Generating Realistic Voice with Maya1: A State-of-the-Art TTS Model
Explore Maya1, a 3-billion-parameter Text-to-Speech (TTS) model engineered to reproduce genuine human emotion. This tutorial covers its technical foundation, broad market applications, and practical implementation, including setting up a DigitalOcean GPU Droplet for optimal performance.
This tutorial introduces Maya1, a trending open-source text-to-speech (TTS) model.

Introduction
Maya1 has recently been trending on HuggingFace.
Similar to other advanced voice models like Dia, Sesame-CSM, and Chatterbox, Maya1 is specifically engineered to accurately reproduce genuine human emotion and allows for precise, detailed control over voice characteristics.
Maya1 and other leading voice models address a critical market where voice quality matters. Game developers can generate character voices with dynamic emotional range without needing voice actors. Podcasters and audiobook producers can achieve consistent, expressive narration across hours of content. AI assistants become more natural when they can respond with appropriate emotional cues. Content creators can produce compelling voiceovers for platforms like YouTube and TikTok. Customer service teams can deploy bots that sound genuinely empathetic, and accessibility tools can finally get the engaging, natural voices they've always needed.
Maya1, developed by Maya Research, a small team of two, employs a 3-billion-parameter Llama-style transformer. It predicts SNAC neural codec tokens, enabling compact yet high-quality audio generation.
Its training foundation consists of pretraining on an internet-scale English speech corpus, followed by fine-tuning on a proprietary dataset of studio recordings. This dataset encompasses multi-accent English, over 20 emotion tags per sample, and various character and role variations.
Key Takeaways
- State-of-the-Art TTS Model: Maya1 is a 3-billion-parameter Text-to-Speech (TTS) model designed to accurately reproduce genuine human emotion and offer precise, detailed control over voice characteristics.
- Technical Foundation: It utilizes a Llama-style transformer to predict SNAC neural codec tokens, enabling compact, high-quality audio generation at a 24kHz sample rate. Its training includes an internet-scale English corpus and a proprietary dataset encompassing multi-accent English and over 20 emotion tags.
- Broad Market Applications: Maya1 is valuable in industries where voice quality and emotional authenticity are critical, such as game development, podcasting/audiobooks, AI assistants, content creation, and customer service bots.
- Implementation Requirements: Running the 3B-parameter model effectively requires a GPU with a minimum of 16GB VRAM.
Implementation
For quick testing, you can access the model on HuggingFace Spaces.
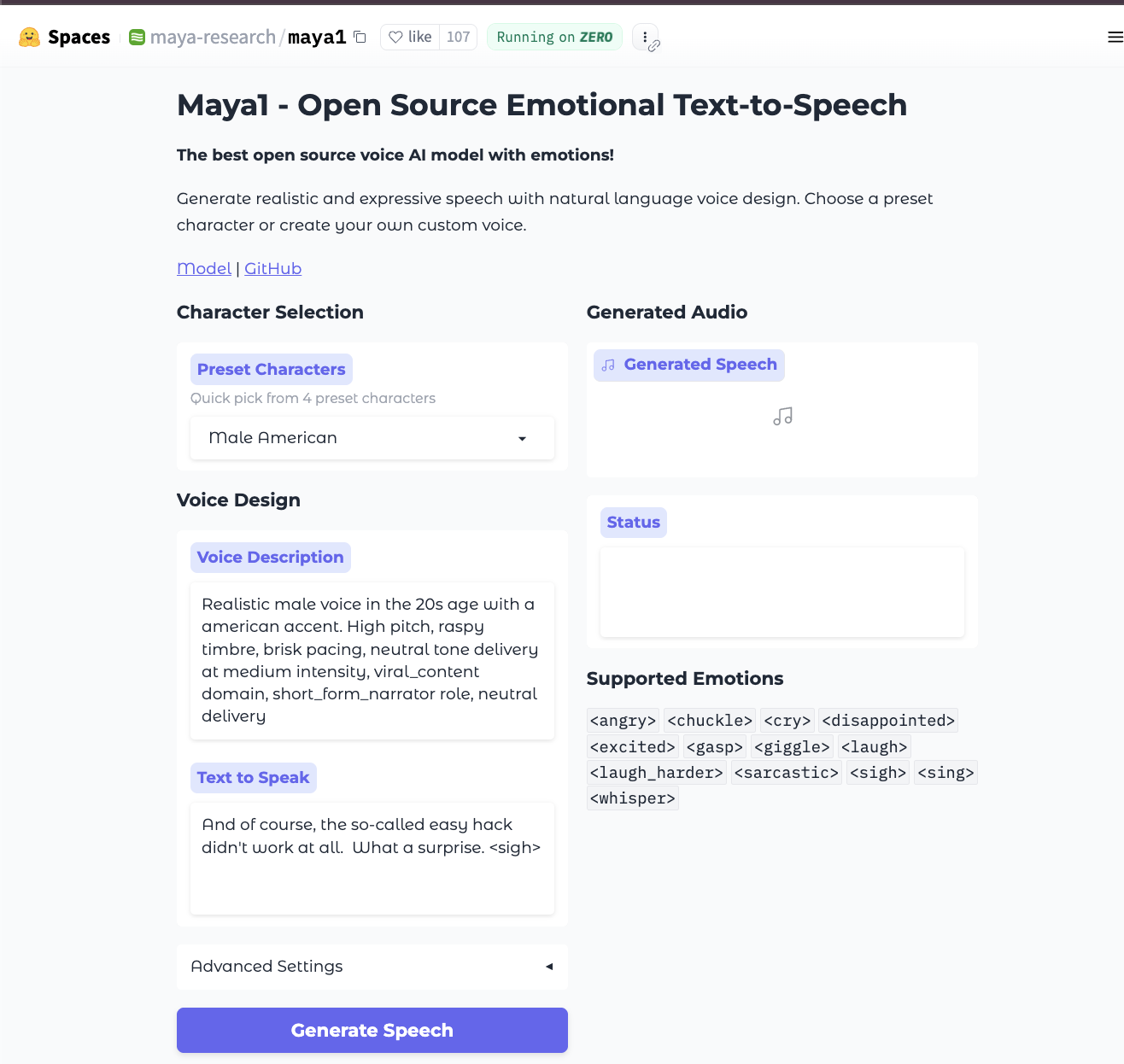
To run this 3B-parameter model at a reasonable speed, a GPU is essential. You'll also need to install the necessary libraries, including the specific audio codec SNAC.
Step 0: Set up a GPU Droplet
Begin by setting up a DigitalOcean GPU Droplet. Select the inference-optimized image. Given that 16GB VRAM is the baseline for running Maya1 effectively, your GPU options are flexible.
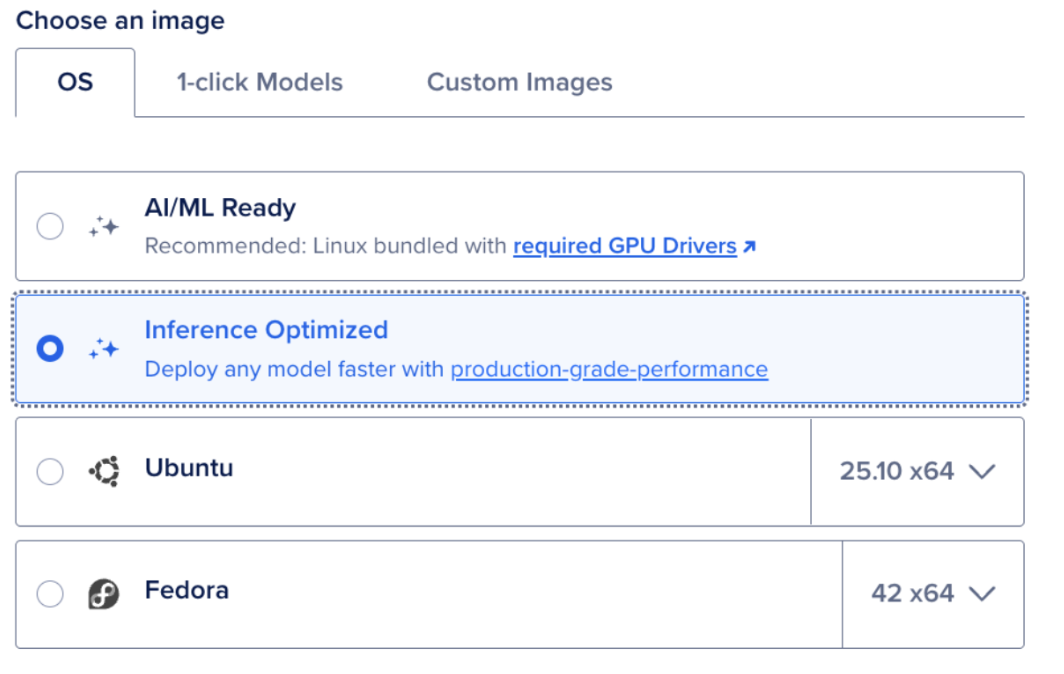
Running the model is straightforward. After SSHing into your Droplet, execute the following commands in your terminal:
-
Install
python3 -m venv venv source venv/bin/activate pip install -r requirements.txt -
Configure
# Create .env file echo "MAYA1_MODEL_PATH=maya-research/maya1" > .env echo "HF_TOKEN=your_token_here" >> .env # Login to HuggingFace huggingface-cli login -
Start Server
./server.sh start # Server runs on http://localhost:8000 -
Generate Speech
curl -X POST "http://localhost:8000/v1/tts/generate" \ -H "Content-Type: application/json" \ -d '{ "description": "Male voice in their 30s with american accent", "text": "Hello world <excited> this is amazing!", "stream": false }' \\ --output output.wav
FAQ
What is Maya1?
Maya1 is a State-of-the-Art (SOTA), 3-billion-parameter Text-to-Speech (TTS) model developed by Maya Research. It is specifically engineered to generate speech with genuine human emotion and allows for precise control over voice characteristics.
What technology does Maya1 use?
Maya1 employs a Llama-style transformer architecture to predict SNAC neural codec tokens. This enables compact, high-quality audio generation at a 24kHz sample rate.
What are the key features of Maya1’s training data?
The model was initially pretrained on an internet-scale English speech corpus and then fine-tuned on a proprietary dataset. This fine-tuning dataset includes multi-accent English, over 20 emotion tags per sample, and various character and role variations.
Where can I test Maya1 without setting up my own server?
You can quickly test the model on the official HuggingFace Space by maya-research.
What are the common potential use cases for Maya1?
Maya1 is ideal for applications where voice quality and emotional authenticity are critical, including:
- Game character voice generation with dynamic emotional range.
- Podcasting and audiobook narration.
- Creating natural and empathetic AI assistants or customer service bots.
- Producing compelling voiceovers for content creators (YouTube, TikTok).
Final Thoughts
This tutorial introduced you to Maya1, a new and trending open-source text-to-speech (TTS) model, and guided you through its implementation. We encourage you to experiment with Maya1 and share your experiences regarding its performance compared to other voice models for your specific use cases.
References and Additional Resources
- maya-research/maya1 · Hugging Face
- GitHub - MayaResearch/maya1-fastapi
- Maya1 - a Hugging Face Space by maya-research
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.