Improving DNS Performance with NodeLocalDNS in Kubernetes
Discover how implementing NodeLocalDNS in Kubernetes clusters significantly reduces DNS tail latencies, optimizes traffic load, and enhances performance for large-scale Postgres deployments.
At Neon, we operate hundreds of thousands of Postgres databases as ephemeral Kubernetes pods. Our scale-to-zero feature means that every user connection to their database may necessitate spinning up a new Postgres process.
The newly launched Postgres instance requires configuration to serve the specific database for that user. In our architecture, the Postgres instance retrieves this information from the Neon control plane. As we scaled the number of Postgres instances in our AWS EKS clusters, we observed a linear increase in traffic to CoreDNS pods with the number of active Postgres instances, as anticipated.
There were no indications of suboptimal DNS performance, and resource usage increased proportionally with the load.
Given that over 95% of DNS requests were cache hits at the central CoreDNS pods, an opportunity arose to offload the majority of this traffic from the network. This could be achieved by distributing the DNS cache, balancing slightly increased memory usage against significantly reduced DNS latency. This article details the deployment of NodeLocalDNS across our infrastructure, outlining the benefits realized and the key lessons learned.
NodeLocalDNS: A Brief Overview
In popular managed Kubernetes setups (e.g., AWS EKS or Azure AKS), when a Pod performs a DNS lookup, the request is sent to the kube-dns Service ClusterIP and ultimately delivered to one of several CoreDNS pods running somewhere in the cluster.
This configuration introduces a network round-trip to the CoreDNS pod, directly increasing latency and potentially leading to network throttling. Throttling can cause application-layer errors that require retries, further exacerbating latency. NodeLocalDNS addresses both these concerns by running a DNS cache locally on each node.
For a self-contained discussion, we will briefly cover NodeLocalDNS deployment. Readers interested in further details are encouraged to consult external resources such as Kubernetes.io, Huawei, Tigera, and T-Systems.
Architecture
NodeLocalDNS operates as a CoreDNS caching instance, deployed as a DaemonSet on each node. It injects a virtual network interface onto the node and binds the kube-dns service IP address to it. This design transparently redirects packets intended for the kube-dns service to the local caching instance, effectively making it a transparent proxy. Consequently, Pod DNS configurations remain unchanged, enabling live activation and deactivation of NodeLocalDNS within a cluster.
The deployment template also defines a distinct kube-dns-upstream service, functionally identical to kube-dns but with a separate IP address not bound to a local interface. This ensures the caching instance can still reach the central CoreDNS pods.
Deployment
While various deployment solutions for NodeLocalDNS exist, including Helm charts, we opted for the template provided by the official cluster add-on, utilizing substitutions recommended in the Kubernetes documentation. Notably, this template upgrades the connection from the local DNS cache to the CoreDNS pods to use TCP (force_tcp). This specific detail proved crucial to a lesson learned during the deployment, which will be discussed further below.
We performed a gradual rollout across our production fleet after testing functional correctness and performance in a staging environment.
Performance Gains
The observed results aligned with, and in some instances surpassed, performance trends reported by Azure AKS and Mercari.
Tail Latency
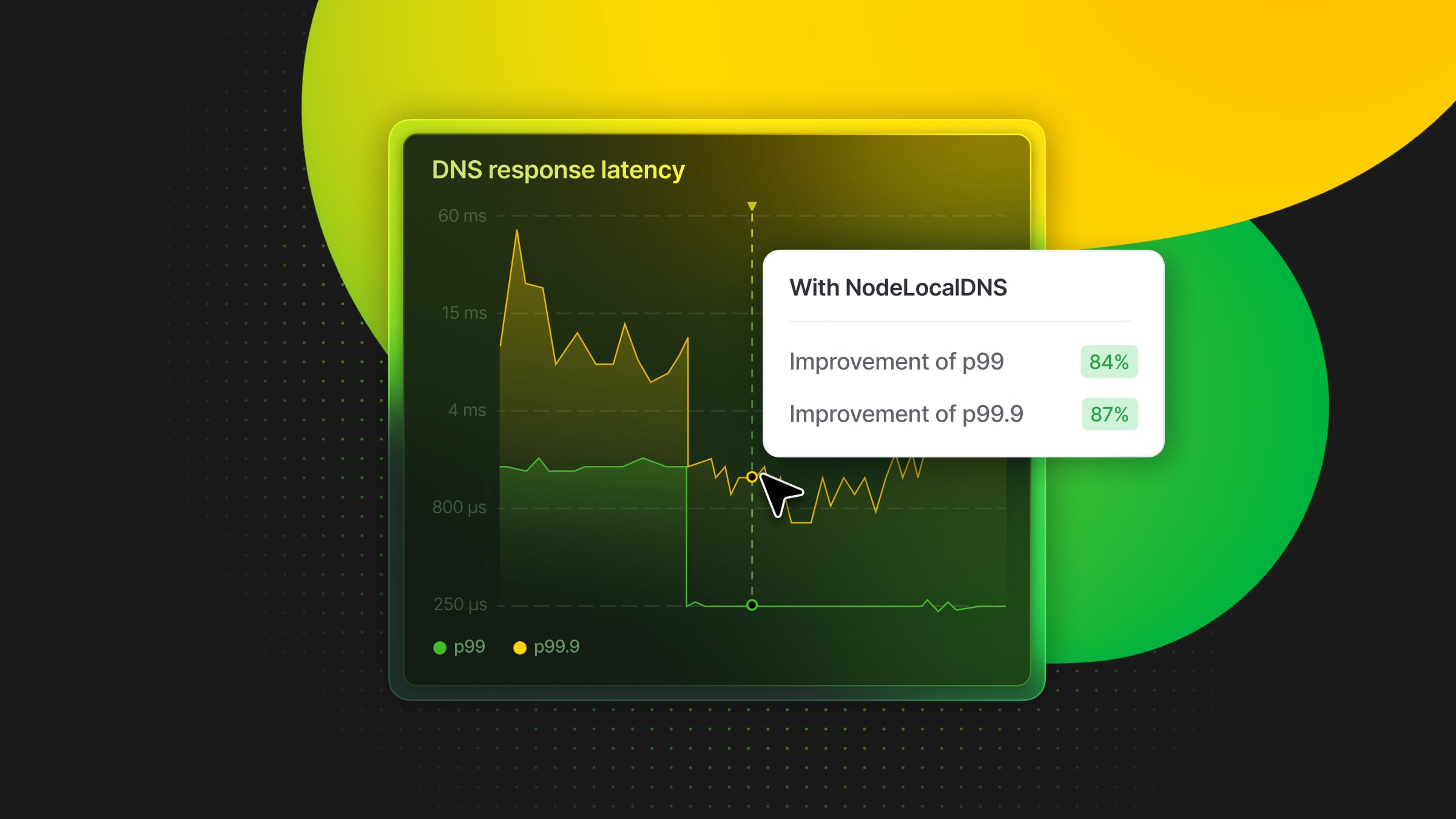
The most immediate impact was a significant reduction in DNS response tail latency at the CoreDNS pods. Prior to NodeLocalDNS implementation, our 90th percentile DNS response time was approximately 220µs, the 99th percentile was around 1.5ms (roughly 8x the 90th percentile), and the 99.9th percentile varied between 10ms and 20ms (averaging about 10x the 99th percentile).
Following deployment, the 90th percentile remained largely consistent, while the 99th percentile decreased to 240µs (an 84% improvement), and the 99.9th percentile dropped to less than 2ms (an 87% improvement).
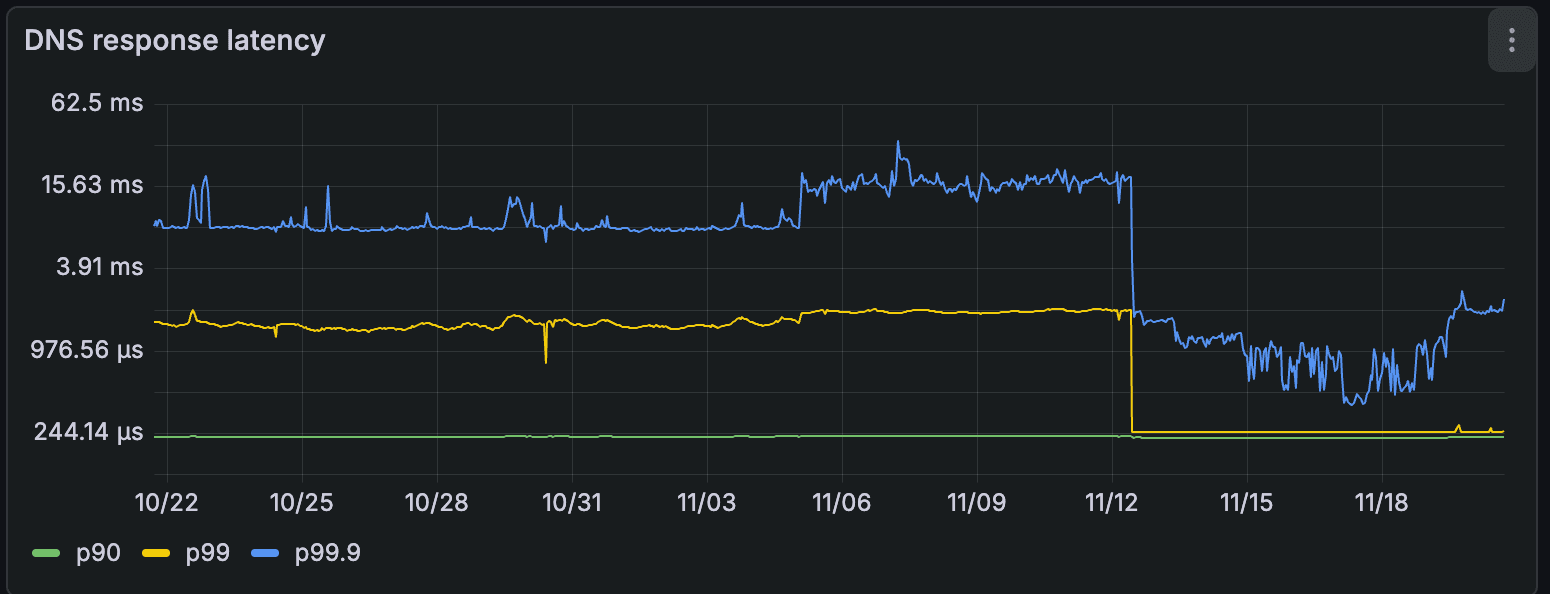
The cache hit rate at the central CoreDNS pod consequently decreased to approximately 30%, signifying that the vast majority of cache hits were now directly served at the nodes, thereby eliminating network round-trips for frequent lookups.
Traffic Load Reduction
As observed in various contexts, serving the majority of DNS requests directly on the node also substantially reduces the load on central CoreDNS pods. Our CoreDNS pods saw a dramatic reduction from approximately 2,000 requests/second to around 60 requests/second, a 97% decrease.
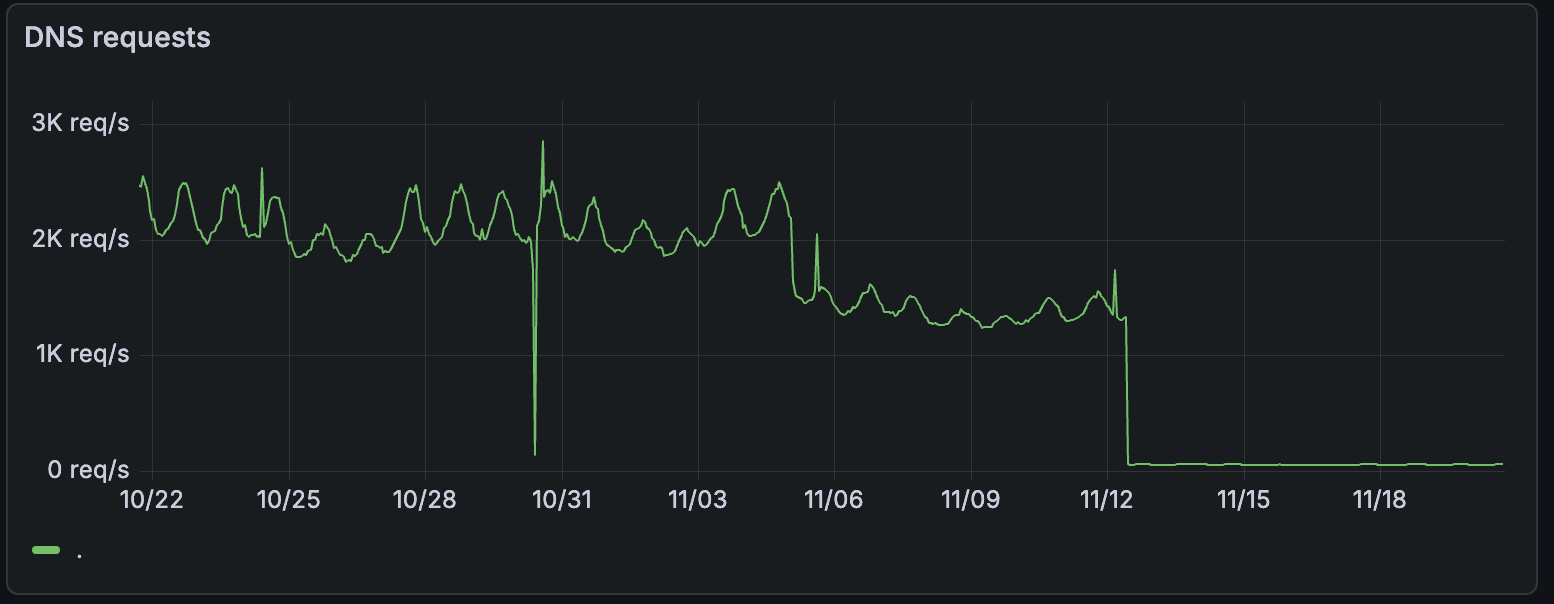
Crucially, beyond the immediate reduction, the number of DNS requests traversing the network now scales with the number of nodes rather than the number of Postgres instances.
Leaks and Amplification Mitigation
An unexpected advantage emerged from the significantly reduced load: it became far easier to inspect DNS traffic at the individual request level. This granular insight revealed a surprising pattern of NXDOMAIN responses, which were subsequently traced back to leaking requests caused by a misconfiguration in the /etc/hosts file. These misbehaving requests often amplify as the resolving library, upon receiving NXDOMAIN responses, sequentially explores domains in the DNS search list (as documented in resolv.conf(5)).
NodeLocalDNS not only facilitated the initial identification of this problem but also offered a rapid mitigation strategy. The CoreDNS version within the NodeLocalDNS image includes several CoreDNS plugins, notably the template plugin. This plugin allows for crafting direct responses to specific requests within the configuration file. We leveraged this capability to swiftly blackhole the problematic requests directly at the node, eliminating network round-trips, even for cache misses.
template IN A {
match "__THE_BAD_NAME__"
rcode NXDOMAIN
fallthrough
}
Ultimately, the misconfiguration in the affected images' /etc/hosts file was identified and corrected. However, the ability to rapidly drop this problematic traffic at the network edge proved to be an unexpected but significant benefit of NodeLocalDNS.
Lessons Learned
The deployment process was not without challenges. A notable failure mode observed in our busiest clusters involved error messages similar to the following:
[ERROR] plugin/errors: 2 REDACTED.default.svc.cluster.local. AAAA: dial tcp 172.20.XXX.XXX:53: i/o timeout
(172.20.XXX.XXX represents the kube-dns-upstream service's ClusterIP.)
Notably, this error message is only logged because the force_tcp option in the configuration file mandates a TCP connection to kube-dns-upstream. Unlike UDP, where connection timeouts are indistinguishable from query timeouts, TCP allows for clearer error differentiation. This error, therefore, pointed to a communication issue with the CoreDNS pods rather than an inability of the CoreDNS pods to service requests.
We observed a spike in similar errors logged by a few nodes in our cluster. One particularly problematic node displayed this pattern for several seconds before eventually self-healing.
The temporary unavailability of kube-dns-upstream stemmed from an inherent race condition: kube-proxy installing iptables rules to make the ClusterIP reachable versus the NodeLocalDNS Pod attempting to forward requests to it. Although the NodeLocalDNS manifest creates both the Service and DaemonSet objects, there's no guarantee that kube-proxy will have configured the iptables rule for the Service before the Pod tries to connect. In most common scenarios, this race resolves quickly and unnoticed. However, on problematic nodes, the time required for kube-proxy to install iptables rules was abnormally high, attributed to a difference in the default iptables backend.
A key takeaway is that this race condition can be entirely circumvented by deploying the Service first, followed by the DaemonSet. This approach is recommended for environments experiencing high kube-proxy sync delays or for those prioritizing maximum deployment stability.
Interestingly, Cilium employs a different strategy, decoupling traffic steering from DaemonSet deployment. For Cilium users, the recommended deployment order is reversed: deploy the DaemonSet first (without node networking stack access), and then apply a Local Redirect Policy to redirect traffic destined for kube-dns on port 53 to the local DaemonSet's listening address.
Conclusion
Deploying NodeLocalDNS represents one of the most effective and straightforward actions to significantly improve latency within a Kubernetes cluster. Its implementation dramatically reduced our tail latency and provided invaluable insights into our DNS traffic patterns.
For organizations operating Kubernetes at scale, NodeLocalDNS is a highly recommended optimization. When utilizing kube-proxy, it is advisable to closely monitor its performance metrics during the gradual rollout of NodeLocalDNS.