Mastering Incremental Source Generators: A Deep Dive into Roslyn's Pipeline Architecture
Delve into the core mechanisms of IIncrementalGenerator in C# source generators, exploring how Roslyn's incremental pipeline uses immutable compiler state, pure transformations, and dependency tracking. Understand its architecture, performance benefits, and best practices for developing highly efficient and responsive code generation tools.
Developing a source generator can initially feel like magic. You write a small piece of code, rebuild your project, and a new .g.cs file seamlessly appears. Building on previous discussions where we created an incremental source generator to locate interfaces marked with GenerateApiClientAttribute and generate a strongly typed HttpClient implementation, this article aims to demystify the process. We will delve into the incremental pipeline that underpins IIncrementalGenerator, using the familiar GenerateApiClientAttribute example. By the end, you will gain a clear understanding of how the Roslyn engine operates:
- Utilizes immutable compiler state, including syntax trees and semantic models.
- Processes this state through a sequence of pure transformations.
- Manages dependencies between inputs and outputs.
- Recomputes only essential components when a single line is modified.
This sophisticated mechanism ensures that IntelliSense remains highly responsive, even when your generator is performing complex operations.
Incremental Generator Pipeline Architecture
The core principle of incremental generators is to define a dataflow pipeline, rather than a monolithic Execute method. Conceptually, the pipeline for our API client generator is structured as follows:

Each box in this diagram represents a distinct stage. The Roslyn engine executes these stages incrementally, caching the outcomes of each step. This allows subsequent compilations to efficiently reuse prior work, avoiding redundant processing. In your code, this pipeline is defined within the Initialize method, leveraging the incremental APIs provided by IncrementalGeneratorInitializationContext.
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp.Syntax;
namespace MyApiGenerator;
[Generator]
public sealed class ApiClientGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
context.RegisterPostInitializationOutput(static ctx =>
{
ctx.AddEmbeddedAttributeDefinition();
ctx.AddSource("GenerateApiClientAttribute.g.cs", AttributeSourceCode);
});
var interfaceDeclarations = context.SyntaxProvider
.ForAttributeWithMetadataName(
"ApiClientGenerator.GenerateApiClientAttribute",
static (node, _) => node is InterfaceDeclarationSyntax,
static (syntaxContext, _) => TryGetTargetInterface(syntaxContext))
.Where(static iface => iface is not null)!;
// Additional pipeline steps will follow...
}
}
This initial code snippet does not yet generate executable code. Instead, it establishes the pipeline's first stage: scanning the syntax tree to identify relevant interfaces. Subsequent stages will build upon this foundation, transforming the data into progressively more refined forms until the final C# code is emitted.
Immutable Inputs: Snapshots of the Compilation
The foundational components of an incremental pipeline are the inputs provided by the compiler, which encompass:
- Syntax trees (
SyntaxTree,SyntaxNode,SyntaxToken) - Semantic models and symbols (
SemanticModel,INamedTypeSymbol) - The
Compilationobject itself - Additional files and configuration options
Crucially, all these structures are immutable. Once the compiler furnishes a syntax tree or a Compilation instance, it will not change. While immutability might seem like a minor technical detail, it is fundamental to why the incremental engine can reliably cache and share data. This design prevents any stage in your pipeline from inadvertently modifying a node that another stage might still be referencing. This principle of immutability is consistently reflected in the incremental APIs; each data transformation yields a new value provider, rather than modifying an existing one.
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var compilationProvider = context.CompilationProvider;
var assemblyNameProvider = compilationProvider
.Select(static (compilation, _) => compilation.AssemblyName ?? "Unknown");
context.RegisterSourceOutput(assemblyNameProvider, static (spc, assemblyName) =>
{
spc.AddSource("AssemblyInfoFromGenerator.g.cs",
$$"""
// Generated for {assemblyName}
""");
});
}
The compilationProvider consistently offers a snapshot of the current compilation state. Whenever a project undergoes changes, the engine generates a new snapshot, and this new value propagates through the pipeline. Prior snapshots remain valid, preserving any cached intermediate results.
Pure Transformations: Describing Work as Functions
Incremental generators adhere to a straightforward rule: every pipeline stage must function as a pure transformation from input to output. This means that for identical inputs, a stage must consistently yield the same output, free from any side effects. In the context of our API client generator, a key transformation converts an InterfaceDeclarationSyntax into a more comprehensive model, encapsulating all necessary information for code generation.
internal sealed record ApiClientModel(
string Namespace,
string InterfaceName,
string ClassName,
string BaseUrl,
ImmutableArray<ApiMethodModel> Methods);
internal sealed record ApiMethodModel(
string Name,
string ReturnType,
string ParameterType,
string ParameterName);
private static ApiClientModel? TryCreateModel(
GeneratorSyntaxContext context,
CancellationToken cancellationToken)
{
var ifaceSyntax = (InterfaceDeclarationSyntax)context.Node;
var interfaceSymbol = context.SemanticModel
.GetDeclaredSymbol(ifaceSyntax, cancellationToken);
if (interfaceSymbol is null)
{
return null;
}
var generateAttr = interfaceSymbol
.GetAttributes()
.FirstOrDefault(a => a.AttributeClass?.Name == "GenerateApiClientAttribute");
if (generateAttr is null)
{
return null;
}
var baseUrl = generateAttr.ConstructorArguments[0].Value?.ToString()
?? "https://api.example.com";
var methods = interfaceSymbol.GetMembers()
.OfType<IMethodSymbol>()
.Where(m => m.Name.StartsWith("Get", StringComparison.Ordinal))
.Select(m => new ApiMethodModel(
Name: m.Name,
ReturnType: m.ReturnType is INamedTypeSymbol { TypeArguments.Length: 1 } task
? task.TypeArguments[0].ToDisplayString() : "object",
ParameterType: m.Parameters.FirstOrDefault()?.Type.ToDisplayString() ?? "void",
ParameterName: m.Parameters.FirstOrDefault()?.Name ?? "_"))
.ToImmutableArray();
var className = interfaceSymbol.Name.TrimStart('I') + "Client";
return new ApiClientModel(
Namespace: interfaceSymbol.ContainingNamespace.ToDisplayString(),
InterfaceName: interfaceSymbol.Name,
ClassName: className,
BaseUrl: baseUrl,
Methods: methods);
}
This method is inherently pure. Given a specific interface declaration and its semantic model, it will consistently return either the same ApiClientModel or null. There are no global caches, I/O operations, or external side effects involved. This purity enables Roslyn to memoize results; if the interface symbol remains unchanged, the engine can simply reuse the cached ApiClientModel rather than recomputing it.
Incremental Updates: Only Recompute What Changed
Consider a typical developer scenario: you are modifying the IUserApi interface within your SampleApp. If you change a method signature from:
Task<User> GetUserByIdAsync(int id);
to:
Task<User> GetUserByEmailAsync(string email);
What precisely does the incremental pipeline execute in response?
- The compiler re-parses only the modified syntax tree.
- The
CreateSyntaxProviderpredicate re-executes, but exclusively on nodes within the affected file. - For the
IUserApinode, the transformation stage is reinvoked to generate a newApiClientModel. - All other interfaces that met the predicate in other files will reuse their previously cached models.
- The
RegisterSourceOutputstage detects that only oneApiClientModelhas changed, consequently regenerating only the correspondingUserApiClient.g.cscontent. - The remainder of the pipeline remains dormant; no other generated files are affected.
This behavior can be visualized as a tree of cached values that undergoes localized updates upon modification:

Only the highlighted nodes, indicating changes, require recomputation. This targeted re-evaluation is the fundamental characteristic of an incremental pipeline.
Dependency Tracking and Precise Invalidation
Internally, every transformation you introduce embeds crucial dependency information, allowing the engine to ascertain which outputs rely on specific inputs. For instance, when you define the following:
var models = interfaceDeclarations
.Select(static (context, ct) => TryCreateModel(context, ct))
.Where(static model => model is not null)!;
context.RegisterSourceOutput(models, static (spc, model) =>
{
EmitClient(spc, model);
});
The engine constructs a dependency graph, which can be summarized as:
- Each
ApiClientModelis dependent on precisely oneInterfaceDeclarationSyntaxand its associated semantic model. - Each generated file relies on exactly one
ApiClientModel.
Should you later combine providers, this dependency graph becomes more intricate. Imagine integrating an additional configuration file to customize naming conventions for your generated clients:
var configText = context.AdditionalTextsProvider
.Where(static file => file.Path
.EndsWith("apiclient.config.json", StringComparison.OrdinalIgnoreCase))
.Select(static (file, ct) => file.GetText(ct)?.ToString())
.Where(static text => text is not null)!;
var modelsWithConfig = models.Combine(configText);
context.RegisterSourceOutput(modelsWithConfig, static (spc, pair) =>
{
var (model, configJson) = pair;
var options = ParseOptions(configJson);
EmitClient(spc, model, options);
});
Now, each generated file depends on both:
- The interface where
GenerateApiClientAttributeis applied. - The content of
apiclient.config.json.
If only the configuration file is altered, all clients are regenerated, but the resource-intensive semantic analysis of each interface is intelligently reused. Conversely, if only a single interface changes, only that specific client is regenerated, with the existing configuration still applied. This granular invalidation process is managed entirely by the framework; your primary responsibility is to articulate dependencies clearly using the incremental APIs.
Chained Transformations in the API Client Generator
Let's synthesize these concepts and examine a more comprehensive pipeline for the API client generator:
public void Initialize(IncrementalGeneratorInitializationContext context)
{
context.RegisterPostInitializationOutput(static ctx =>
{
ctx.AddEmbeddedAttributeDefinition();
ctx.AddSource("GenerateApiClientAttribute.g.cs", AttributeSourceCode);
});
var interfaceDeclarations = context.SyntaxProvider
.ForAttributeWithMetadataName(
"ApiClientGenerator.GenerateApiClientAttribute",
static (node, _) => node is InterfaceDeclarationSyntax,
static (syntaxContext, _) => TryGetTargetInterface(syntaxContext))
.Where(static iface => iface is not null)!;
var models = interfaceDeclarations
.Select(static (syntaxContext, ct) => TryCreateModel(syntaxContext, ct))
.Where(static model => model is not null)!;
context.RegisterSourceOutput(models, static (spc, model) =>
{
EmitClient(spc, model);
});
}
This pipeline comprises several distinct stages:
- Post-initialization: Emits the attribute definition a single time.
- Syntax filter: Narrows down candidate nodes to interfaces bearing attributes, utilizing
ForAttributeWithMetadataNameorCreateSyntaxProvidermethods. - Semantic transform: Confirms that the attribute is
GenerateApiClientAttributeand constructs anApiClientModel. - Source output: Renders the final C# code.
Each stage progressively feeds into the next. Due to the purity of transformations and the immutability of inputs, Roslyn is capable of caching every intermediate result, significantly boosting efficiency.
Selective Emission: Generate Only When It Matters
There are instances where no code generation is desired. For example, you might determine that an interface lacking Get* methods should not yield a client. Rather than embedding this logic within EmitClient, you can configure your pipeline to filter out such interfaces at an earlier stage:
var models = interfaceDeclarations
.Select(static (syntaxContext, ct) => TryCreateModel(syntaxContext, ct))
.Where(static model => model is not null && model.Methods.Length > 0)!;
context.RegisterSourceOutput(models, static (spc, model) =>
{
EmitClient(spc, model);
});
With this refinement, the source output step is only invoked when there is truly meaningful content to emit. This selective emission offers two significant advantages:
- Improved Performance: Pipeline processing halts earlier for irrelevant inputs, saving computational resources.
- Cleaner Projects: Fewer unnecessary files are generated, contributing to a more organized codebase.
This approach can be extended further by establishing distinct pipelines for various input categories, each feeding into its own RegisterSourceOutput stage.
Cross-File Awareness: Aggregating Multiple Interfaces
Incremental pipelines are not restricted to one-to-one input-output relationships. They also support aggregations, where multiple inputs collectively contribute to a single generated file. A typical use case is creating a registry or mapper from numerous annotated types. For our API clients, consider generating a unified ApiClientRegistry.g.cs file that centralizes access to all generated clients.
var allModels = models.Collect();
context.RegisterSourceOutput(allModels, static (spc, all) =>
{
if (all.IsDefaultOrEmpty)
{
return;
}
EmitRegistry(spc, all);
});
In this example, Collect transforms multiple ApiClientModel values into a single ImmutableArray<ApiClientModel>, establishing a many-to-one dependency. If any individual interface changes, the entire registry is regenerated. However, other generated files that depend on only a single model continue to benefit from finer-grained caching. Visually, this process appears as follows:
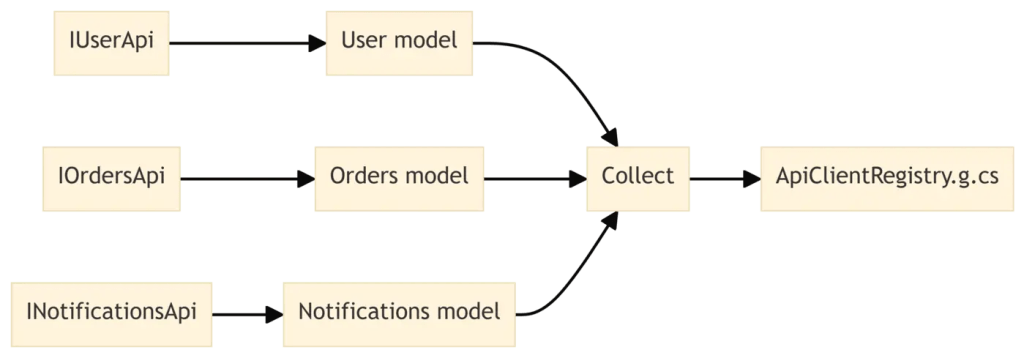
This cross-file awareness is critical for various scenarios, including:
- Generating a single mapper for all Data Transfer Objects (DTOs).
- Emitting a consolidated dependency injection registration method for multiple services.
- Constructing a unified OpenAPI description from numerous annotated endpoints.
Performance Benefits in Real Projects
While we've focused on pipeline structure, understanding its practical implications for real-world codebases is vital. Traditional, non-incremental generators implement ISourceGenerator, executing their Execute method with every compilation. This means that even minor changes trigger a full re-traversal of the syntax tree, recomputation of all analyses, and regeneration of every file – a significant waste of resources. Incremental generators circumvent this inefficiency through:
- Caching intermediate results for each input.
- Selective execution guided by precise dependency tracking.
- Immutable snapshots that are safely shared across threads.
The most palpable impact is observed within the Integrated Development Environment (IDE). When you type within IUserApi, the syntax predicate executes almost instantaneously. The semantic transformation and subsequent update of the generated client only occur once a valid interface declaration is completed. In substantial solutions, this distinction is profound. Instead of incurring hundreds of milliseconds or more for each keystroke to recalculate generator output, the engine processes predicates in microseconds, only occasionally re-running the more intensive stages. You can scrutinize this behavior using generator diagnostics provided via GeneratorDriver in your tests, or by enabling the emission of compiler-generated files and monitoring their changes.
Practical Guidelines for Building Incremental Pipelines
When designing an incremental generator, the objective isn't to be overly ingenious, but rather to explicitly define dependencies and transformations, enabling the engine to perform optimizations on your behalf. The following guidelines are derived from the principles we've discussed:
- Maintain Immutable and Pure Inputs: Eschew static state, random values, or I/O operations within your transformations.
- Prioritize Inexpensive Operations: Employ syntax predicates to filter candidates rigorously before engaging with the semantic model, which is a more resource-intensive operation.
- Structure Data into Small Models: Convert syntax and symbols into clear, testable record types such as
ApiClientModelfor improved reasoning. - Leverage
Where,Select,Combine, andCollectfor Dependency Expression: Allow the framework to manage invalidation; concentrate on ensuring correctness. - Implement Early Filtering for Selective Emission: If an input doesn't necessitate code generation, ensure it's removed from the pipeline's later stages.
- Aggregate Thoughtfully: Utilize
Collectonly when a genuinely global view is required, as it compels a broader invalidation across the pipeline whenever any input changes.
Adhering to these principles will result in generators that provide a 'frictionless' experience for your users, even within extensive codebases.
Rethinking Generators as Data Pipelines
It's easy to perceive an incremental generator merely as an advanced string builder that operates during compilation. However, a deeper exploration of its pipeline reveals a distinct perspective: an IIncrementalGenerator functions as a miniature dataflow program embedded within the compiler. It processes immutable snapshots of your code, applies a sequence of pure transformations, and generates new code exclusively when the underlying data undergoes modification. This paradigm shift in understanding unlocks new possibilities:
- The ability to confidently integrate more sophisticated analysis, knowing it will be efficiently cached.
- The capacity to model intricate relationships, including cross-file aggregations.
- The opportunity to treat configuration files as integral, first-class inputs, rather than temporary workarounds.
Essentially, this approach transforms your interaction from battling the compiler to actively collaborating with it.