How PayPal Engineered JunoDB: A Deep Dive into its Architecture and Design
Uncover PayPal's JunoDB, an open-sourced, high-availability distributed key-value store. Explore its architecture, unique design choices beyond Redis, and critical use cases.
PayPal recently open-sourced their internal key-value store called JunoDB. According to PayPal's claims, JunoDB boasts an exceptional six-nines (99.9999%) availability. This translates to a mere 86.40 milliseconds of downtime per day, an interval shorter than an average human eye blink (100 milliseconds). Such impressive reliability highlights the sophisticated design and architecture from which we can learn significantly.
JunoDB Facts
Before delving deeper, here are some key facts about JunoDB and its role at PayPal:
- JunoDB is a distributed key-value store developed in Go.
- It processes an astounding 350 billion requests daily at PayPal.
- It is integrated into nearly all core back-end services, including critical functions like login, risk management, and transaction processing.
- Primarily, JunoDB serves as a caching layer, not a source-of-truth database. Its main objective is to alleviate the load on PayPal's primary relational database.
The illustration below demonstrates JunoDB's position within the overall system architecture:

While this all sounds exciting, a fundamental question arises: "Why didn't PayPal simply use an existing solution like Redis? Why re-invent the wheel?"
Why Not Redis?
The primary reason was PayPal's specific requirement for multi-core support. Redis is single-threaded by design, meaning it utilizes only one CPU core regardless of how many are available. To scale Redis across multiple cores, one typically needs to launch several Redis instances.
This isn't inherently a flaw for Redis, as its performance is generally memory-bound rather than CPU-bound.
Understanding Memory-Bound vs. CPU-Bound:
These terms refer to different performance bottlenecks:
- Memory-bound programs are limited by the amount of available memory.
- CPU-bound programs are constrained by the processing power of the CPU.

Redis stores data predominantly in RAM and is highly optimized for in-memory access. When data exceeds available RAM, increased disk swapping occurs, which can degrade performance. Thus, for Redis, system memory, not the CPU, is typically the limiting factor.
Initially, JunoDB also began as a single-threaded C++ program, intended as an in-memory store for short Time to Live (TTL) data. TTL defines the maximum duration data remains valid.
However, JunoDB's goals evolved significantly. First, it transitioned into a persistent data store supporting long TTLs. Second, it needed to offer enhanced data security through on-disk encryption and TLS in transit by default.
Features like encryption are inherently CPU-intensive, as cryptographic algorithms demand substantial processing power for complex mathematical computations. This shift meant JunoDB needed to become CPU-bound rather than memory-bound. Consequently, it was entirely rewritten in Go to achieve high concurrency and full multi-core compatibility.
JunoDB Architecture
Here's a high-level overview of JunoDB's architecture:

Let's examine the main components:
1. JunoDB Client Library
Part of the client application, this library provides an API for storing and retrieving data via the JunoDB proxy. Available in multiple languages (Java, C++, Python, Golang), it simplifies integration for developers.
2. Load Balancer and JunoDB Proxy
JunoDB employs a proxy-based design offering several advantages:
- It abstracts the complexity of query routing from the client libraries. As a distributed data store, JunoDB spreads data across servers, and the proxy intelligently directs requests to the correct server.
- The proxy also maintains awareness of the JunoDB cluster configuration, including shard mappings, which are stored in
etcd.
To prevent the JunoDB Proxy from becoming a single point of failure (SPOF), it runs on multiple instances situated downstream of a load balancer. The load balancer receives incoming client requests and distributes them among the appropriate proxy instances.
3. JunoDB Storage Servers
These instances accept operation requests from the proxy and store data in memory or persistent storage using RocksDB. RocksDB is an embedded key-value storage engine known for its high read and write throughput. JunoDB leverages RocksDB internally, a common practice in database development to avoid building everything from scratch. Each storage server manages a group of shards (or partitions) for efficient data distribution and management.
Where Can You Use JunoDB?
With PayPal's decision to open-source JunoDB, it's now accessible for broader use. Here are some use cases where JunoDB excels:
1. Caching
JunoDB is ideal for use as a temporary cache for data that doesn't frequently change. Supporting both short and long-lived TTLs, it can store data for durations ranging from seconds to days. For example, short-lived tokens, user preferences, account details, and API responses can be efficiently cached here, reducing reliance on the main database. (For more on caching, refer to SDC#17 - Database Caching Strategies.)
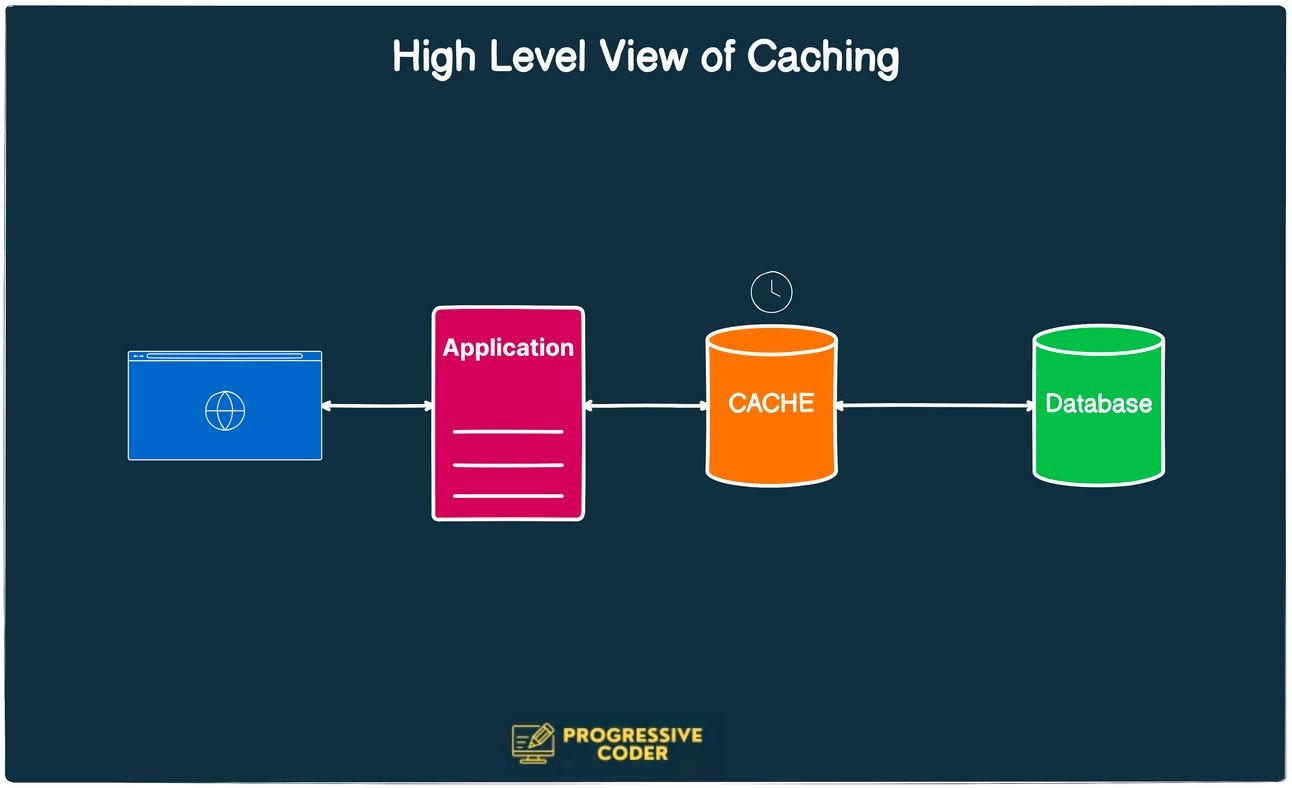
2. Idempotency
JunoDB can be effectively used to implement idempotency. An idempotent operation produces the same result regardless of how many times it is applied. This ensures safety when repeating operations, preventing issues like duplicate payments.
PayPal, for instance, uses JunoDB to prevent processing payments multiple times due to retries. Its high availability makes it an excellent data store for tracking processing details without burdening the main database.
3. Counters
For resources with limited availability or access constraints (e.g., database connections, API rate limits, user authentication attempts), JunoDB can store and manage counters. This allows tracking usage and ensuring limits are not exceeded.
4. Latency Bridging
JunoDB offers extremely fast inter-cluster replication, which can mitigate the slower replication often found in traditional setups. For example, PayPal runs Oracle in an Active-Active mode, but its replication latency can lead to inconsistent reads if records written in one data center haven't yet replicated to another.
JunoDB can bridge this latency. You can write to both Oracle and JunoDB in Data Center A. Even if Data Center A becomes unavailable, updates can be consistently read from the JunoDB instance in Data Center B.
See the illustration below for a clearer understanding:

P.S. This post is inspired by the explanation provided on the PayPal's engineering blog. Some details have been inferred, and diagrams have been drawn or re-drawn for clarity based on the shared information. You can find the original article here.
Shoutout
Here are some interesting articles I read this week:
- "I’m Making Myself Replaceable" by Akos Komuves
- "Caching in Distributed Systems - Part I" by Franco Fernando
- "What is A2A (Agent to Agent) Protocol" by Fran Soto
That's it for today! ☀️