How Netflix Engineered a Distributed Write-Ahead Log for Data Platform Reliability
Explore how Netflix built a distributed Write-Ahead Log (WAL) system to ensure data reliability and consistency. This article details WAL's architecture, API, and key use cases, from delayed queues to cross-region replication.
Netflix processes an enormous volume of data every second. Each user interaction—from playing a show to rating a movie or receiving a recommendation—triggers complex operations across numerous databases and microservices. Maintaining consistency across these hundreds of independent systems is critical, as a failure in one can rapidly cascade throughout the entire platform.
Initially, Netflix's engineering teams faced recurring issues that jeopardized data reliability. These included accidental data corruption following schema changes, inconsistencies between storage systems like Apache Cassandra and Elasticsearch, and message delivery failures during transient outages. Bulk operations, such as large delete jobs, sometimes caused key-value database nodes to run out of memory. Furthermore, some databases lacked built-in replication, risking permanent data loss during regional failures.
Different engineering teams adopted varied approaches to these problems, with some building custom retry systems, others designing unique backup strategies, and some directly using Kafka for message delivery. While these individual solutions offered temporary fixes, they introduced significant complexity and inconsistent reliability guarantees across Netflix’s vast ecosystem. Over time, this fragmented approach escalated maintenance costs and complicated debugging efforts.
To address these systemic challenges, Netflix developed a sophisticated Write-Ahead Log (WAL) system. This WAL serves as a unified, resilient foundation for data reliability by standardizing how data changes are recorded, stored, and replayed across all services. Fundamentally, it captures every modification before it's applied to the actual database, ensuring no information is lost even if an operation fails midway through.
This article delves into how Netflix built this innovative WAL system and the specific challenges overcome during its development.
What is a Write-Ahead Log?
At its core, a Write-Ahead Log is a simple yet powerful concept: it’s a system that meticulously records every change intended for data before those changes are committed to the actual database. Imagine it as a comprehensive journal of all planned actions; should any process fail, the journal provides a complete record to resume operations precisely from where they left off.
Operationally, when an application seeks to update or delete data in a database, it first writes this intent to the WAL. Only after this entry is safely recorded does the database proceed with the requested operation. This mechanism ensures that if a server crashes or a network connection drops, Netflix can simply replay the operations from the WAL, restoring all systems to the correct, consistent state without any data loss.
Netflix's WAL is distinguished by being distributed and pluggable, meaning it operates across multiple servers to manage massive data volumes and can easily integrate with diverse technologies such as Kafka, Amazon SQS, Apache Cassandra, and EVCache. This flexibility allows the Netflix engineering team to apply a single, robust reliability framework to various workloads, whether caching video metadata, storing user preferences, or managing system logs.
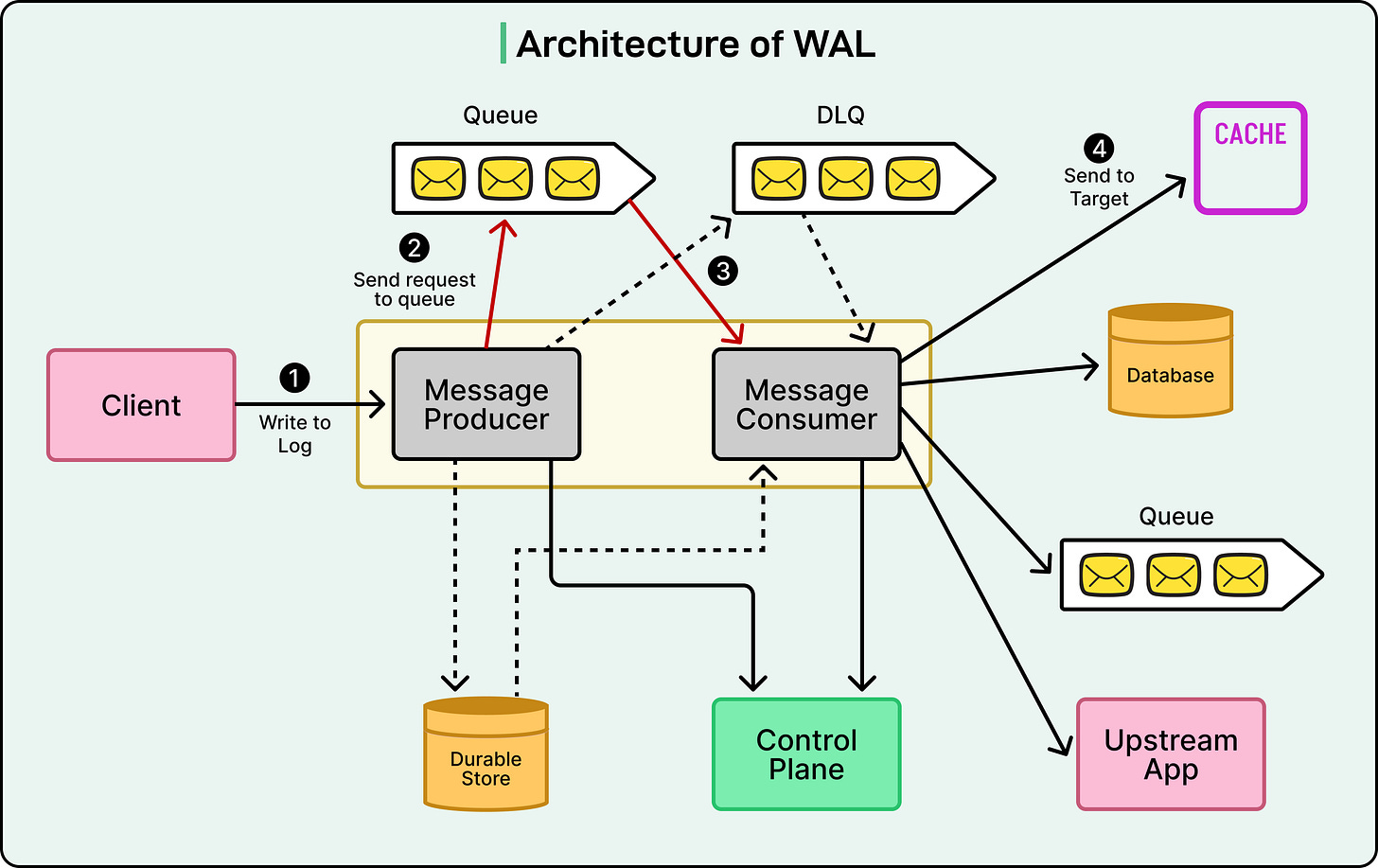
The WAL delivers several critical benefits, significantly enhancing the resilience of Netflix’s data platform:
- Durability: Every change is logged first, guaranteeing that no data is permanently lost, even if a database goes offline.
- Retry and Delay Support: If message processing fails due to an outage or network issue, the WAL can automatically retry it later, incorporating custom delays.
- Cross-Region Replication: Data can be copied across different geographical regions, ensuring identical information exists in multiple data centers for robust disaster recovery.
- Multi-Partition Consistency: For complex updates spanning multiple tables or partitions, WAL coordinates all changes to ensure eventual consistency across the entire system.
The WAL API
Netflix’s Write-Ahead Log system offers developers a straightforward interface. Despite the intricate processes occurring behind the scenes, the API primarily exposes a single main operation: WriteToLog.
This API serves as the gateway for any application intending to record a data change. Its structure typically looks like this:
rpc WriteToLog (WriteToLogRequest) returns (WriteToLogResponse);
While this appears technical, the concept is simple: a service sends a request to WAL detailing what it wants to write and its intended destination. WAL then processes, securely stores the request, and responds with information regarding the operation's success.
The WriteToLogRequest comprises four main components:
- Namespace: Identifies the logical group or application to which the data belongs, helping WAL organize and isolate data from different teams or services.
- Lifecycle: Specifies timing details, such as whether the message should be delayed or how long WAL should retain it.
- Payload: This is the actual data or content being written to the log.
- Target: Instructs WAL where to route the data after it has been safely recorded (e.g., a Kafka topic, a database, or a cache).
The WriteToLogResponse is equally concise:
- Durable: Indicates whether the request was successfully stored and made reliable.
- Message: Provides details if an error occurred, such as an error message or reason for failure.
Each namespace within WAL has a unique configuration dictating its behavior. For example, one namespace might be configured for high-speed streaming via Kafka, while another might rely on Amazon SQS for delayed message delivery. Engineering teams can fine-tune settings like retry counts, backoff times, and delay intervals to suit the specific needs of each application.
Different Use Cases of the WAL
Netflix designed the WAL system with flexibility in mind, supporting various operational scenarios referred to as 'personas' within the company’s data ecosystem. Each persona represents a distinct application of WAL to address specific needs.
Let’s explore a few primary examples to illustrate how this system adapts to different requirements.
1. Delayed Queues
This use case originated with the Product Data Systems (PDS) team, which handles extensive real-time data updates. In large-scale distributed systems like Netflix, failures are an inevitable reality. Downstream services, such as Kafka or databases, may occasionally become temporarily unavailable due to network issues or maintenance.
Instead of losing messages or requiring engineers to manually retry failed operations, WAL automatically intervenes. When a system failure occurs, WAL leverages Amazon SQS (Simple Queue Service) to temporarily delay messages and retry their delivery later.
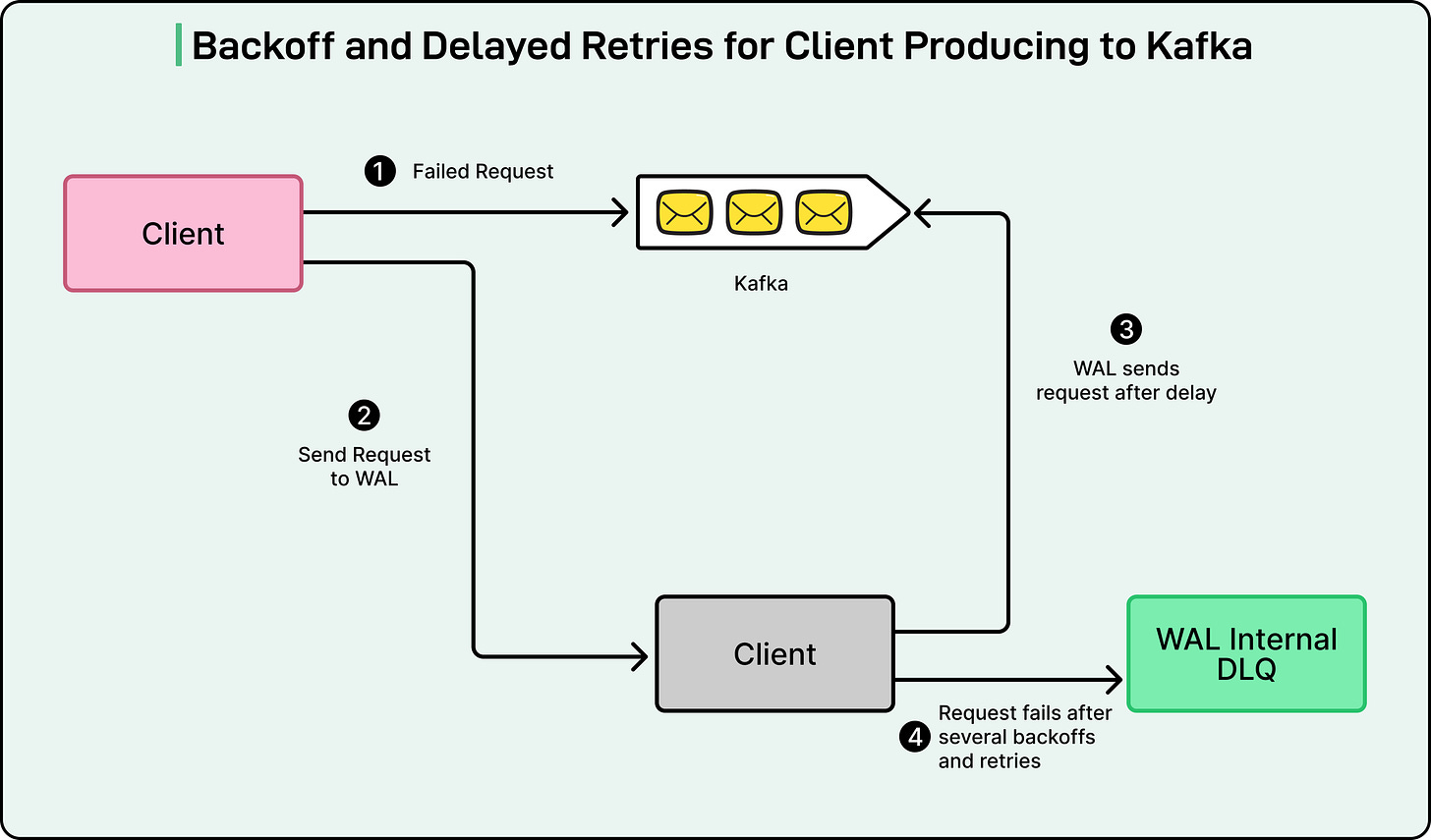
In essence, if a message fails to deliver, WAL stores it in a queue and waits for a predefined period before attempting delivery again. This delay can be customized based on the anticipated recovery time of the affected system. Once the downstream service is operational again, WAL automatically retries the messages, guaranteeing no data is lost and eliminating the need for manual intervention.
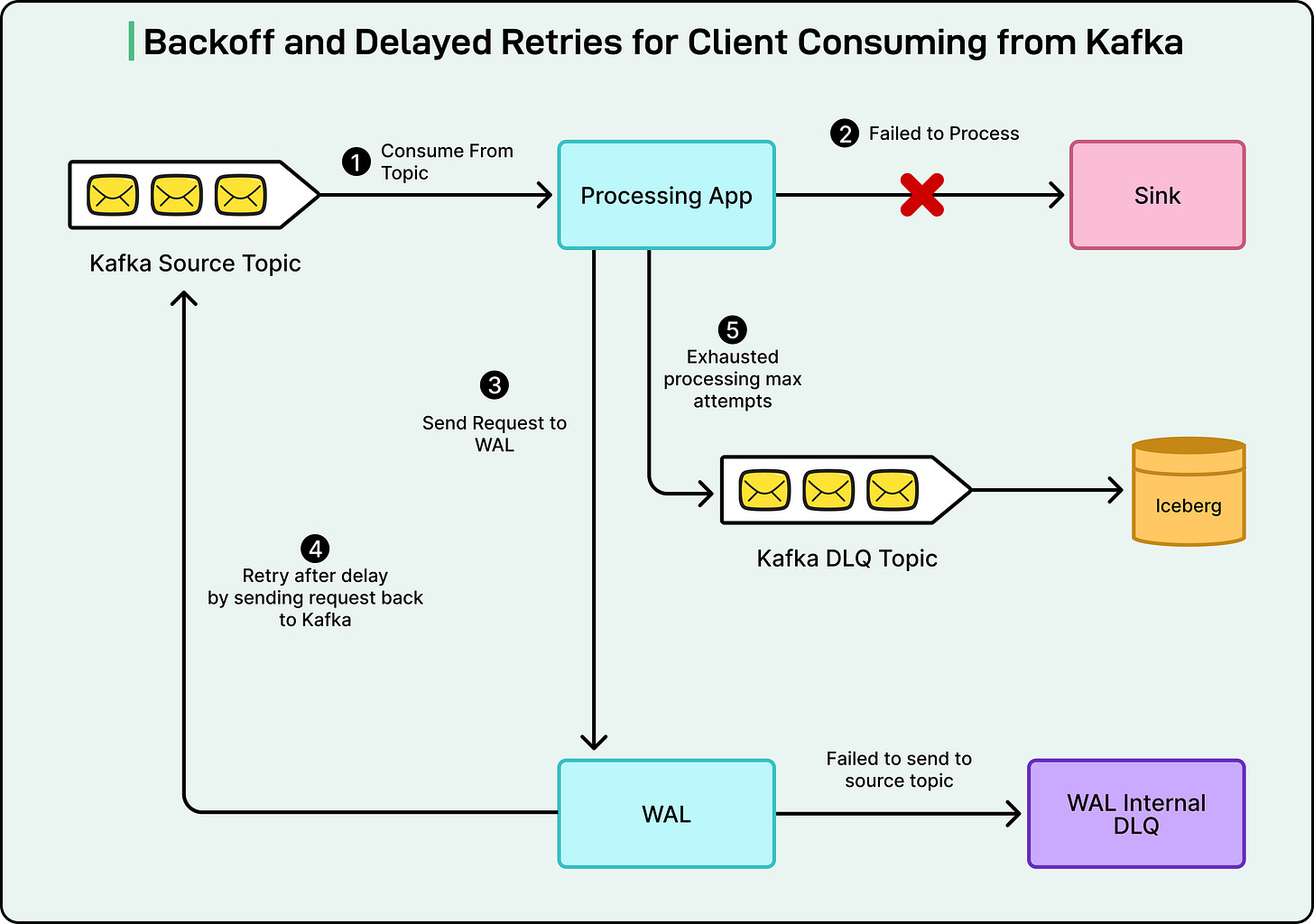
This strategy significantly reduces engineering effort and prevents cascading failures that could otherwise propagate across the platform.
2. Cross-Region Replication
Another critical application of WAL is data replication across Netflix's global regions. The company’s caching system, EVCache, stores frequently accessed data to ensure fast and reliable streaming. Given Netflix's worldwide operations, the same data must be consistently available in multiple regions.
WAL facilitates seamless replication by leveraging Kafka. Whenever data is written or deleted in one region, WAL captures that event and transmits it to other regions. Consumers in each receiving region then replay these operations locally, ensuring that all data copies remain synchronized globally.
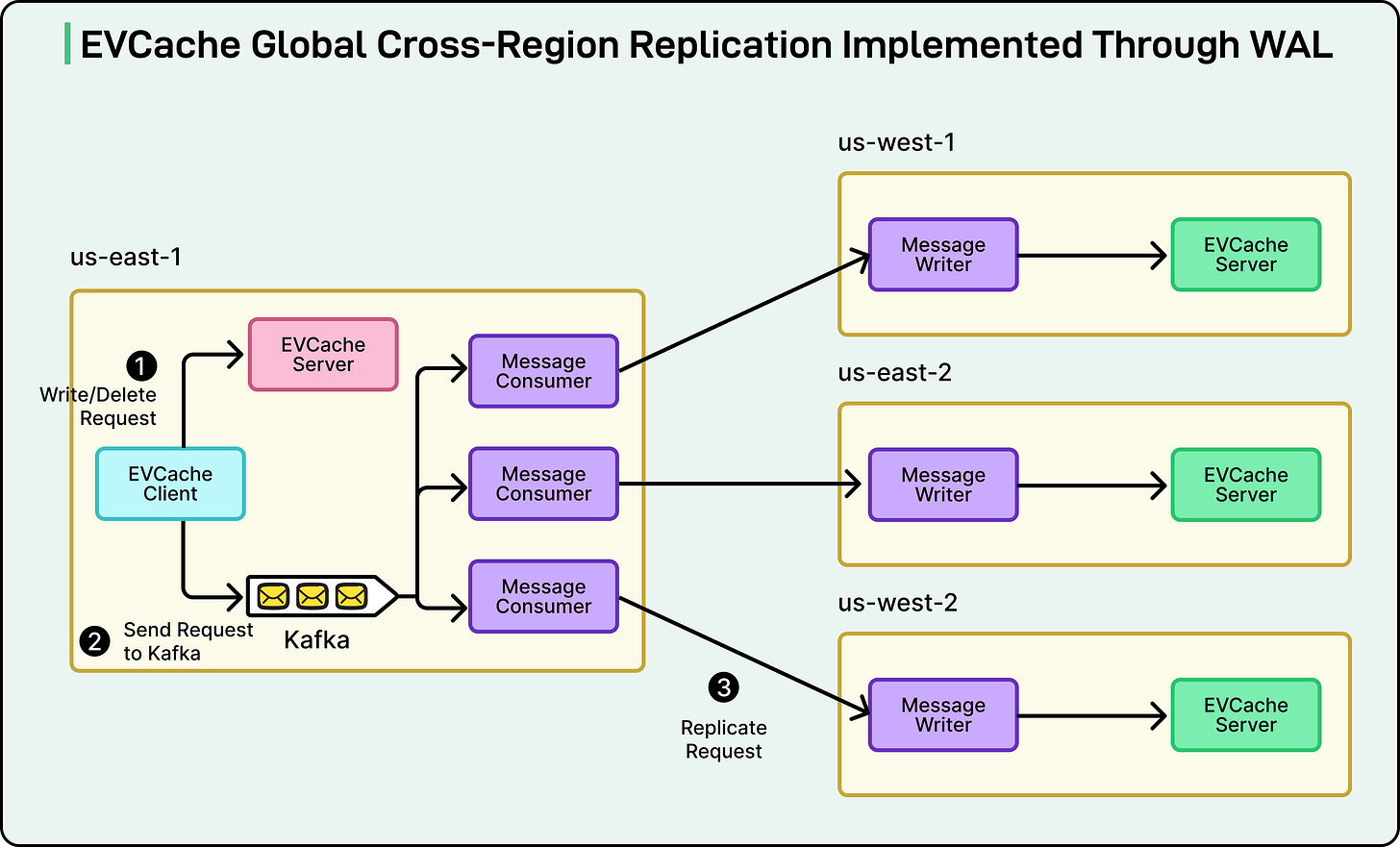
In simpler terms, WAL acts as a dependable messenger, guaranteeing that every region receives identical data updates, even amidst network disruptions. This system underpins Netflix's global consistency, ensuring users worldwide experience the same data at nearly the same time.
3. Multi-Partition Mutations
The final example pertains to Netflix’s Key-Value data service, which stores information in systems like Apache Cassandra. Occasionally, a single operation requires updating data spread across multiple partitions or tables. Managing these multi-part changes is particularly challenging in distributed environments, as a failure in one partition can leave others out of sync.
WAL resolves this by ensuring atomicity: either all changes succeed, or all are retried until completion. To achieve this, Netflix’s WAL combines Kafka for reliable message delivery with durable storage for data persistence. This setup functions similarly to a two-phase commit, a well-established database technique for guaranteeing data consistency across multiple locations.
In essence, WAL orchestrates complex updates, maintaining the correctness of Netflix's data even when multiple systems are involved.
Internal Architecture
To grasp the internal workings of Netflix’s Write-Ahead Log (WAL), it's helpful to examine its core building blocks.
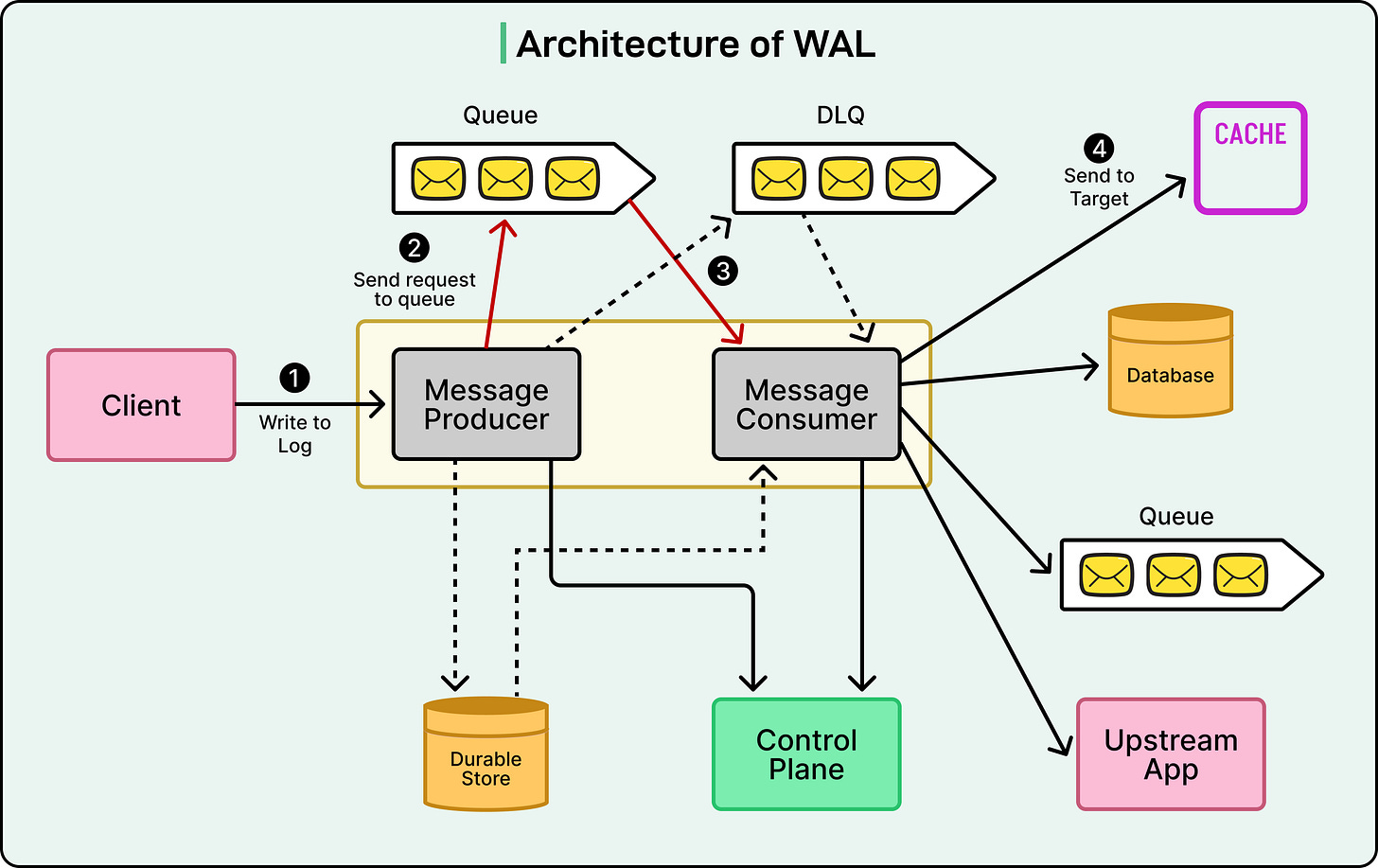
The system comprises several key components that collaborate to securely transport data while maintaining flexibility and resilience.
- Producers: These are the initial point of contact, accepting messages or data change requests from various Netflix applications and writing them into a queue. Producers act as the 'entry doors' of WAL; applications hand data to a producer, which ensures it's safely added to the correct queue.
- Consumers: Functioning as the 'exit doors,' consumers read messages from the queue and route them to their designated destinations, such as a database, cache, or another service. Operating independently from producers, consumers can process messages at their own pace without bottlenecking the rest of the system.
- Message Queues: This is the intermediary layer connecting producers and consumers. Netflix primarily utilizes Kafka or Amazon SQS for this purpose. Each WAL namespace (representing a specific use case or service) has its own dedicated queue, ensuring isolation and preventing heavy workloads from one service from impacting others. Every namespace also includes a Dead Letter Queue (DLQ)—a special backup queue that stores messages that repeatedly fail to process, allowing engineers to inspect and resolve problematic data without loss.
- Control Plane: The control plane acts as WAL's central command center, enabling Netflix engineers to modify settings such as queue type, retry counts, or delay intervals. A significant advantage is that these configurations can be adjusted without altering application code, making the system highly adaptable and easy to maintain.
- Targets: Finally, targets are the ultimate destinations where WAL dispatches the data. A target can be a database like Cassandra, a cache like EVCache, or even another message queue. This configuration-driven flexibility allows a single WAL architecture to support a multitude of different workloads across Netflix.
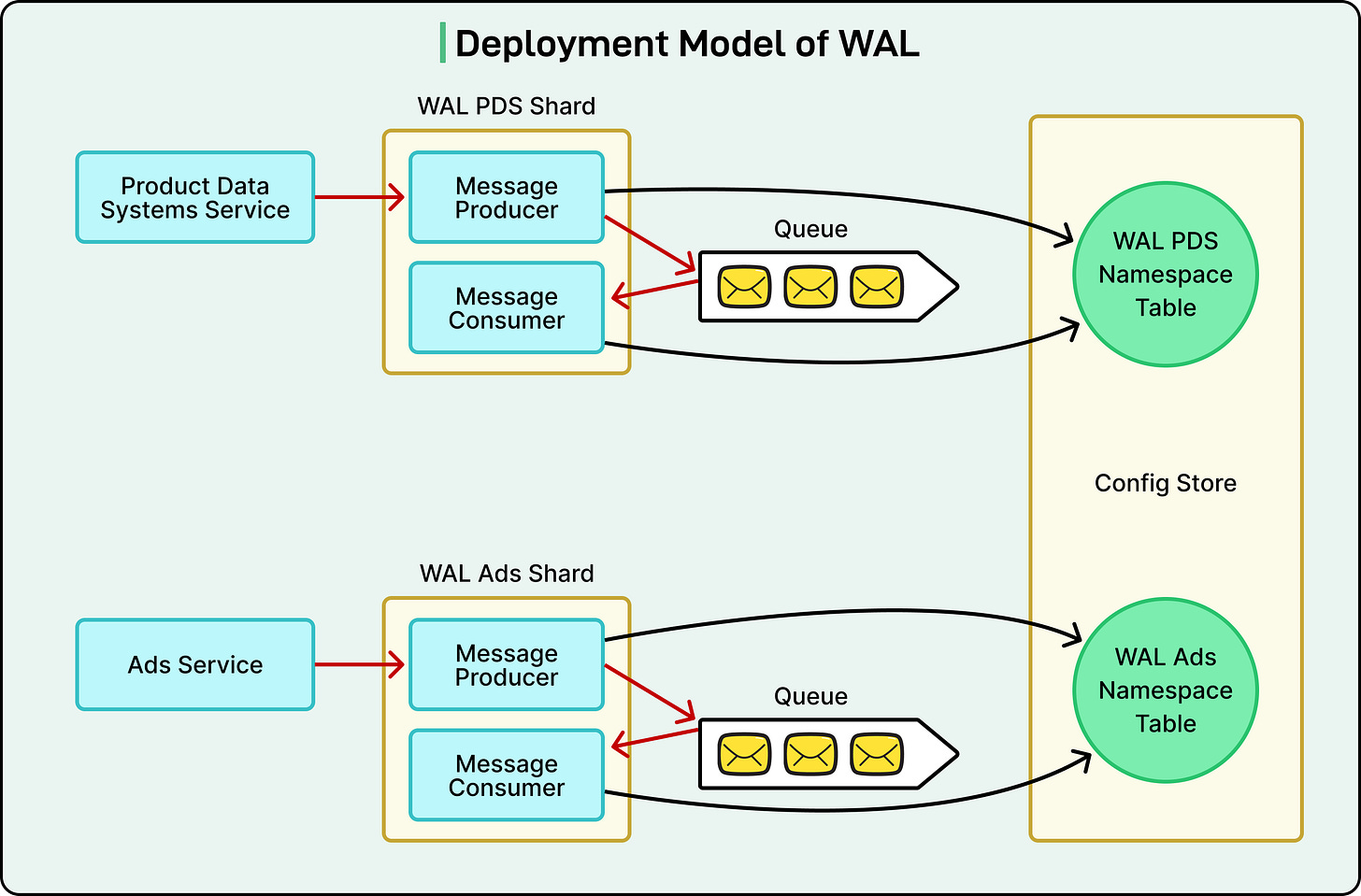
Deployment Model
The deployment strategy for Netflix’s Write-Ahead Log (WAL) system is as crucial as its internal architecture. To manage billions of data operations across numerous teams and services, Netflix required a platform capable of effortless scaling, robust security, and reliable multi-region operation. Consequently, WAL is deployed atop Netflix’s Data Gateway Infrastructure.
This underlying infrastructure provides WAL with several inherent advantages:
- mTLS for Security: All inter-service communication is encrypted and authenticated using mutual Transport Layer Security (mTLS), ensuring that only trusted Netflix services can interact, thereby safeguarding sensitive data.
- Connection Management: The platform automatically manages network connections, optimizing request routing and preventing any single component from being overloaded.
- Auto-scaling and Load Shedding: WAL employs adaptive scaling, dynamically adjusting the number of active instances based on demand. If CPU or network usage becomes excessively high, the system automatically provisions additional capacity. In extreme situations, it can also shed low-priority requests to preserve service stability.
Netflix organizes WAL deployments into shards—independent deployments dedicated to serving specific groups of applications or use cases. For instance, one shard might manage the Ads service, another gaming data, and so forth. This compartmentalization mitigates the 'noisy neighbor' problem, preventing a busy service from degrading the performance of others sharing the same system.
Within each shard, multiple namespaces can exist, each with its own configuration and purpose. These configurations are stored in a globally replicated SQL database, ensuring their constant availability and consistency, even if a region experiences an outage.
Conclusion
The success of Netflix’s WAL is attributed to several key design principles. Firstly, its pluggable architecture enables seamless switching between diverse technologies like Kafka or Amazon SQS without requiring application code changes. This flexibility empowers teams to select the optimal underlying system for their specific use cases while relying on a consistent core framework.
Secondly, the strategic reuse of existing infrastructure was paramount. Instead of building from scratch, Netflix integrated WAL on top of established systems, such as the Data Gateway platform and Key-Value abstractions. This approach not only accelerated development but also ensured the new system harmonized naturally with the company’s broader data architecture.
Equally vital is the clear separation of concerns between producers and consumers. This independence allows these components to scale separately, enabling Netflix to adjust each based on traffic patterns or system load. Such autonomy is crucial for WAL to manage massive demand spikes without service degradation.
Finally, Netflix acknowledges that even systems designed for high reliability must account for their inherent limits. The engineering team continuously evaluates trade-offs, addressing challenges like slow consumers or managing backpressure during periods of heavy traffic. Techniques such as partitioning and controlled retries are indispensable for maintaining system stability.
Looking forward, Netflix plans further enhancements to WAL, including adding secondary indices to the Key-Value service for faster, more efficient data retrieval, and supporting multi-target writes, which will allow a single operation to send data to multiple destinations simultaneously (e.g., a database and a backup system).