Mastering Event-Driven Architecture: Patterns and Best Practices for Scalable Systems
Explore core patterns like Event Notification, Event-Carried State Transfer, Event Sourcing, Choreography, and Orchestration. Learn best practices including idempotency, durable streams, explicit versioning, and correlation IDs to build robust, scalable, and maintainable event-driven systems.
Event-driven architecture (EDA) empowers teams to construct decoupled, scalable systems capable of independent evolution. Building on a previous discussion that introduced EDA through a restaurant analogy – where teams place "dockets" on a rail instead of shouting instructions, and stations pick what they need – this article continues that analogy subtly while delving into the practical engineering patterns essential for successful event-driven systems.
Core Patterns in Event-Driven Architecture
Pattern 1: Event Notification
An event notification is a concise message that simply signals "something happened." It provides minimal details—just enough for downstream systems to acknowledge and react.
Consider it akin to a kitchen bell ringing: the bell itself doesn't carry the meal; it's merely a signal. The cook still needs to consult the order rail (the database) to retrieve the specifics of order 12345.
Example
{
"eventName": "OrderCreated",
"orderId": 12345,
"createdAt": "2025-11-26T01:00:00Z"
}
Benefits
- Extremely lightweight
- Simple to publish and fan out
- Consumers retain control over fetching additional data they require
Trade-offs
- Consumers must independently fetch full details
- Increases cross-service calls, potentially leading to tighter coupling
- Can introduce higher latency when multiple consumers query upstream systems
This pattern is ideal when an event serves as a simple trigger—more like a signal bell than a comprehensive meal.
Pattern 2: Event-Carried State Transfer (ECST)
In Event-Carried State Transfer, the event payload includes all necessary data, eliminating the need for consumers to make additional calls.
This is comparable to a chef not only ringing the bell but also directly placing the complete plated dish on the pass. No further questions are required; everything needed is immediately available.
Example
{
"eventName": "OrderPacked",
"orderId": 12345,
"items": [
{ "sku": "ABC123", "qty": 2 }
],
"warehouseId": 19,
"totalWeightGrams": 1850
}
Benefits
- Eliminates back-calls, leading to full decoupling
- Highly resilient: consumers can process events even if upstream systems are unavailable
- Achieves faster pipelines with fewer dependencies
Trade-offs
- Larger event payloads may consume more bandwidth and storage
- Requires more meticulous schema management
- Potential impact on latency and throughput in very high-volume streams
Essentially, you're "pre-plating" the data, which incurs more effort upfront but significantly saves time downstream.
Pattern 3: Event Sourcing
Instead of merely storing the current state, Event Sourcing persists every change as an immutable event. The system's state can then be reconstructed by replaying this sequence of events.
Much like a kitchen's comprehensive order history narrates the complete story of a service period, event sourcing provides a full timeline of every state alteration.
Example (C# Aggregate Rehydration)
var events = eventStore.LoadStream("Order-12345");
var order = OrderAggregate.Rehydrate(events);
Benefits
- Provides a perfect audit trail
- Enables "time-travel debugging"
- Offers the ability to replay events for recovery or sophisticated analytics
Trade-offs
- Higher cognitive load for new team members
- Demands rigorous event versioning
- Requires maintaining projections or read models
CQRS Note
Event Sourcing is frequently paired with Command Query Responsibility Segregation (CQRS), which separates commands (writes) from queries (reads).
This is akin to chefs focusing on cooking in the kitchen while waitstaff manage menus, tables, and customer-facing interactions. Each side optimizes for its specific responsibilities.
Pattern 4: Choreography (Decentralized Workflow)
With choreography, services react to each other's events without a central coordinator. The workflow is decentralized.
It's like a well-coordinated kitchen crew: when the grill station finishes cooking a steak, the garnish station inherently knows it's their cue to start, without any direct instructions being shouted.
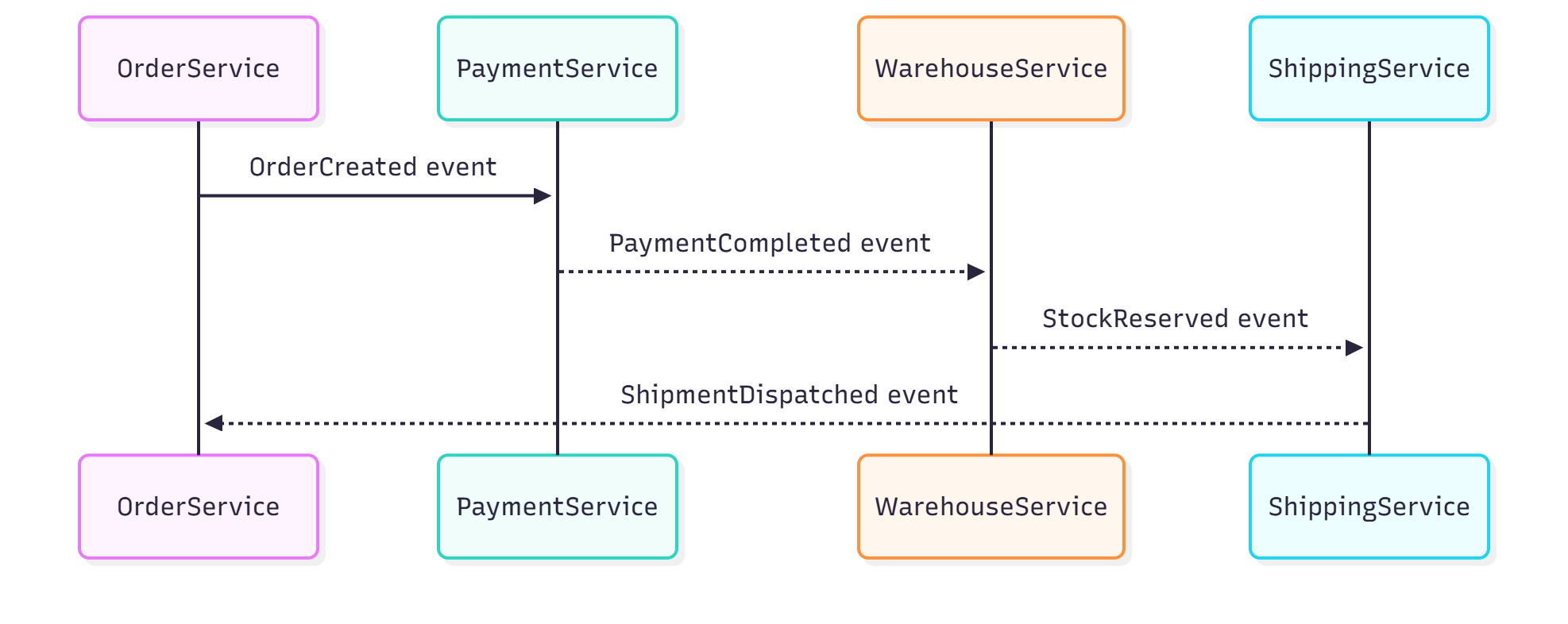
Benefits
- Achieves full decoupling between services
- Naturally scalable
- Easy for new services to integrate by simply subscribing to relevant events
Drawbacks
- Can be challenging to visualize the entire workflow
- Risk of "event spaghetti" if not carefully managed
- Difficult to enforce global ordering or handle complex cross-service failures
This pattern excels for simpler flows where each service independently understands its next action.
Pattern 5: Orchestration (Service Composer / Workflow Engine)
Orchestration introduces a conductor—a central service that explicitly coordinates each step of a workflow.
Think of a head chef calling out the specific steps during the preparation of a complex dish:
- "Start the sauce."
- "Grill the chicken."
- "Plate it."
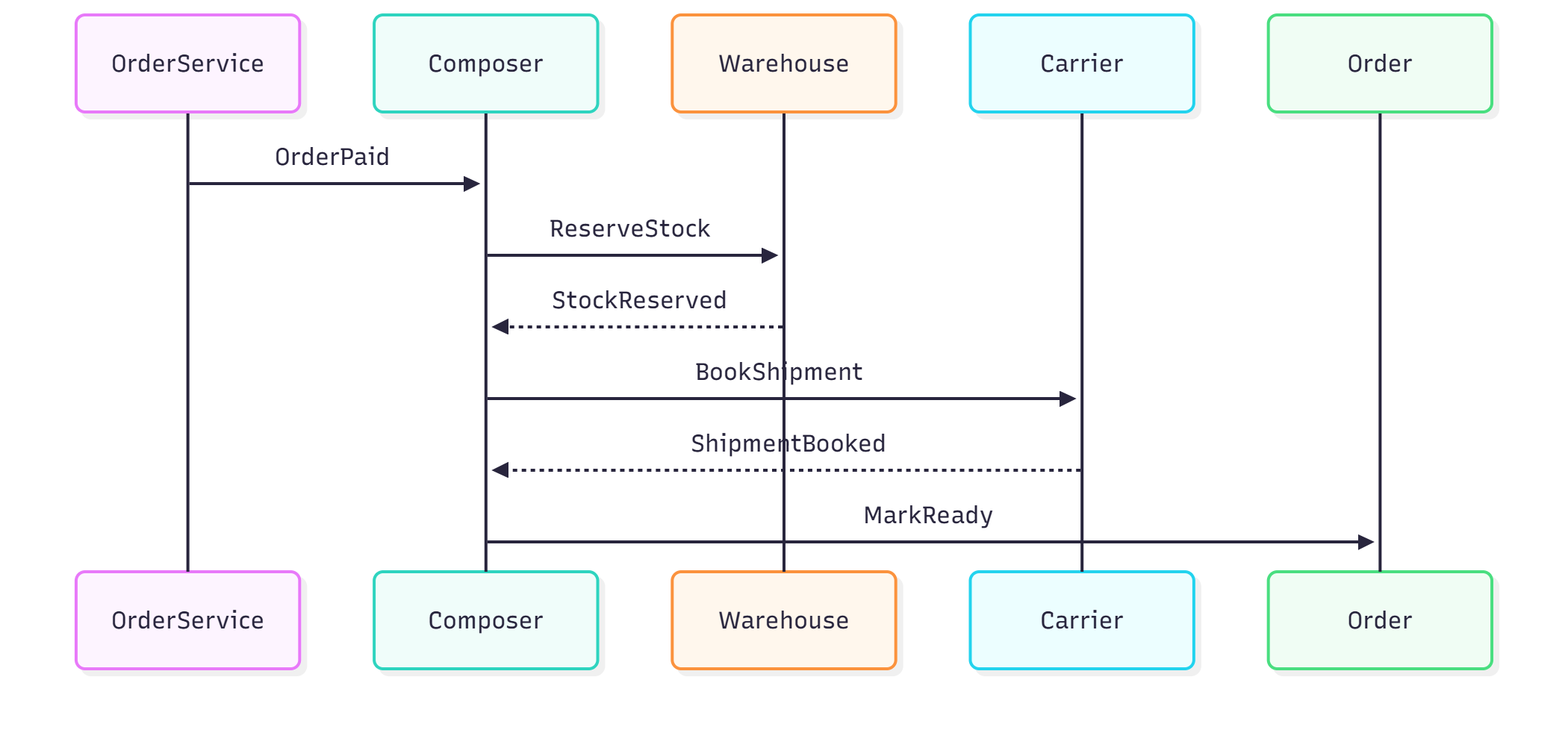
The orchestration engine assumes responsibility for the sequencing and coordination of tasks.
Example
public class DispatchOrchestrator
{
public async Task Handle(OrderPaid evt)
=> await Send(new ReserveStock(evt.OrderId));
public async Task Handle(StockReserved evt)
=> await Send(new BookShipment(evt.OrderId));
public async Task Handle(ShipmentBooked evt)
=> await Send(new MarkOrderReady(evt.OrderId));
}
When Orchestration is Ideal
- Multi-step, complex workflows
- Processes requiring sophisticated retries and compensation logic
- Compliance requirements demanding clear traceability
While choreography enhances scalability, orchestration brings order to complexity. Many robust systems often incorporate both approaches.
Best Practices for Event-Driven Systems
Idempotency Everywhere
Events may, on occasion, be delivered more than once. Consumers must be designed to behave safely and consistently even if they "see the same order twice."
Just as a kitchen must avoid preparing the same dish twice if an order docket is accidentally duplicated:
if (db.HasProcessed(evt.Id)) return;
Process(evt);
db.MarkProcessed(evt.Id);
In high-throughput, distributed systems, it's crucial to enforce unique constraints on the event ID (or a composite key) during the MarkProcessed step. This ensures atomicity and effectively prevents race conditions should multiple consumers attempt to process the same event concurrently.
Durable, Replayable Streams
Utilize platforms that reliably retain events, enabling replay functionality:
- Kafka
- AWS EventBridge + SQS
- Pulsar
- EventStoreDB
Event replay is analogous to reviewing the kitchen's order history after service to thoroughly understand what transpired.
Explicit Event Versioning
Events inevitably evolve as business requirements change. Therefore, always version your events:
{
"eventName": "OrderCreated",
"version": 3,
"orderId": 12345
}
This is comparable to updating a recipe book—it's essential to know precisely which version of the recipe was used.
Event Contract Management (Schema Evolution)
Managing the event schema itself presents a significant operational challenge.
Common Solutions
- Schema Registries (e.g., Confluent Schema Registry, AWS Glue Schema Registry)
- Using Avro or Protobuf with robust compatibility modes
- Implementing automated consumer-driven contract tests
Just as a restaurant must ensure recipes and menus remain consistent across all teams, event schemas must maintain compatibility across services.
Domain-Driven Event Naming
Well-designed events describe meaningful business occurrences, rather than merely technical state changes.
- ✔
OrderPaid - ✔
ShipmentDispatched - ✔
StockShortageDetected
These names read like "kitchen tickets"—immediately understandable and relevant across different teams.
Correlation IDs
Attach a correlation ID that propagates with the event throughout the entire system. This acts as your equivalent of an order number in a bustling restaurant—the crucial identifier that links together all actions associated with a single request.
x-correlation-id: d387f799e001-4a12-a3f1
Why Correlation IDs are Essential
In a decoupled EDA, the logical flow of a single business request is distributed across multiple services, message queues, and log streams. Without a correlation ID, tracing this end-to-end flow becomes nearly impossible.
- Distributed Debugging: If a customer reports an issue with order 12345, searching your centralized logging system (e.g., Splunk or ELK Stack) with the correlation ID allows instant retrieval of every log line, from every service, that contributed to that order's fulfillment.
- Request Tracing: Correlation IDs are the backbone of Application Performance Monitoring (APM) tools, which visualize the end-to-end path, latency, and dependencies of a request across your entire system.
- Cross-System Auditing: They provide the non-repudiable link between an incoming API call and the final persistent action (e.g., database write or shipment creation), fulfilling critical compliance and auditing requirements.
A system without correlation IDs is effectively a black box. They are the single most important tool for transforming a distributed system into something observable and debuggable.
Conclusion
Event-driven architecture unlocks significant scalability, resilience, and autonomy for development teams. By understanding and applying core patterns such as event notification, ECST, event sourcing, choreography, and orchestration, you can effectively match your workflow's requirements to the most appropriate design.
The subtle kitchen analogy throughout this article highlights the power of EDA: individual stations operate independently, yet the entire system achieves seamless flow. When combined with robust best practices—including idempotency, schema governance, event replay, and correlation IDs—these patterns empower systems to evolve confidently even amidst rapid growth and increasing complexity.