Goodbye Microservices: Consolidating 100+ Services into a Single Superstar System
Twilio Segment's journey from complex microservices to a streamlined monolithic system, addressing operational challenges and significantly boosting developer productivity.
Microservices, a service-oriented software architecture, constructs server-side applications by combining numerous single-purpose, low-footprint network services. Its touted benefits include improved modularity, reduced testing burdens, better functional composition, environmental isolation, and development team autonomy. This contrasts with a monolithic architecture, where extensive functionality resides in a single service, tested, deployed, and scaled as a unified entity.
Twilio Segment initially adopted microservices as a best practice, which proved beneficial in some scenarios but problematic in others. A core piece of Twilio Segment's product eventually reached a tipping point, where microservices hindered progress rather than accelerated it. The small team became bogged down by escalating complexity, transforming the architecture's inherent advantages into liabilities. This led to a sharp decline in velocity and a surge in defects. Ultimately, three full-time engineers found themselves primarily occupied with maintaining system stability, necessitating a strategic re-evaluation of their approach.
Why Microservices Initially Worked
Twilio Segment's customer data infrastructure processes hundreds of thousands of events per second, forwarding them to partner APIs, known as server-side destinations. With over a hundred types of these destinations, including Google Analytics, Optimizely, or custom webhooks, the initial architecture was straightforward:
An API ingested events and directed them to a distributed message queue. An 'event' is a JSON object from a web or mobile app, detailing user actions. A sample payload looks like this:
{
"event": "User Signed Up",
"userId": "97980cfea0067",
"properties": {
"plan": "premium",
"referrer": "www.google.com"
},
"traits": {
"name": "John Doe",
"email": "john.doe@example.com",
"dob": "1990-01-01"
},
"timestamp": "2018-07-09T22:38:00.000Z"
}
As events were consumed from the queue, customer-managed settings dictated which destinations should receive them. The event was then sent sequentially to each destination's API. This streamlined process meant developers only needed to send events to Twilio Segment's API, rather than integrating potentially dozens of external services. Twilio Segment managed requests to all destination endpoints.
If a request to a destination failed, a retry mechanism was employed for errors deemed 'retry-able,' such as HTTP 500s, rate limits, or timeouts. Non-retry-able errors, like invalid credentials or missing fields, were not retried.
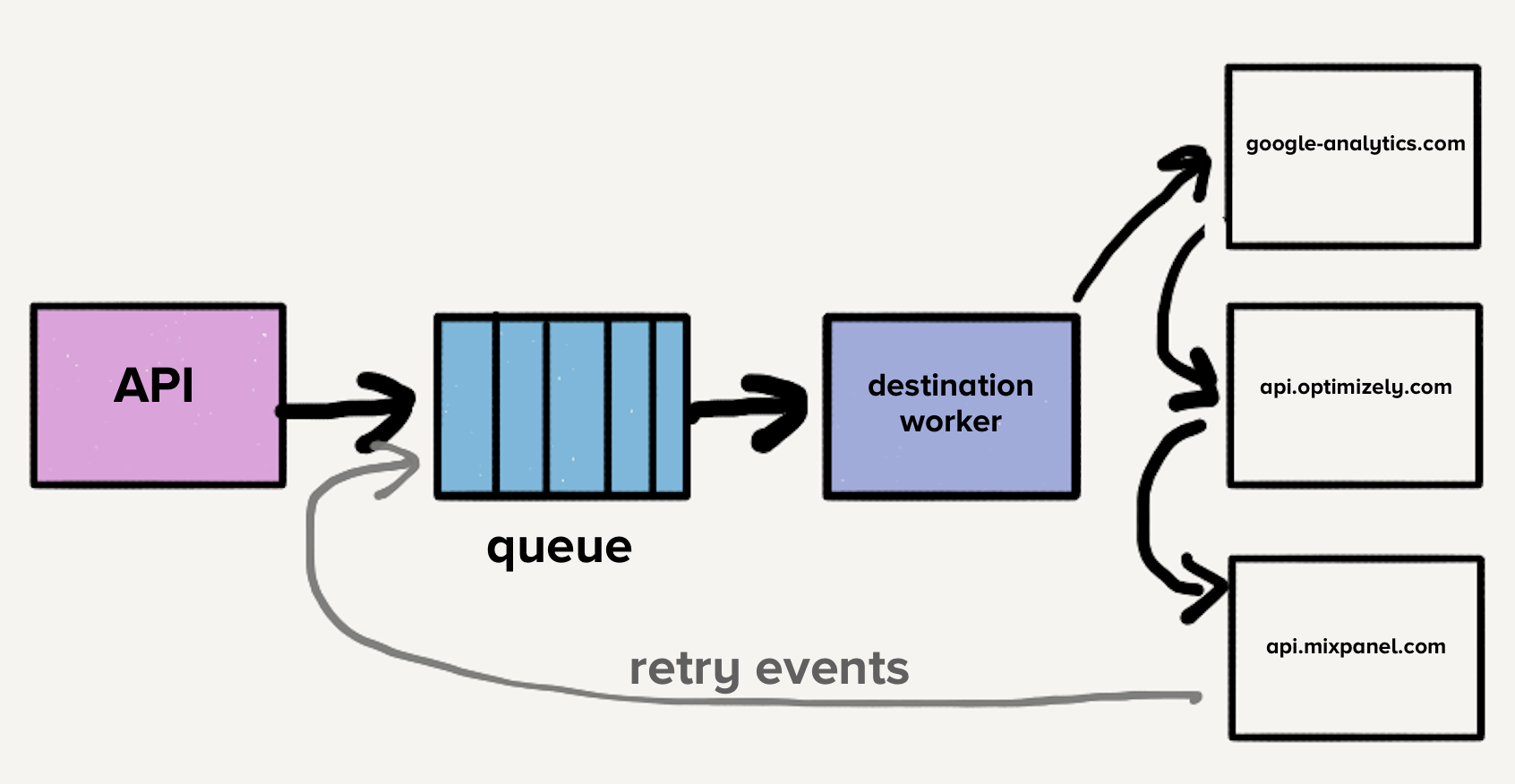
Initially, a single queue contained both new events and those with multiple retry attempts across all destinations. This led to head-of-line blocking: if one destination slowed or failed, retries would inundate the queue, causing delays across all destinations.
Consider destination X experiencing a temporary timeout issue. This not only created a backlog for destination X but also pushed every failed event back into the retry queue. While systems scaled automatically, the sudden increase in queue depth often outpaced scaling capabilities, delaying new events for all destinations. Given the critical importance of timely delivery, such increases in wait times were unacceptable.
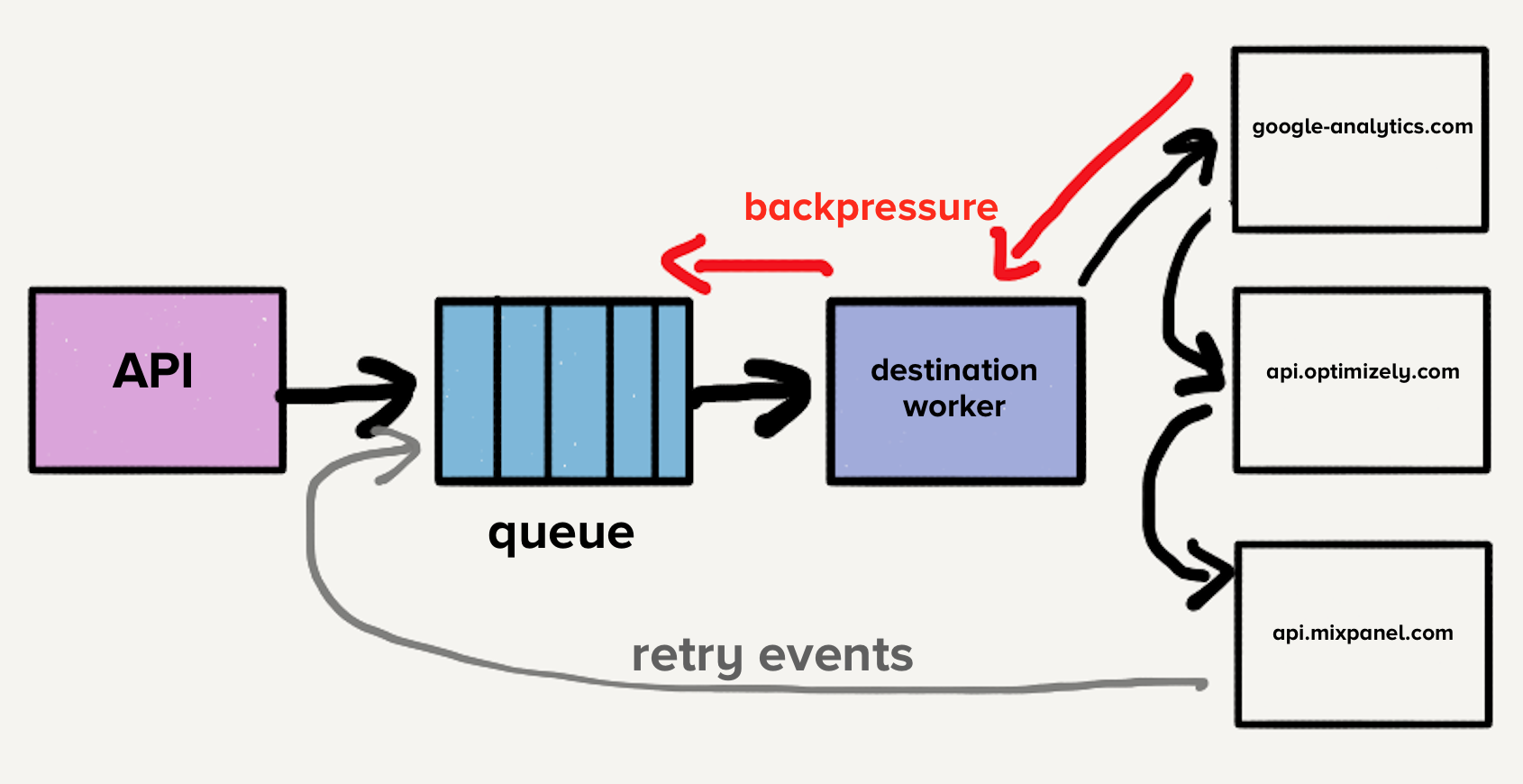
To mitigate head-of-line blocking, the team introduced a separate service and queue for each destination. This microservice-style architecture incorporated an additional router that received inbound events and distributed copies to selected destinations. Consequently, problems with one destination would only affect its dedicated queue, preventing broader system impact. This isolation was vital, as destination issues were common.
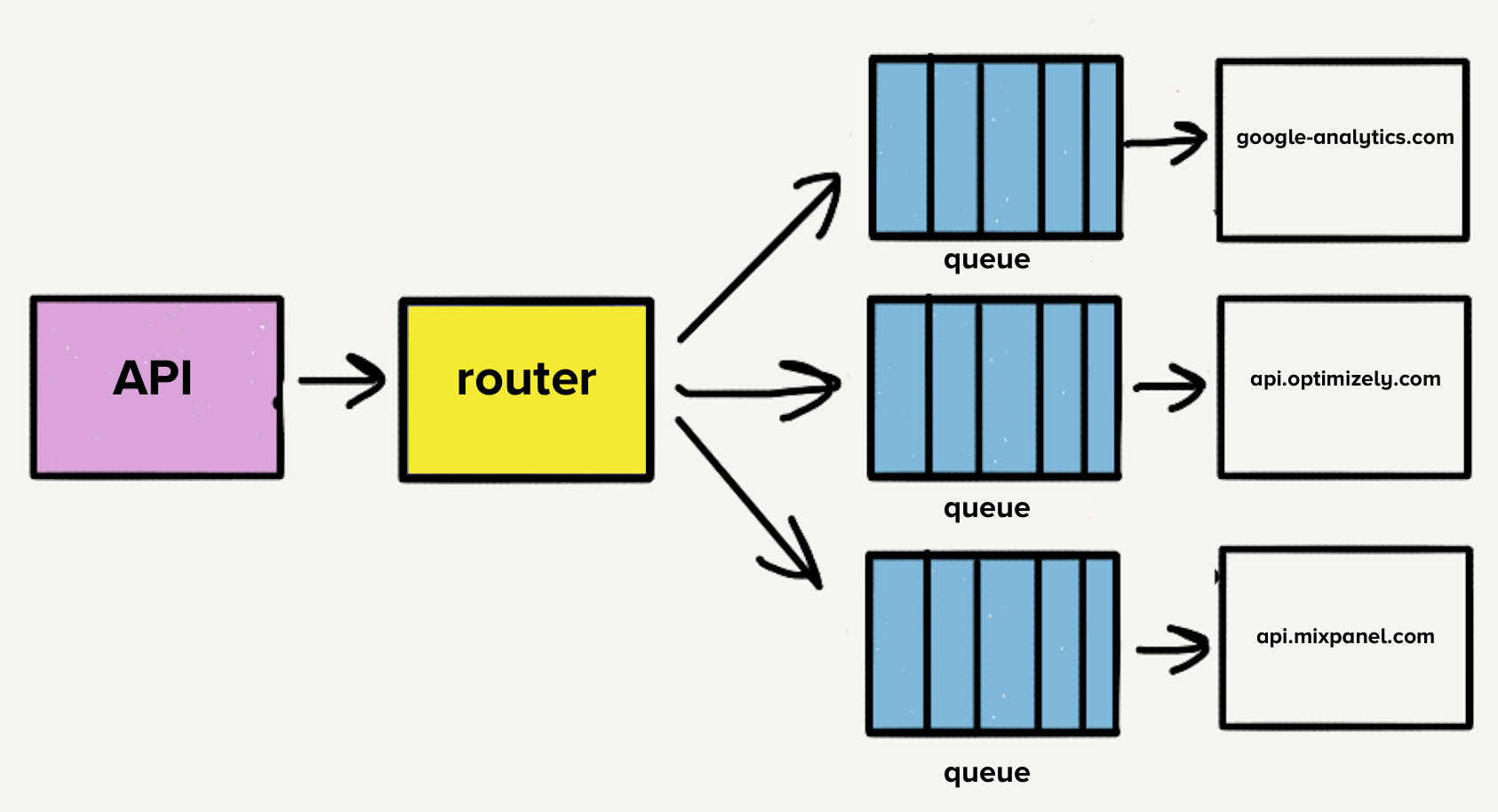
The Case for Individual Repositories
Each destination API required custom code to translate events into its specific request format. For example, if a destination required 'birthday' as traits.dob while Twilio Segment's API used traits.birthday, a transformation like this was needed:
// Example transformation for destination X
if (event.traits.birthday) {
event.traits.dob = event.traits.birthday;
delete event.traits.birthday;
}
While many modern endpoints adopt Twilio Segment's format, some older or more complex destinations necessitate intricate transformations, occasionally even involving hand-crafted XML payloads.
Initially, all destination code resided in a single repository, even after services were separated. A significant pain point was that a single broken test could halt deployments across all destinations. This led to wasted time fixing unrelated test failures. To address this, the team decided to break out each destination's code into its own repository, a natural progression given the existing service separation. This move successfully isolated destination-specific test suites, accelerating development team velocity for maintenance tasks.
Scaling Microservices and Repositories
Over time, adding over 50 new destinations translated into 50 new repositories. To streamline development and maintenance, shared libraries were created for common transformations and functionalities, such as HTTP request handling, promoting uniformity and ease of use across destinations. For instance, event.name() could retrieve a user's name from an event, abstracting various property keys like name, Name, firstName, first_name, and FirstName.
These shared libraries expedited new destination development and simplified maintenance through consistent functionality. However, a new challenge emerged: testing and deploying changes to shared libraries impacted all destinations, demanding considerable time and effort. The risk associated with updating libraries, knowing it would involve testing and deploying dozens of services, often led engineers to only update specific destination codebases. This resulted in a fragmentation of shared library versions across different destination codebases, reversing the initial benefit of reduced customization. While automation tools could have addressed this, developer productivity was already suffering, alongside other microservice-related issues.
Each service also exhibited distinct load patterns, with some handling a few events daily and others thousands per second. Destinations with low event volumes often required manual scaling during unexpected spikes, despite auto-scaling being in place. Tuning auto-scaling configurations was complex due to the unique CPU and memory requirements of each service. With an average of three new destinations added monthly, the operational overhead—more repos, queues, and services—increased linearly. This prompted a comprehensive re-evaluation of the entire pipeline.
Ditching Microservices and Queues
The immediate goal was to consolidate the 140+ services into a single service. The operational burden of managing so many services was substantial, often resulting in on-call engineers being paged for load spikes. However, the existing architecture, with a separate queue per destination, would have made a single service challenging, requiring each worker to check every queue for tasks, adding undesirable complexity. This spurred the creation of Centrifuge (now the backend infrastructure for Connections), designed to replace all individual queues and route events to the new monolithic service.
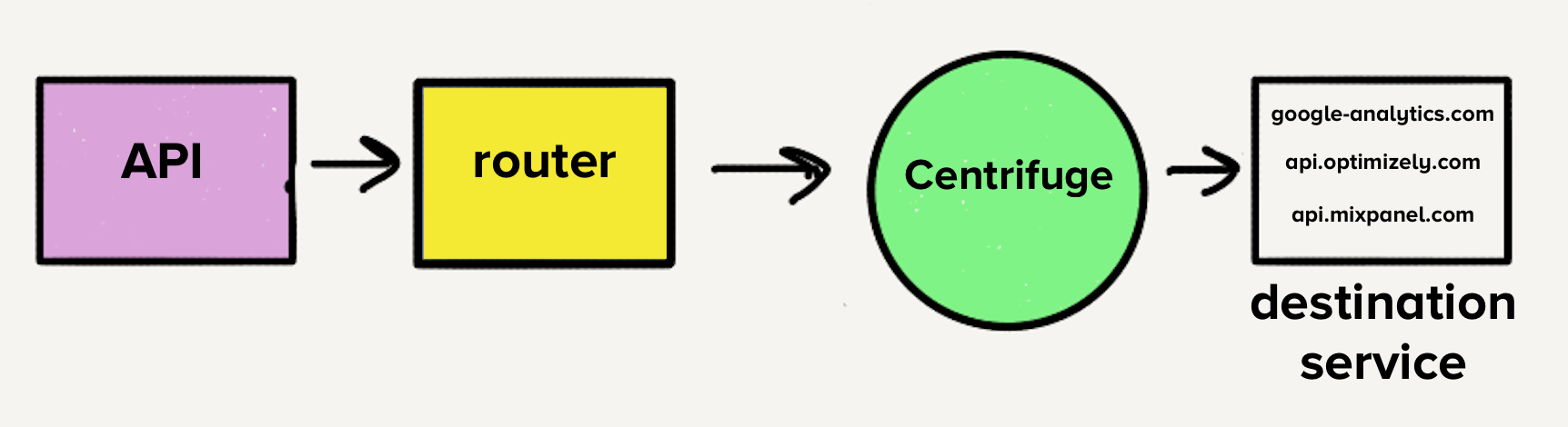
Moving to a Monorepository
With the shift to a single service, consolidating all destination code into a monorepository became logical. This entailed merging diverse dependencies and tests into one repo, a process anticipated to be complex.
The team committed to a single version for each of the 120 unique dependencies across all destinations. As destinations were migrated, their dependencies were updated to the latest versions, and any breaking changes were addressed. This transition eliminated the need to track differing dependency versions, significantly reducing codebase complexity and making destination maintenance less time-consuming and risky.
A robust test suite was crucial for quickly and easily running all destination tests, a major hurdle when updating shared libraries. Fortunately, destination tests shared a similar structure, comprising basic unit tests for transform logic and HTTP requests to partner endpoints to verify event delivery.
The initial motivation for separating destination codebases into individual repos was to isolate test failures. However, this proved to be a false advantage. HTTP request-based tests still failed frequently, and the isolation diminished the incentive to clean up failing tests, leading to persistent technical debt. Minor changes that should have taken hours often stretched into days or weeks.
Building a Resilient Test Suite
Outbound HTTP requests to destination endpoints during test runs were the primary cause of test failures. Unrelated issues, such as expired credentials, should not invalidate tests. Furthermore, some destination endpoints were significantly slower, with some tests taking up to five minutes. With over 140 destinations, a full test suite run could exceed an hour.
To address these issues, Traffic Recorder was developed, built atop yakbak. Traffic Recorder records and saves destination test traffic. During a test's initial run, requests and their corresponding responses are saved to a file. Subsequent runs play back these recorded interactions, eliminating the need to hit actual destination endpoints. These files are checked into the repository, ensuring consistent test outcomes across changes. By removing reliance on external HTTP requests, tests became significantly more resilient, a prerequisite for migrating to a single repository. Integrating Traffic Recorder reduced the test execution time for all 140+ destinations to milliseconds, a stark contrast to the minutes a single destination's tests previously required. The impact felt transformative.
Why a Monolith Works
Once all destination code resided in a single monorepository, merging it into a single service was straightforward. This consolidation dramatically improved developer productivity, as changes to shared libraries no longer required deploying 140+ services. A single engineer could deploy the service in minutes.
Tangible proof of this improvement was the increased velocity. Before the transition, 32 improvements were made to shared libraries; one year after, this number rose to 46.
The change also benefited operational efficiency. With all destinations within one service, the combined workload offered a balanced mix of CPU and memory-intensive tasks, simplifying scaling. The larger worker pool could absorb load spikes, eliminating the need for pages for low-traffic destinations.
Trade-Offs
The transition from a microservice architecture to a monolith represented a significant overall improvement, but it came with inherent trade-offs:
- Difficult Fault Isolation: In a monolith, a bug in one destination that causes a service crash affects all destinations. While comprehensive automated testing is in place, tests have limits. Efforts are underway to develop more robust mechanisms to prevent one destination from bringing down the entire service, while still retaining the benefits of a monolithic structure.
- Less Effective In-Memory Caching: Previously, individual services for low-traffic destinations maintained 'hot' in-memory caches of control plane data due to fewer processes. Now, with caches distributed across 3000+ processes, cache hit rates are lower. While solutions like Redis could address this, they introduce another scaling concern. This loss of caching efficiency was accepted in favor of substantial operational benefits.
- Dependency Update Risks: While the monorepository resolved dependency management issues, updating a library to its newest version might necessitate updating multiple destinations to ensure compatibility. The team believes the simplicity of this approach outweighs the trade-off, and the comprehensive automated test suite quickly flags any breaking changes.
Conclusion
The initial microservice architecture served its purpose by isolating destinations and addressing immediate performance issues. However, it proved unsustainable for scaling, lacking the necessary tooling for bulk updates and deployments. This led to a decline in developer productivity.
Transitioning to a monolith resolved many operational issues and significantly boosted developer productivity. This shift was not undertaken lightly and involved careful consideration of critical factors. A robust testing suite was essential for a single repository, preventing a recurrence of the productivity losses caused by constant test failures in the past. The team embraced the inherent trade-offs of a monolithic architecture, ensuring they had strategies to manage each challenge.
The choice between microservices and a monolith depends on specific product requirements. While microservices work well in some parts of Twilio Segment's infrastructure, server-side destinations exemplified how this popular trend could impede productivity and performance. For this particular challenge, a monolithic solution proved to be the optimal path.