How Flipkart Built a Highly Available MySQL Cluster for 150+ Million Users
Discover how Flipkart's Altair system provides high availability for MySQL, serving 150M+ users. It details primary-replica architecture, smart failure detection, and automated failover.
Disclaimer
The information presented in this post is derived from official documentation openly shared by the Flipkart Engineering Team. All technical details and credit are attributed to the Flipkart Engineering Team, with links to original sources provided in the references section. We have analyzed these details and offered our insights. Should you identify any inaccuracies or omissions, please inform us via comment, and we will endeavor to correct them.
Introduction
Flipkart, one of India’s largest e-commerce platforms, serves over 500 million registered users, with 150-200 million daily users. The platform experiences extreme traffic surges, particularly during major events like its "Big Billion Days" sale. To ensure continuous operation, Flipkart relies on thousands of microservices that manage every aspect of its business, from order processing to logistics and supply chain systems.
For its most critical transactional domains, Flipkart depends on MySQL, valuing its durability and ACID guarantees essential for e-commerce workloads. However, operating MySQL at Flipkart's immense scale posed significant challenges. Historically, each engineering team often managed its own database clusters, leading to inconsistent practices, redundant efforts, and a substantial operational burden. This complexity was acutely felt during peak shopping periods, where even minor inefficiencies could escalate into widespread disruptions.
To address these issues, the Flipkart engineering team developed Altair, an internally managed service designed to provide MySQL with built-in high availability (HA). Altair’s primary goal is to ensure that the company’s crucial databases remain consistently available for writes, while simultaneously reducing the manual effort required by teams to maintain their health. This allows Flipkart engineers to concentrate on developing services, trusting Altair to manage complex database operations like failover, recovery, and availability.
This article delves into the inner workings of Altair, exploring the technical decisions Flipkart made to balance availability and consistency, and the engineering trade-offs inherent in running relational databases at such a massive scale.
High Availability Model at Flipkart
Flipkart’s Altair system employs a primary–replica setup to achieve high availability for MySQL. In this architecture, a single primary database handles all write operations and may also serve some read requests. Complementing this, one or more replicas continuously copy data from the primary asynchronously. This asynchronous replication means there can be a slight delay before changes propagate to the replicas, which primarily serve read traffic, allowing the primary to focus on writes.
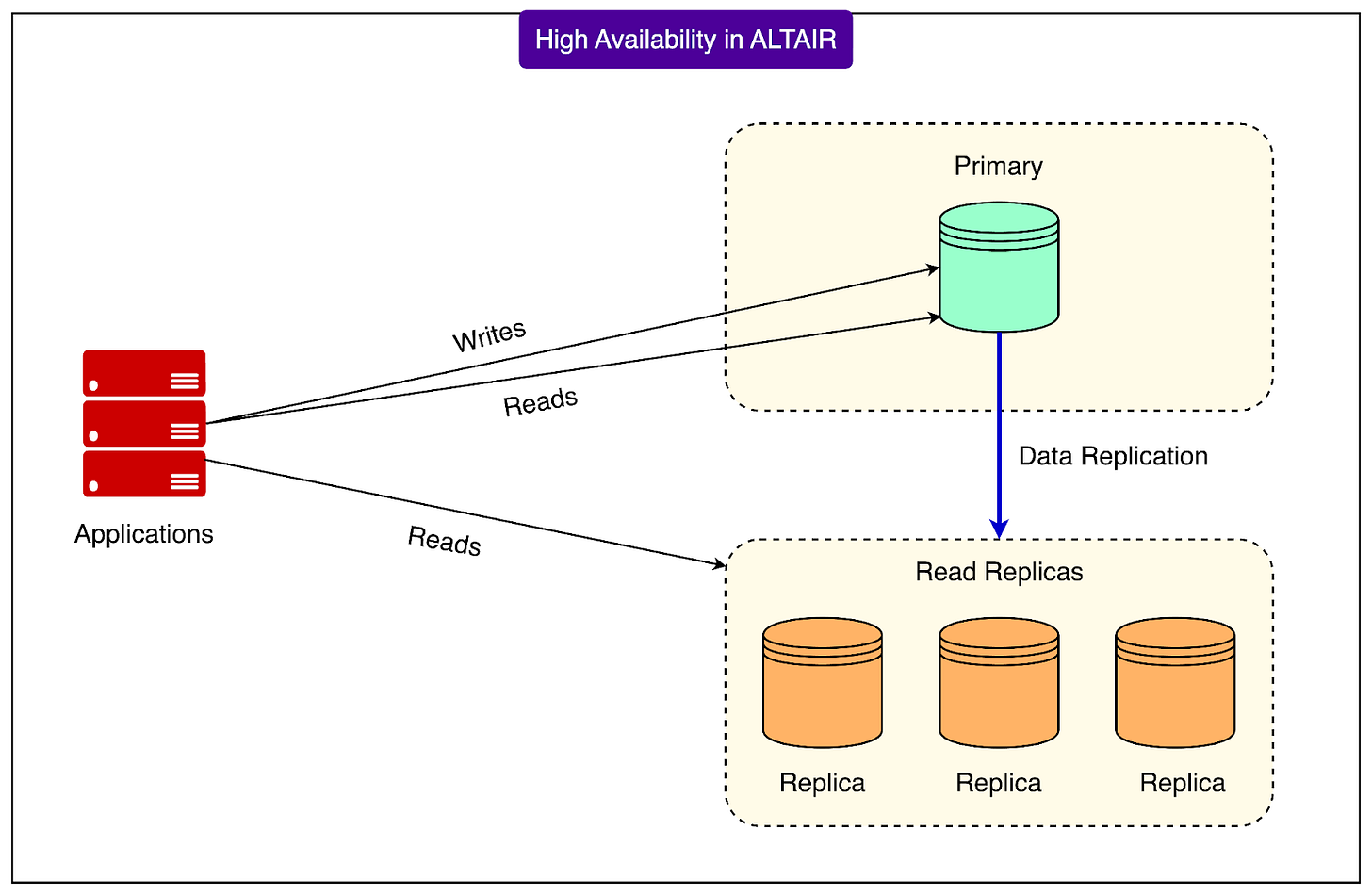
The fundamental objective of this setup is straightforward: upon a primary failure, the system must swiftly promote a healthy replica to assume the role of the new primary. This mechanism ensures uninterrupted write availability with minimal disruption.
Altair targets an exceptionally high availability, nearing "five nines" (99.999%). While no complex system can guarantee perfect uptime, the aim is to minimize downtime as much as possible.
To ensure reliable failover, the Flipkart engineering team meticulously considered several critical factors:
- Data-loss tolerance: Minimizing data loss during failover.
- Fault detection reliability: Accurately identifying genuine primary failures.
- Failover workflow strength: Designing a robust, error-free switch process.
- Network partition handling: Maintaining resilience when network segments lose connectivity.
- Fencing the old primary: Preventing a failed primary from inadvertently accepting new writes.
- Split-brain prevention: Averting scenarios where multiple nodes simultaneously believe they are the primary.
- Automation: Reducing human intervention for quick and consistent failovers.
By integrating these elements, Altair is engineered to maintain MySQL's high availability even in failure conditions.
End-to-End Failure Workflow
When a primary database fails, Altair orchestrates a well-defined sequence of steps to recover and ensure applications can resume writing data. This intricate process, known as a failover workflow, involves multiple components working in concert.
The workflow comprises five main stages:
- Failure detection: The system continuously monitors all MySQL nodes for any issues with the primary. A failure is suspected if it appears unhealthy or unreachable.
- False-positive screening: Before initiating major actions, Altair double-checks if the detected failure is genuine. This step prevents unnecessary primary promotions due to transient glitches.
- Failover tasks: If the primary is definitively down, the system begins recovery. This includes fencing or stopping the old primary, selecting the optimal replica, and promoting it to become the new primary.
- Service discovery update: Once a new primary is ready, Altair updates its DNS record. This ensures that applications connecting to the database automatically redirect to the new primary, typically without requiring restarts.
- Fencing the old primary: To prevent multiple databases from acting as the primary simultaneously, Altair attempts to mark the old primary as read-only or completely shut it down. This step is vital for preventing split-brain scenarios where independent write operations could lead to data inconsistency.
How Failure Detection Works
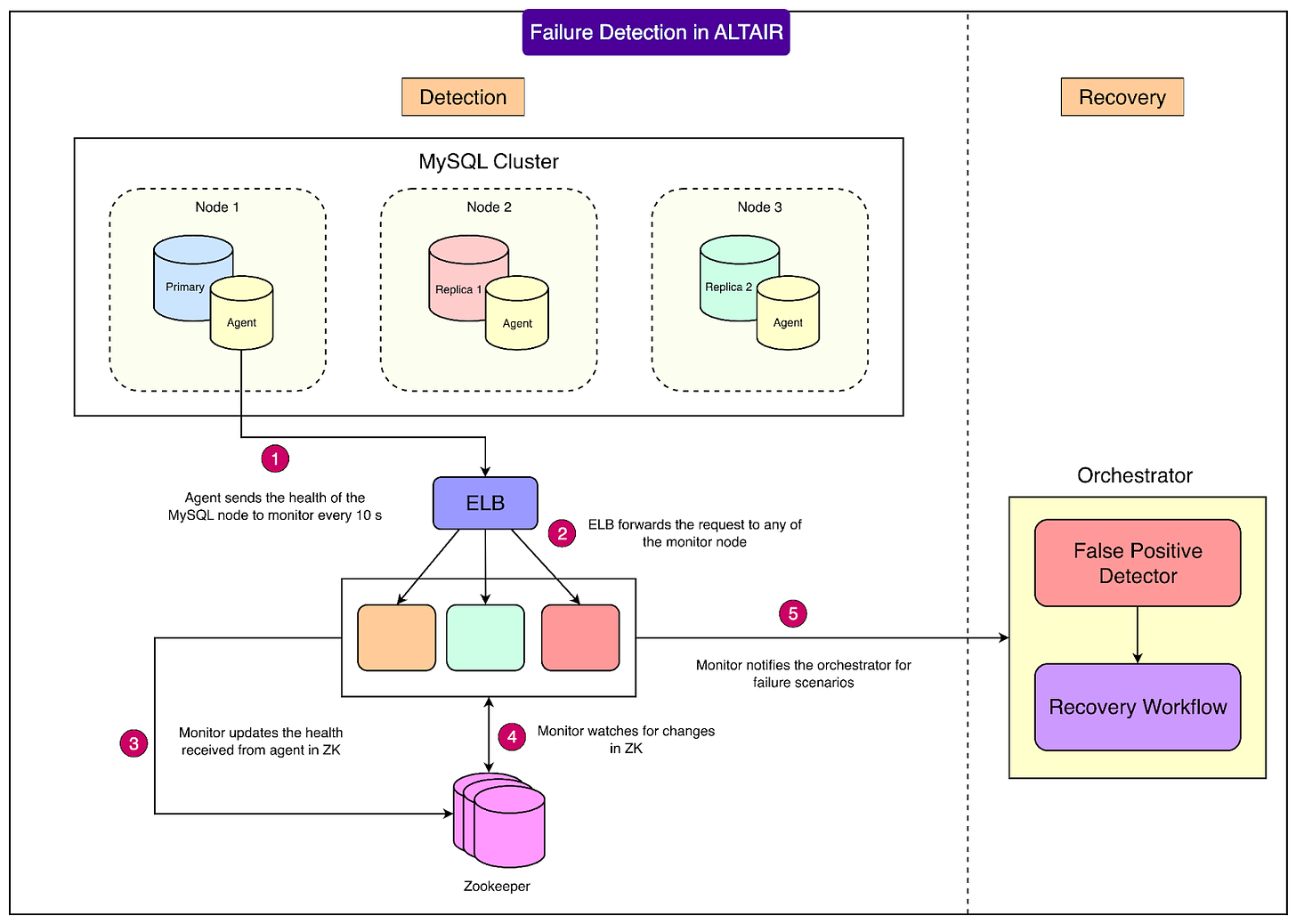
Altair employs a three-layered monitoring system for robust failure detection:
- Agent: A lightweight program running on each database node. It monitors the MySQL process, replication status, replication lag, and disk usage, reporting health information every 10 seconds.
- Monitor: A Go-based microservice that collects these health reports and writes the status to ZooKeeper, also every 10 seconds. The monitor compares health states, checks against predefined thresholds, and flags potential issues. If a failure is suspected, it alerts the orchestrator. Multiple monitors can operate in parallel, ensuring scalability as Flipkart expands.
- Orchestrator: This component acts as the workflow's central intelligence. It verifies whether a detected failure is real or a false alarm. Upon confirmation, it initiates the failover process.
See the diagram below:
Preventing False Alarms
To avoid premature failovers, Altair goes beyond simple missed signals, performing deeper checks:
- It verifies the health of the virtual machine hosting the database.
- It checks if replicas can still establish connections to the primary.
- It also tests whether the orchestrator itself can reach the primary.
The rule is straightforward: if either the orchestrator or at least one replica can connect to the primary, the primary is considered alive. If both fail to connect, the system proceeds with failover.
Steps During Failover
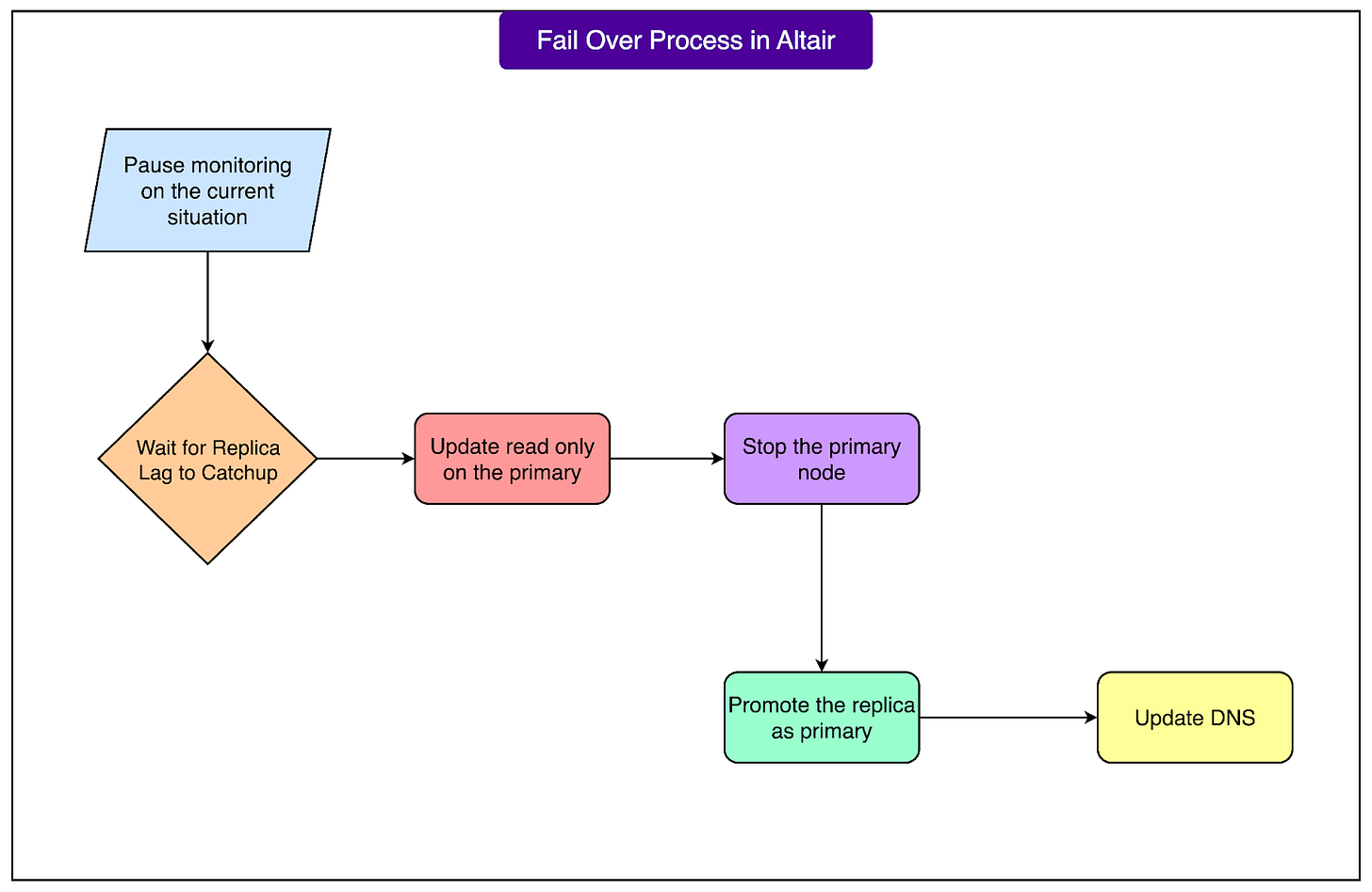
When the orchestrator decides to initiate a failover, Altair executes these tasks in a precise order:
- Temporarily ceases monitoring the affected node.
- Allows replicas to catch up by applying all pending relay logs, thereby minimizing data loss.
- Sets the old primary to read-only mode if it remains reachable.
- Completely stops the old primary if feasible.
- Promotes the most suitable replica to become the new primary.
- Updates DNS records to automatically direct applications to the new primary.
See the diagram below:
This structured approach ensures smooth failovers, minimizes data loss, and enables applications to reconnect to the new primary, typically without manual intervention.
Service Discovery
Upon failover completion, applications need to identify the new primary database's location. Altair addresses this through DNS-based service discovery.
The process works as follows:
- Applications connect to the database using a consistent DNS name (e.g.,
orders-db-primary.flipkart.com). - Behind the scenes, this DNS name resolves to the IP address of the current primary.
- During a failover, Altair updates the DNS record to point to the new primary’s IP address.
This design eliminates the need for manual updates or restarts for most applications. When they initiate a new connection, they are automatically directed to the new primary.
Exceptions are rare, occurring in unusual scenarios where DNS changes aren't propagated effectively, or if network partitioning necessitates manual intervention. In such cases, Flipkart's engineering team collaborates with client teams to restart applications and ensure traffic is routed correctly.
Split-Brain Risks
One of the most significant hazards in any high-availability setup is a split-brain scenario. This occurs when two distinct nodes simultaneously believe they are the primary. If both begin accepting writes independently, the data can diverge, leading to severe inconsistencies across the cluster that are arduous to reconcile.
Split-brain typically arises during network partitions. For instance, if the primary is healthy but isolated from the rest of the system due to a network issue, other nodes might perceive it as failed. Consequently, a replica is promoted, while the original primary continues to process writes, resulting in two active primaries.
See the diagram below:
![]()
Given MySQL's asynchronous replication, resolving this problem is particularly challenging, as the system cannot guarantee both strong consistency and availability during a network split. Flipkart prioritizes availability but integrates robust safeguards to prevent split-brain.
Should a split-brain occur, the consequences can be severe. Customer orders might be fragmented across different databases, causing confusion for both customers and sellers. Reconciling such data is time-consuming and costly. Flipkart references GitHub’s 2018 incident, where a brief connectivity problem led to nearly 24 hours of data reconciliation.
Altair incorporates multiple safeguards against split-brain scenarios:
- During failover, it attempts to stop the old primary from accepting new writes.
- In planned failovers, the old primary is first set to read-only, ensuring no further writes before the role switch.
- If the old primary cannot be stopped (e.g., due to a severe network partition), Altair may still promote a replica to maintain system availability.
- In ambiguous situations where the control plane cannot definitively ascertain the primary's state, Altair follows a cautious procedure:
- Pause the failover job.
- Notify client teams to halt application writes.
- Resume failover, promote the replica, and update DNS.
- Instruct clients to restart applications to connect to the correct new primary.
See the diagram below:
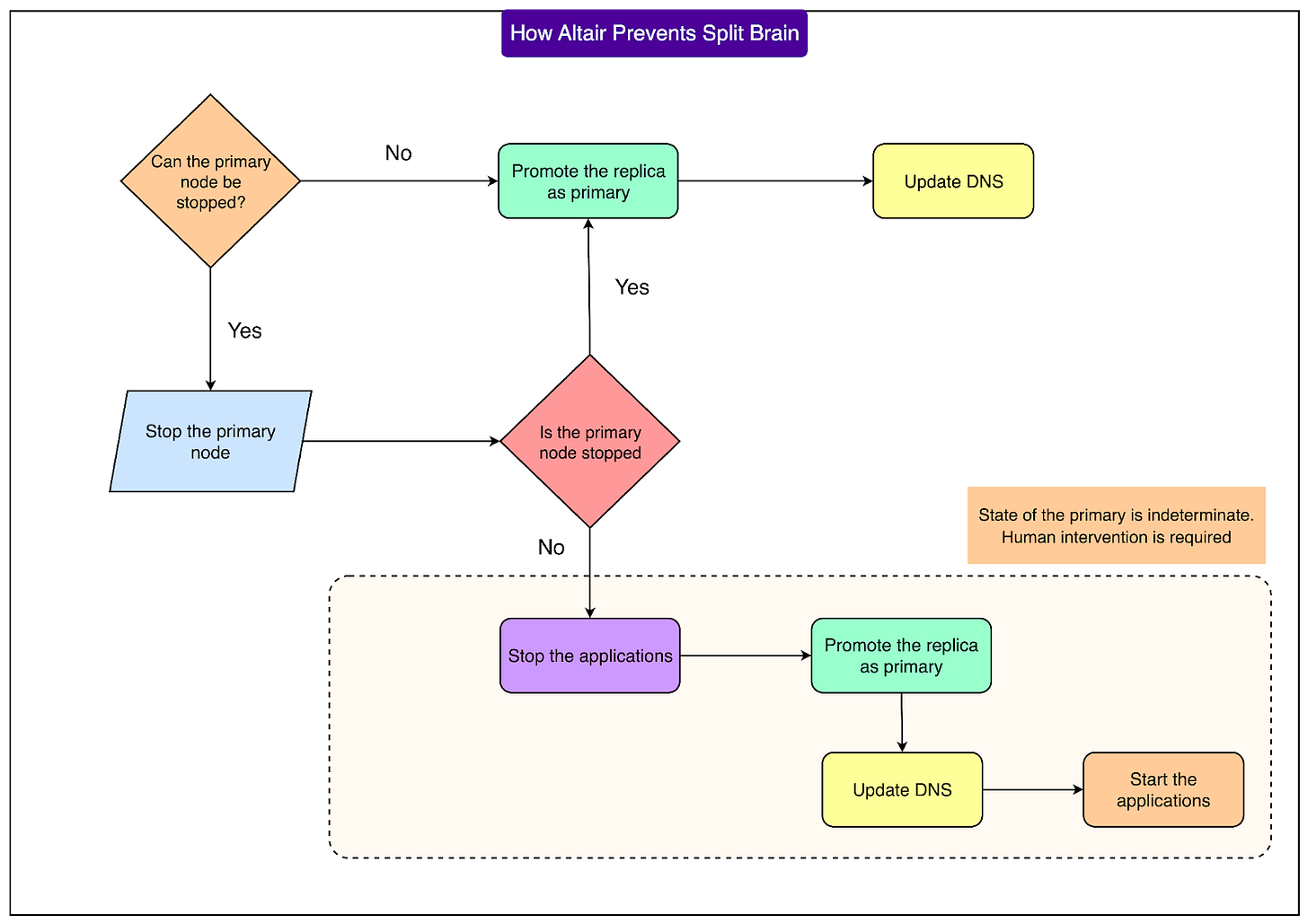
This meticulous process ensures that the risk of having two primaries is mitigated, even if it requires a brief, controlled pause in availability.
Failure Scenarios and How Altair Handles Them
Databases can fail in numerous ways, each requiring a tailored response. Altair is engineered to detect various failure scenarios and react appropriately to minimize downtime and protect data integrity. Let's examine the major cases and Altair's responses:
1. Node (Host) Failure
If the entire machine (virtual or physical host) running the primary database fails, the local agent on that machine ceases sending health updates. If the monitor misses three consecutive 10-second updates (approximately 30 seconds of silence), it flags the node as unhealthy and alerts the orchestrator. The orchestrator then verifies the node's unreachability and triggers a failover, promoting a replica to the new primary.
2. MySQL Process Failure
Even if the host machine is operational, the MySQL process itself might crash. In this situation:
- The agent reports that MySQL is down, while confirming the host's health.
- The monitor detects the discrepancy between host health and MySQL process health.
- The orchestrator double-checks and, upon confirmation, initiates the failover process.
3. Network Partition Between Primary and Replicas
Sometimes, the primary and replicas lose communication due to a network issue, even if both are individually healthy. Replicas lose connectivity to the primary. This alone is insufficient to trigger a failover, as Altair avoids acting on replica-only signals when the primary might still be healthy and reachable by clients.
4. Network Partitions Between the Control Plane and Primary
This scenario is more complex. Altair's control plane (monitor and orchestrator) might lose communication with the primary, while the primary itself remains operational. Altair carefully analyzes the situation to prevent false failovers, categorizing it into three sub-cases:
- Orchestrator cannot reach primary, but monitor can:
- The monitor continues to receive health updates from the agent.
- If the monitor detects a failure (e.g., a MySQL crash), it alerts the orchestrator.
- Despite the orchestrator's own failed pings, it trusts the monitor's updates.
- Failover may still occur if replicas are available, but Altair prioritizes fencing the primary before promotion.
- Monitor cannot reach primary, but orchestrator can:
- The monitor misses health updates and suspects primary failure.
- However, the orchestrator can still confirm the primary is alive and MySQL is running.
- In this case, Altair treats it as a false alarm and prevents an unnecessary failover.
- Both monitor and orchestrator cannot reach primary:
- This situation mimics a total primary failure.
- Altair proceeds with the failover process, fencing the old primary if possible before promoting a replica.
Design Highlights and Trade-Offs
Developing a system like Altair involves balancing several competing objectives. Flipkart's engineering team made deliberate choices regarding prioritization and design to ensure reliability at scale. Here are the key highlights and associated trade-offs:
Balancing Consistency and Availability
Altair’s MySQL setup uses asynchronous replication, meaning replicas copy data from the primary with a slight delay. This inherently involves a trade-off:
- Strong consistency: Requires waiting for every replica to acknowledge each write, which can degrade performance and availability during failures.
- High availability: Accepts the possibility of minimal data loss during failover if replicas haven't received the absolute latest writes.
Flipkart explicitly chose to prioritize availability. In practice, this implies that during an unplanned failover, a small number of the last transactions on the old primary might not propagate to the new primary. Altair mitigates this risk by enabling replicas to catch up on relay logs whenever possible and by implementing read-only modes during planned failovers before role switching. Nevertheless, in the event of unexpected crashes, a minor amount of data loss remains a possibility.
Smarter Health Checks
A core strength of Altair is its sophisticated approach to preventing false alarms. Rather than relying solely on a few missed signals, it leverages multiple sources of truth:
- The health status of the virtual machine,
- Connectivity between replicas and the primary, and
- Direct connectivity between the orchestrator and the primary.
This layered validation prevents disruptive, unnecessary failovers when the primary is actually healthy.
Simplified Service Discovery
Altair utilizes DNS indirection for seamless failovers. By updating the DNS record of the primary after a promotion, applications automatically connect to the new primary without requiring code changes or restarts in most scenarios. This design simplifies the system for developers building services atop Altair.
Scalable Monitoring Design
Altair's monitoring system is architected for scalability, accommodating Flipkart's growth:
- Agent: Collects health data from each node.
- Monitor: Processes data, stores it in ZooKeeper, and allows multiple instances to run in parallel, overseeing numerous clusters.
- Orchestrator: Makes final decisions and triggers failover when necessary.
This clear separation of responsibilities ensures both reliability and horizontal scalability.
Conclusion
Altair stands as Flipkart’s robust solution to the complex challenge of maintaining highly available relational databases at an enormous scale. By standardizing on a primary–replica setup with asynchronous replication, the engineering team has ensured that MySQL remains a dependable backbone for critical transactional systems. The system prioritizes write availability, while meticulously minimizing potential data loss through relay log catch-up and controlled read-only modes during planned failovers.
Altair’s layered monitoring architecture—integrating agents, monitors, ZooKeeper, and an orchestrator—enables reliable failure detection without false positives. Its DNS-based service discovery simplifies application integration, while fencing mechanisms and procedural safeguards effectively protect against the dangerous split-brain scenario. Furthermore, the system is designed to scale horizontally, supervising thousands of clusters across Flipkart’s extensive microservices landscape.
The fundamental trade-off made is accepting the possibility of minor data loss in exchange for rapid, automated recovery. This choice allows Altair to effectively balance consistency, availability, and operational simplicity, aligning perfectly with Flipkart’s demanding business requirements. In practice, this design has substantially reduced operational overhead and consistently delivered dependable high availability during peak events, solidifying MySQL’s role as a reliable foundation for Flipkart’s e-commerce platform.
References
- MySQL High Availability
- MySQL Enterprise High Availability