How Airbnb Runs Distributed Databases on Kubernetes at Scale
Explore Airbnb's strategy for running highly available and fault-tolerant distributed databases on Kubernetes at scale, leveraging multi-cluster architectures, custom operators, and AWS EBS.
The technical details presented in this article are derived from official documentation shared by the Airbnb Engineering Team, to whom all credit is attributed for the underlying architectural solutions. This analysis offers our interpretation and insights.
Historically, organizations depended on monolithic, expensive standalone servers for their databases. With increasing traffic, the conventional solution involved sharding—partitioning data into smaller segments and distributing them across multiple machines. While effective initially, this approach eventually introduced significant operational overhead. Managing shards, performing upgrades, and ensuring system flexibility became a complex and costly challenge.
The past decade has witnessed the emergence of distributed, horizontally scalable open-source SQL databases. These systems enable organizations to distribute data across numerous smaller machines, moving away from reliance on single, large servers.
However, operating such databases reliably in a cloud environment presents considerable complexity. It extends beyond merely provisioning more servers; it necessitates guaranteeing strong consistency, high availability, and low latency, all while managing costs. Achieving this balance has been a formidable task even for highly advanced engineering teams.
This context highlights the innovative approach taken by Airbnb’s engineering team.
Rather than confining a database cluster to a single Kubernetes environment, Airbnb opted to deploy distributed database clusters across multiple Kubernetes clusters, with each cluster corresponding to a distinct AWS Availability Zone.
This design pattern is unconventional; many companies steer clear of it due to its inherent complexity. However, Airbnb’s engineers identified it as the optimal strategy to enhance reliability, minimize failure impact, and maintain smooth operations.
This article will explore Airbnb's implementation of this design and the challenges encountered during its adoption.
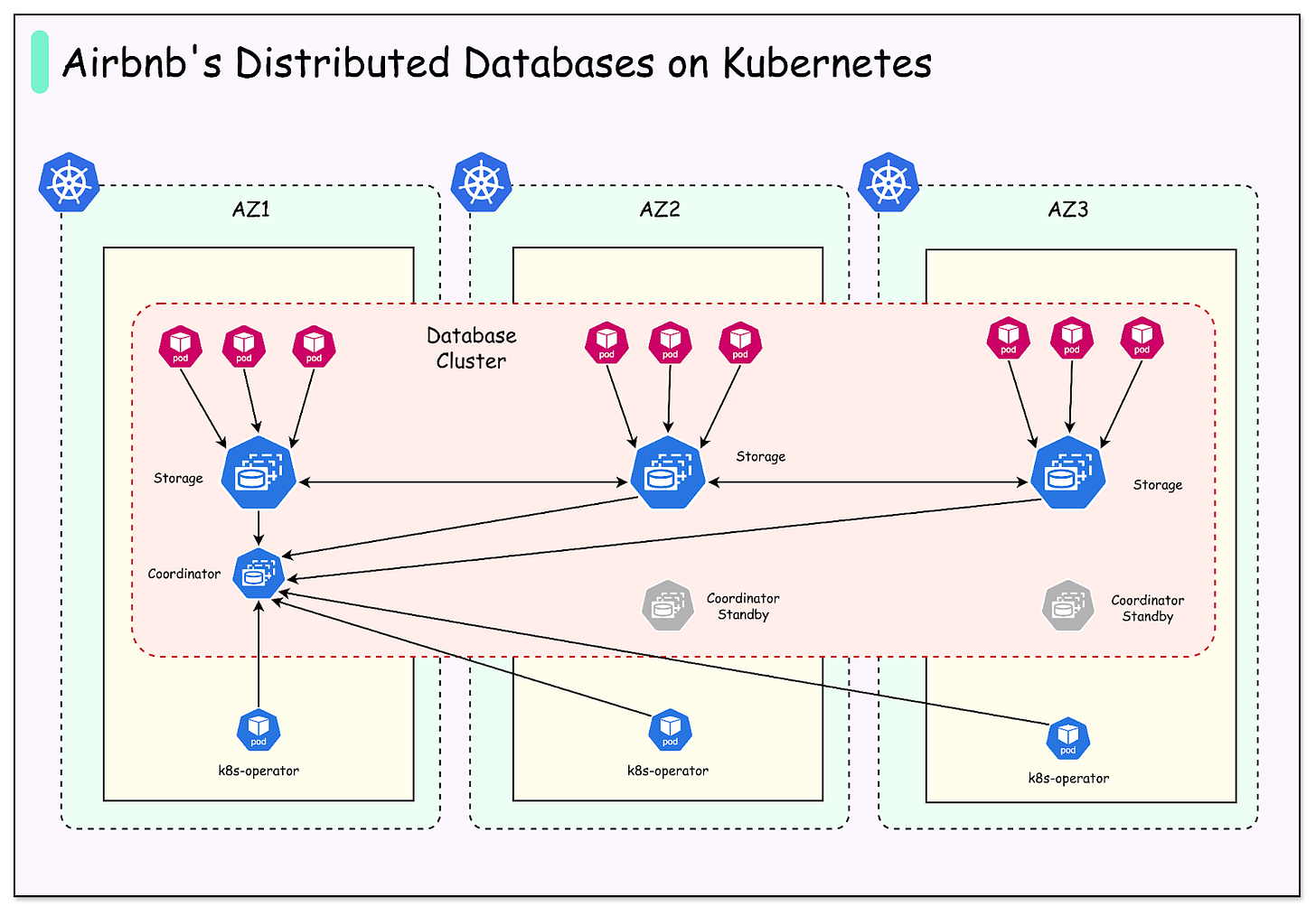
Running Stateful Databases on Kubernetes
Kubernetes excels at managing stateless workloads—applications that do not retain any information between requests. A typical example is a web server serving static HTML pages; if one server fails, another can seamlessly take its place, as no critical state or data is bound to a single machine.
Consider the following diagram:
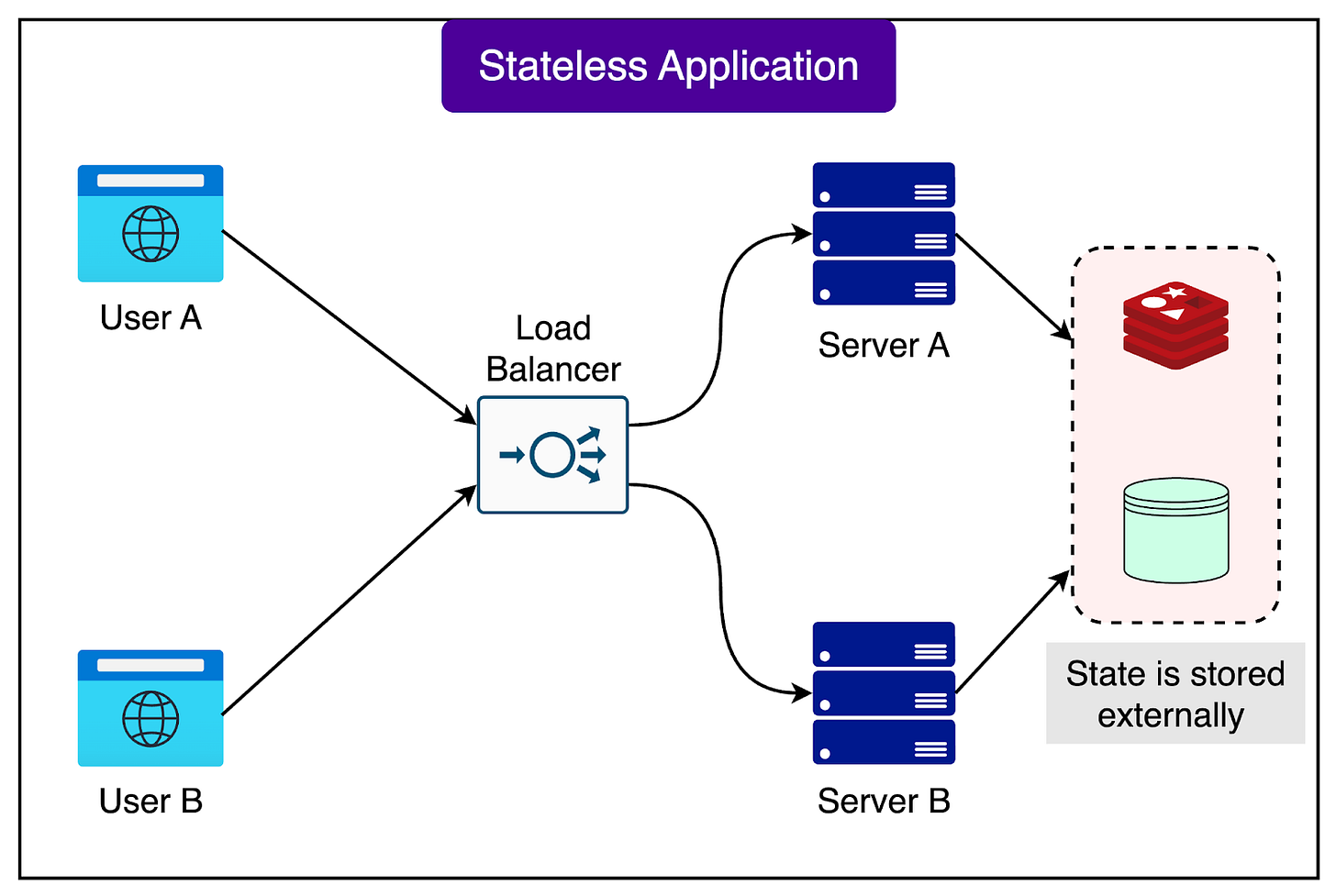
Databases, by contrast, are stateful systems. They are responsible for tracking data, ensuring its reliable storage, and preventing data loss.
Deploying stateful systems on Kubernetes presents greater challenges, as any node replacement or restart requires mechanisms to prevent data corruption or loss.
A primary risk arises from node replacement. In a distributed database, data resides across multiple nodes. Maintaining data correctness relies on a quorum, which dictates that a majority of nodes (e.g., 2 out of 3 or 3 out of 5) must concur on the current data state. If an excessive number of nodes fail or are replaced prematurely, quorum can be lost, potentially halting database operations. Kubernetes, by default, lacks inherent knowledge of data distribution across nodes and thus cannot prevent hazardous replacements.
The Airbnb engineering team addressed this challenge using several ingenious techniques:
- AWS EBS Volumes: Each database node persists its data on Amazon Elastic Block Store (EBS), a highly durable cloud storage service. In the event of a node termination or replacement, the EBS volume can be swiftly detached from the original machine and reattached to a new one, eliminating the need to copy the entire dataset to a fresh node.
- Persistent Volume Claims (PVCs): Within Kubernetes, a Persistent Volume Claim (PVC) enables applications to request storage that persists independently of a specific pod or container lifecycle. Airbnb leverages PVCs to ensure that upon new node creation, Kubernetes automatically reattaches the existing EBS volume, thereby reducing human error and accelerating recovery.
- Custom Kubernetes Operator: A Kubernetes Operator acts as an intelligent controller, extending Kubernetes with application-specific operational knowledge. Airbnb developed a custom operator specifically for its distributed database to meticulously manage node replacements. This operator ensures that a new node is fully synchronized with the cluster before any subsequent replacement occurs. This process, known as serializing node replacements, prevents multiple high-risk changes from occurring concurrently.
The diagram below illustrates the concept of a PVC in Kubernetes:
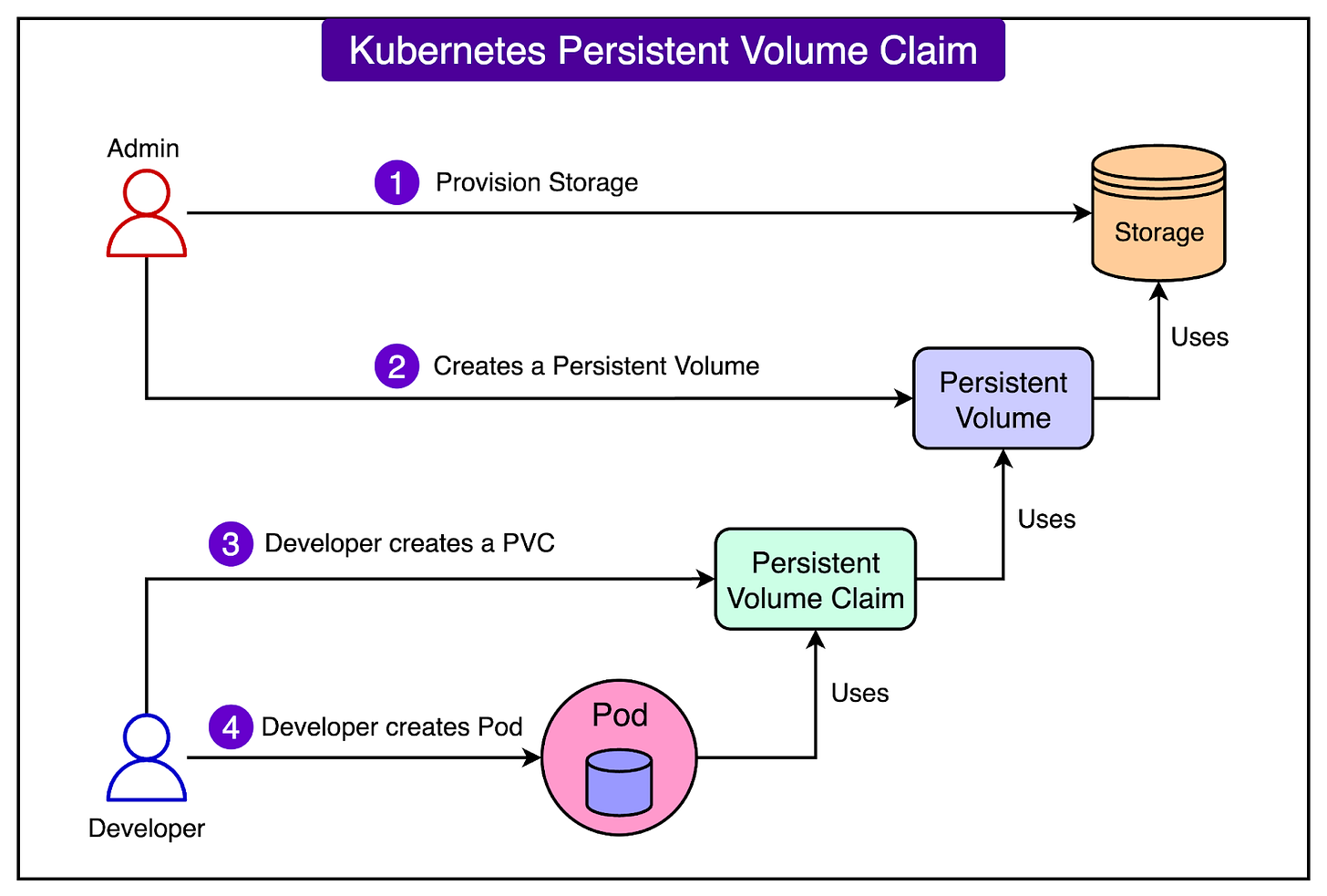
By integrating EBS volumes, PVCs, and a custom operator, Airbnb has established a secure method for running a distributed database on Kubernetes. This approach allows them to harness Kubernetes' automation capabilities without compromising the consistency or availability essential for database operations.
Node Replacement Coordination Strategies
In any large-scale system, database nodes inevitably require replacement. Airbnb categorizes the reasons for such events into three types:
- Database-Initiated Events: These include planned modifications such as configuration updates or software version upgrades.
- Proactive Infrastructure Events: These occur when the cloud provider (e.g., AWS) deprecates older virtual machines or when engineers execute routine system upgrades.
- Unplanned Failures: These encompass unforeseen problems like hardware failures or unresponsive nodes.
Each scenario necessitates a distinct handling strategy.
Airbnb's approach involves:
- Custom Operator for Planned Events: For database-initiated changes, Airbnb's custom operator first verifies the operational status of all nodes in the cluster. Only upon confirmation does it permit pod replacement, thus preventing the simultaneous replacement of multiple unhealthy nodes that could lead to cluster downtime.
- Admission Hooks for Infrastructure Events: Kubernetes' admission hooks intercept or modify requests prior to their execution. Airbnb utilizes these hooks to capture pod eviction requests originating from the infrastructure layer (e.g., AWS VM retirement). Rather than immediate eviction, the hook blocks the request and applies a special annotation to the pod. The custom operator detects this annotation and proceeds with a controlled, safe deletion of the pod. This mechanism ensures that infrastructure-driven replacements are sequenced appropriately with any database-driven replacements.
- Unplanned Failures: Sudden machine failures cannot be coordinated in advance. Nonetheless, Airbnb’s operator ensures that during the replacement of a failed node, no other planned replacements are permitted. This critical measure helps maintain system quorum and prevents further instability during the recovery process.
In essence, Airbnb has engineered a layered safety net. Their custom operator, in conjunction with admission hooks, serializes planned replacements and pauses other maintenance activities when an unplanned failure is already underway. This meticulous coordination is pivotal in maintaining database cluster availability despite continuous node churn.
Kubernetes Upgrades and Rollbacks
Maintaining an up-to-date Kubernetes environment is crucial for security, stability, and access to new features. However, database upgrades present unique risks. Unlike stateless services, a database cannot simply restart without repercussions, as it must safeguard the integrity and availability of its stored data.
A significant challenge arises with cloud-managed Kubernetes services. When the control plane—the central component orchestrating worker nodes and scheduling—is upgraded in these systems, rollback capabilities are often absent. A faulty upgrade can therefore lead to severe disruption, with the only recourse being to await a provider-side fix.
To mitigate this risk, Airbnb's engineering team employs self-managed Kubernetes clusters. This setup grants engineers complete control over the cluster, enabling rollbacks should an upgrade introduce issues. While this approach enhances safety, it doesn't entirely eliminate risk; a necessary rollback could still result in database downtime or instability until completion.
Airbnb's strategy hinges on carefully sequenced upgrades and its multi-cluster deployment design. Rather than undertaking a monolithic upgrade, they upgrade one cluster at a time, typically starting with a smaller or less critical one. Because each database spans multiple clusters across distinct availability zones, temporary instability in one cluster during an upgrade does not prevent others from continuing to serve traffic. This approach significantly narrows the 'blast radius' of a problematic upgrade, helping to maintain overall system availability.
Multi-Cluster Deployment for Enhanced Fault Tolerance
A pivotal architectural decision by Airbnb was to deploy each database across three distinct Kubernetes clusters, with each cluster residing in a separate AWS Availability Zone (AZ).
An Availability Zone functions as an isolated data center within a given region, equipped with its own independent power, networking, and hardware. Distributing clusters across three AZs ensures that the failure of a single zone does not compromise the entire database.
The following diagram illustrates this setup:
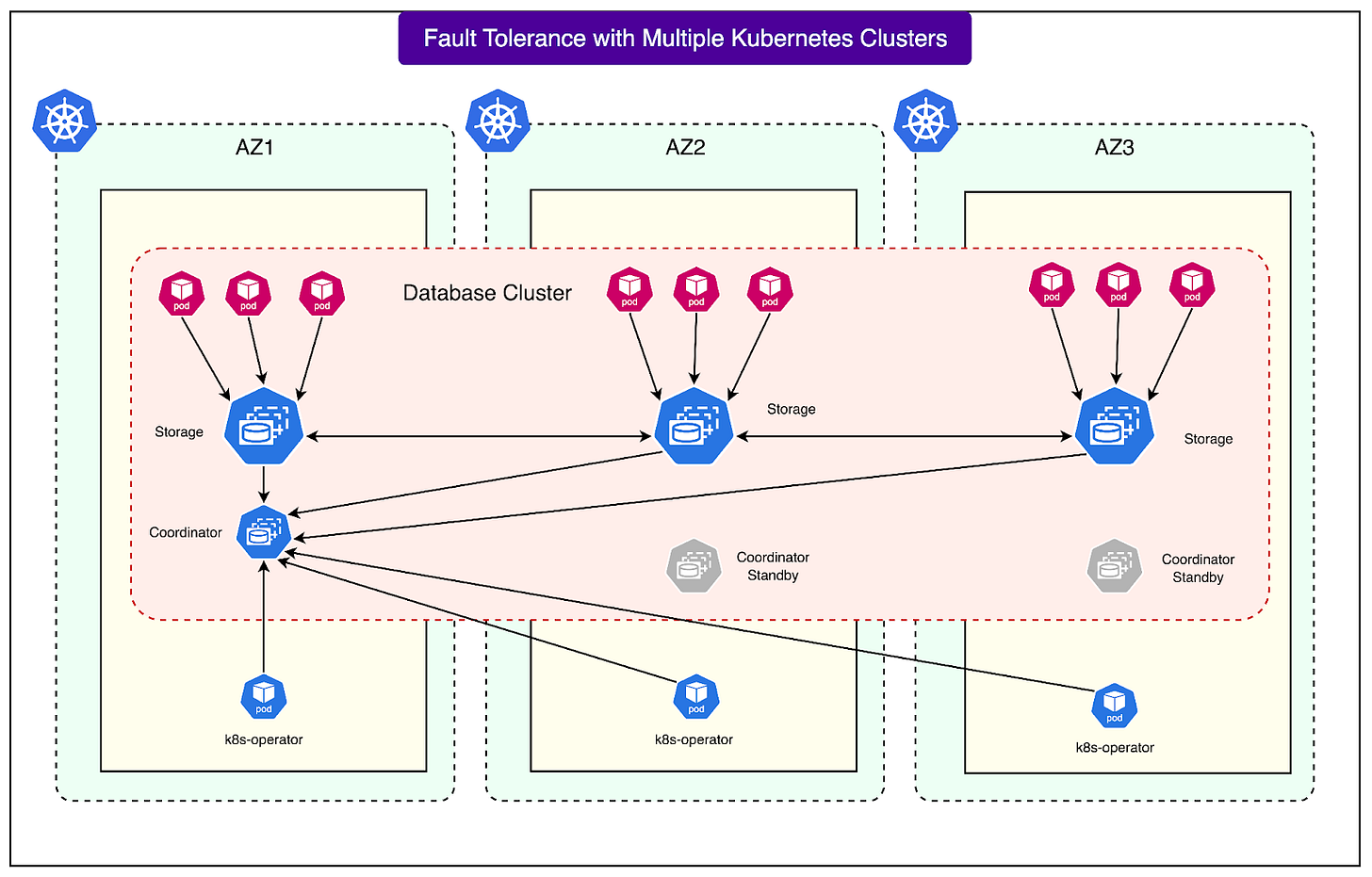
This configuration offers several key advantages:
- Fault Isolation: AWS designs its Availability Zones to ensure that issues in one zone do not propagate to others; for instance, a networking outage in one AZ is not expected to affect another. By aligning their clusters with AZs, Airbnb inherently gains this isolation, containing infrastructure-level damage to a single zone.
- Reduced Deployment Blast Radius: The 'blast radius' denotes the extent of a failure's impact. With Airbnb's three-cluster database deployment, a faulty configuration change or bug introduced during a rollout will only affect one cluster. The remaining two clusters continue processing queries, thus preserving overall system availability.
- Canary Deployments for Safety: Airbnb avoids simultaneous widespread deployment of changes. Instead, new database configurations or software versions are first introduced to a single cluster within one AZ, serving as a canary test. This allows early detection of any issues before they propagate across all clusters.
- Overprovisioning for Resilience: In preparation for worst-case scenarios, Airbnb intentionally overprovisions capacity. This ensures that even if an entire Availability Zone or a full Kubernetes cluster becomes unavailable, the remaining clusters can still manage the complete workload, guaranteeing smooth operation during failure conditions.
Through these combined practices, Airbnb has forged a database architecture capable of graceful failure tolerance. During one incident, a faulty configuration led to the abrupt termination of all virtual machines of a specific type in Airbnb’s staging environment, decimating most of the query layer pods in that cluster. However, due to the three-cluster database deployment, the other two clusters continued to operate normally, preventing user-facing impact.
Leveraging AWS Elastic Block Store (EBS)
For persistent storage, Airbnb selected Amazon Elastic Block Store (EBS), a block-level storage service known for providing highly durable and reliable disks for cloud workloads. EBS is instrumental in enhancing the resilience and efficiency of Airbnb’s database clusters.
EBS contributes in the following ways:
- Fast Reattachment During Node Replacement: Should a node fail, its associated EBS volume can be swiftly detached and reattached to a new machine. This significantly accelerates recovery compared to provisioning and copying data to a fresh disk.
- Superior Durability Compared to Local Disks: Local disks are intrinsically linked to their host machines; machine failure can lead to data loss. EBS, conversely, is architected to withstand machine failures, offering substantially stronger guarantees for critical database information.
- Reliable Clusters with Optimized Replication: The inherent durability of EBS enables Airbnb to confidently operate its database with only three data replicas. Without EBS-level durability, a higher number of replicas might be necessary to mitigate data loss risks, increasing both costs and operational complexity.
Addressing Latency Challenges
Despite its durability, EBS is not without its imperfections. It occasionally exhibits tail latency spikes, wherein a small percentage of requests experience significantly longer processing times than usual.
For Airbnb, the p99 latency (the 99th percentile of requests) sometimes extended up to a full second. In a high-throughput database environment, even infrequent one-second delays can introduce operational issues.
Airbnb implemented several solutions, including:
- Storage Read Timeout and Retries: The team introduced a session variable for storage read timeouts. If EBS experiences a stall, the query can automatically retry on another node within the cluster, rather than waiting indefinitely.
- Replica Reads for Improved Distribution: By default, the database typically retries requests solely at the leader node, which can become a performance bottleneck. Airbnb modified this behavior to permit retries at both the leader and its replicas. For performance optimization, the system prioritizes the closest replica, thereby minimizing costly cross-AZ network traffic.
- Stale Reads for Tolerant Workloads: For use cases that tolerate slightly outdated data, Airbnb enabled stale reads. This feature allows replicas to serve queries independently, without needing to contact the leader. Should the leader experience an EBS latency spike, replicas can continue to handle the workload, maintaining system responsiveness.
By integrating these techniques, Airbnb successfully mitigated the impact of EBS latency spikes while preserving the reliability advantages of EBS. The outcome is a system capable of handling millions of queries per second without compromising consistency or performance for critical workloads.
Conclusion
Airbnb’s engineering team tackled one of modern infrastructure's most significant challenges: reliably operating a distributed database on Kubernetes.
Through a thoughtful combination of Kubernetes operators, multi-cluster deployments, AWS EBS, and advanced read strategies such as replica reads and stale reads, they engineered a system that achieves both high availability and cost efficiency.
This design is not merely theoretical; it is robustly running in production. Airbnb currently operates multiple clusters, with its largest achieving impressive metrics:
- 3 million queries per second (QPS) handled reliably
- 150 storage nodes operating cohesively
- Over 300 terabytes of data stored
- 4 million internal shards distributing the load
- 99.95% availability, fulfilling stringent reliability requirements
With this architecture, Airbnb has successfully met its objectives: high availability, low latency, scalability, and reduced maintenance costs. The system demonstrates resilience against node replacements, infrastructure failures, and even the loss of an entire Availability Zone without service disruption.
The primary insight is that open-source distributed databases can thrive on Kubernetes when coupled with meticulous engineering. Airbnb’s accomplishments illustrate that despite the complexities of running stateful systems in Kubernetes, the resulting advantages in automation, resilience, and cost efficiency justify the undertaking.
For other engineering teams, Airbnb’s methodology offers a valuable roadmap: initiate with smaller deployments, leverage operators for operational safety, design for fault isolation across clusters, and develop strategies to address edge cases such as storage latency. Adopting these practices makes achieving high availability in the cloud not only possible but also sustainable at scale.