Google Introduces Transformer 2.0: Unpacking Nested Learning
Google unveils 'Nested Learning,' a new AI paradigm treating architecture and optimization as unified, multi-frequency loops. This approach addresses catastrophic forgetting and enables models like 'Hope' to achieve continual learning and superior long-context reasoning, marking a significant leap toward adaptable, human-like AI systems.

Google's recent publication on "Nested Learning" introduces a paradigm shift in how artificial intelligence models are conceived and trained. Historically, AI development has often separated model architecture from its learning mechanism. This new research challenges that fundamental distinction, proposing that these two elements are intrinsically linked.
The "Goldfish Memory" Problem: Catastrophic Forgetting
One of the persistent challenges in AI is catastrophic forgetting. When a pre-trained model is exposed to new data for further learning, it frequently overwrites previously acquired knowledge. Conventional solutions typically involve architectural tweaks or fine-tuning learning rates. The Google research team, led by Ali Behrouz and Vahab Mirrokni, attributes this issue to the prevailing view of training as a monolithic, flat process where data is fed in, and weights are updated uniformly.
In stark contrast, the human brain exhibits neuroplasticity, adapting its structure based on experience and managing multiple learning processes at varying speeds, creating layers of memory that solidify over different timescales.

The uniform and reusable structure, along with multi-time–scale updates in the brain, are key components of continual learning in humans. Nested Learning enables multi-time–scale updates for each brain component, demonstrating that established architectures like transformers and memory modules are effectively linear layers with different frequency updates (source: research.google/blog).
Embracing Nested Learning
This is where Nested Learning offers a new perspective. The core concept is that a machine learning model functions not as a singular mathematical problem, but as a collection of smaller, nested optimization problems. This can be visualized as Russian nesting dolls, each representing a distinct learning engine with its own operational scope.
Under this paradigm, the model's architecture (e.g., a Transformer) and its optimizer (e.g., Adam or SGD) are considered fundamentally equivalent concepts: they are simply optimization loops operating at different frequencies. An inner loop might manage immediate attention mechanisms, discerning relationships between tokens, while an outer loop updates the network's long-term weights. Recognizing these as different levels of the same process allows for the creation of systems with "deeper computational depth," where components can be designed to update rapidly, slowly, or anywhere in between.
The "Hope" Architecture: A Proof-of-Concept
To validate their theory, the researchers developed Hope, a proof-of-concept architecture. Hope is a variant of the "Titans" architecture, distinguished by its self-modifying capabilities through a Continuum Memory System (CMS). Instead of discrete short-term (context window) and long-term (static weights) memory, Hope models memory as a continuous spectrum. It features modules that update at varying rates, enabling it to prioritize memories based on their perceived utility or novelty. This self-referential process allows the model to optimize its own memory as it learns.
The documented results are compelling. Hope outperforms standard transformers and contemporary recurrent models in language modeling tasks. Its superior memory management particularly shines in "Needle-In-Haystack" tests, where it efficiently locates specific information within vast texts without being overwhelmed by noise.
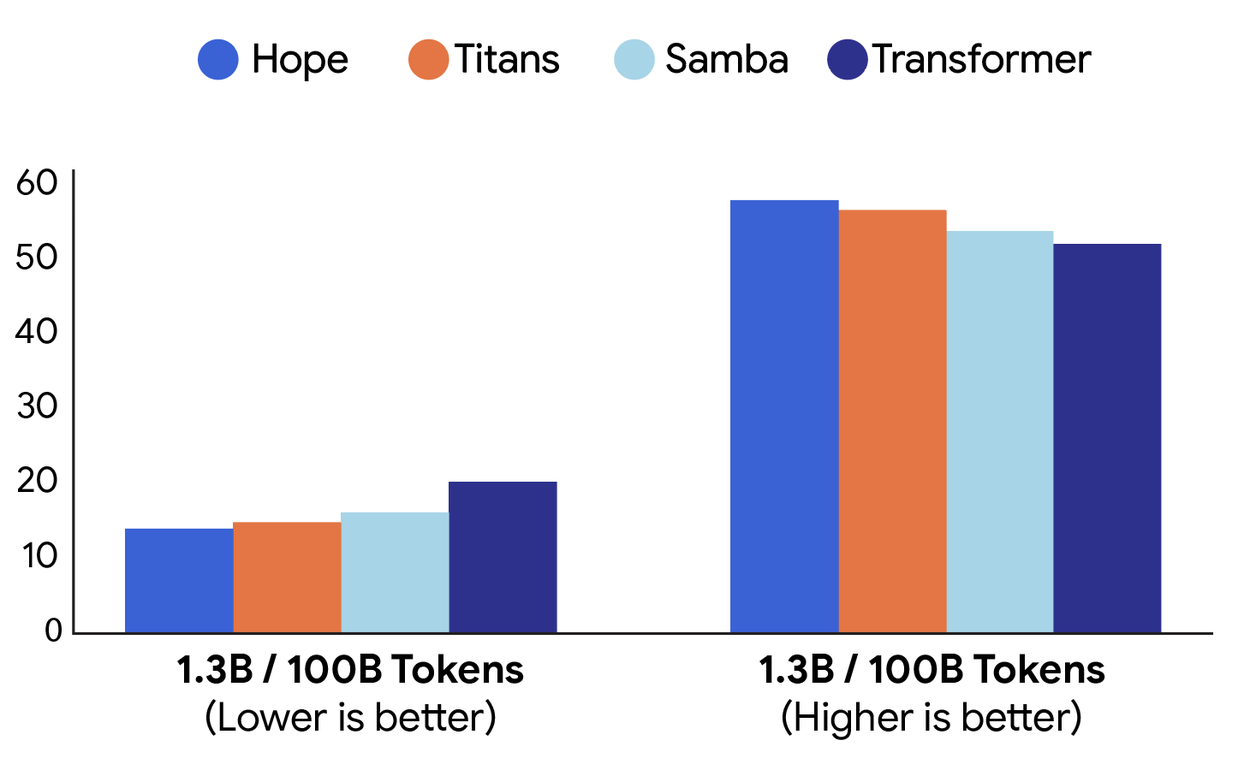
Performance comparison on language modeling (perplexity; left) and common-sense reasoning (accuracy; right) tasks between different architectures: Hope, Titans, Samba, and a baseline Transformer (source: research.google/blog).
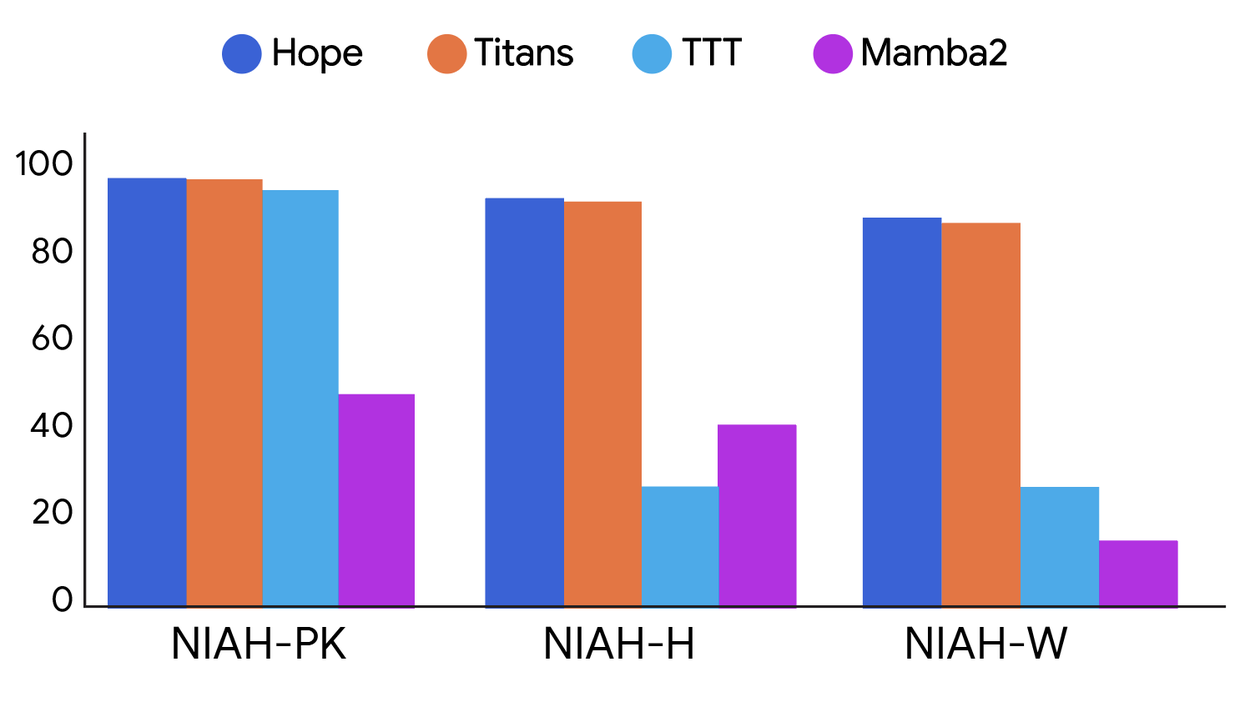
Performance comparison on long-context tasks with different levels of difficulty between different architectures: Hope, Titans, TTT, and Mamba2. NIAH-PK, NIAH-H, and NIAH-W are needle-in-a-haystack tasks focused on pass-key, number, and word respectively (source: research.google/blog).
Introducing Deep Optimizers
The concept of optimizers as another layer of memory led to a re-evaluation of current optimization techniques. Traditional optimizers often rely on simple dot-product similarity, which may not adequately capture the complex relationships between different data samples. The researchers addressed this limitation by replacing the dot-product objective with L2 regression loss within the optimizer itself, terming these Deep Optimizers. This innovation led to new momentum variants that exhibit enhanced robustness when processing noisy or imperfect data, essentially applying principles of associative memory to the network's training mathematics.
Why This Matters
Current Large Language Models (LLMs) face limitations, primarily their static nature post-training. To 'learn' new information, everything must be constrained within a context window, an approach that is both resource-intensive and temporary. Nested Learning presents a viable pathway towards models that emulate human-like learning, facilitating continual learning—the ability to acquire new skills without compromising existing knowledge, dynamically adapting their own structure. This advancement suggests a move beyond mere software enhancements, hinting at a biological metaphor for future models. If 'Hope' serves as an accurate indicator, the next generation of AI may not merely be larger, but exhibit a form of mathematical 'aliveness.'
This research could fundamentally reshape our understanding and development of advanced AI systems, potentially making 'Transformer 2.0' headlines an understatement of its profound implications.