to significantly enhance KV cache efficiency for Multi-Head Latent Attention (MLA) architectures, while Dual-Batch Overlap (DBO) and Expert Parallel Load Balancing (EPLB) effectively mitigate communication bottlenecks and address load imbalances.
Furthermore, disaggregated prefill/decode serving patterns provide additional optimizations for MoE workloads. Operators have a variety of robust deployment options available, including llm-d, Dynamo, and Ray Serve LLM, to harness these performance gains.