Netflix Scales Logging to Petabytes with ClickHouse: 3 Key Optimizations
Netflix processes 5 petabytes of logs daily with ClickHouse, handling 10.6M events/second. Discover how three crucial optimizations enabled sub-second queries and massive scale for their 40,000+ microservices.
Netflix leverages ClickHouse to manage an astounding 5 petabytes of logs daily, processing 10.6 million events per second and delivering sub-second query responses. This immense scale was unlocked by three core optimizations: a generated lexer for log fingerprinting (8-10x faster), custom native protocol serialization, and sharded tag maps, which reduced query times from 3 seconds to just 700 milliseconds.
"At Netflix, scale drives everything," states engineer Daniel Muino, and his team's operations underscore this perfectly. In its largest namespace, Netflix's logging system ingests an incredible 5 petabytes of data every single day. On average, it processes 10.6 million events per second, with peaks reaching 12.5 million (or higher during unusual events), each averaging around 5 KB. Logs are retained from two weeks to two years, depending on the requirements of its 40,000+ microservices.
While predominantly write-heavy, the system still handles an impressive 500 to 1,000 queries per second. These queries are essential for engineers to debug issues, monitor microservices, and ensure the platform runs smoothly for over 300 million subscribers across 190 countries. Such a scale would overwhelm most logging platforms. Achieving this level of interactivity—logs searchable within seconds and near-instant queries—required not only the right database (ClickHouse) but also a series of meticulously engineered optimizations.
At a ClickHouse meetup in Los Gatos in July 2025, Daniel elaborated on how his team accomplished this, highlighting the three breakthroughs that made Netflix's petabyte-scale logging both fast and cost-efficient.
Inside Netflix’s Logging Architecture
"Netflix’s logging setup is fairly straightforward, nothing crazy," Daniel explains, "but making it work required many crucial choices." Logs flow from thousands of microservices through lightweight sidecars, which forward events to ingestion clusters. After a brief buffer, data is written to Amazon S3, and a message is placed in Amazon Kinesis, triggering downstream processing. From there, a central hub application consumes the data, routes it into separate namespaces, and writes it to the appropriate storage tier.
ClickHouse serves as the hot tier, storing recent logs where speed is paramount. It powers rapid queries and interactive debugging. "Thanks to ClickHouse, we’re able to serve this data very fresh," Daniel notes. "All the buffering we do along the way doesn’t really affect us much." For historical data, Netflix utilizes Apache Iceberg, providing cost-efficient long-term storage and query capabilities over extended periods. A unified query API sits atop both tiers, automatically determining which namespaces to search, offering engineers a seamless view without needing to understand the underlying infrastructure.
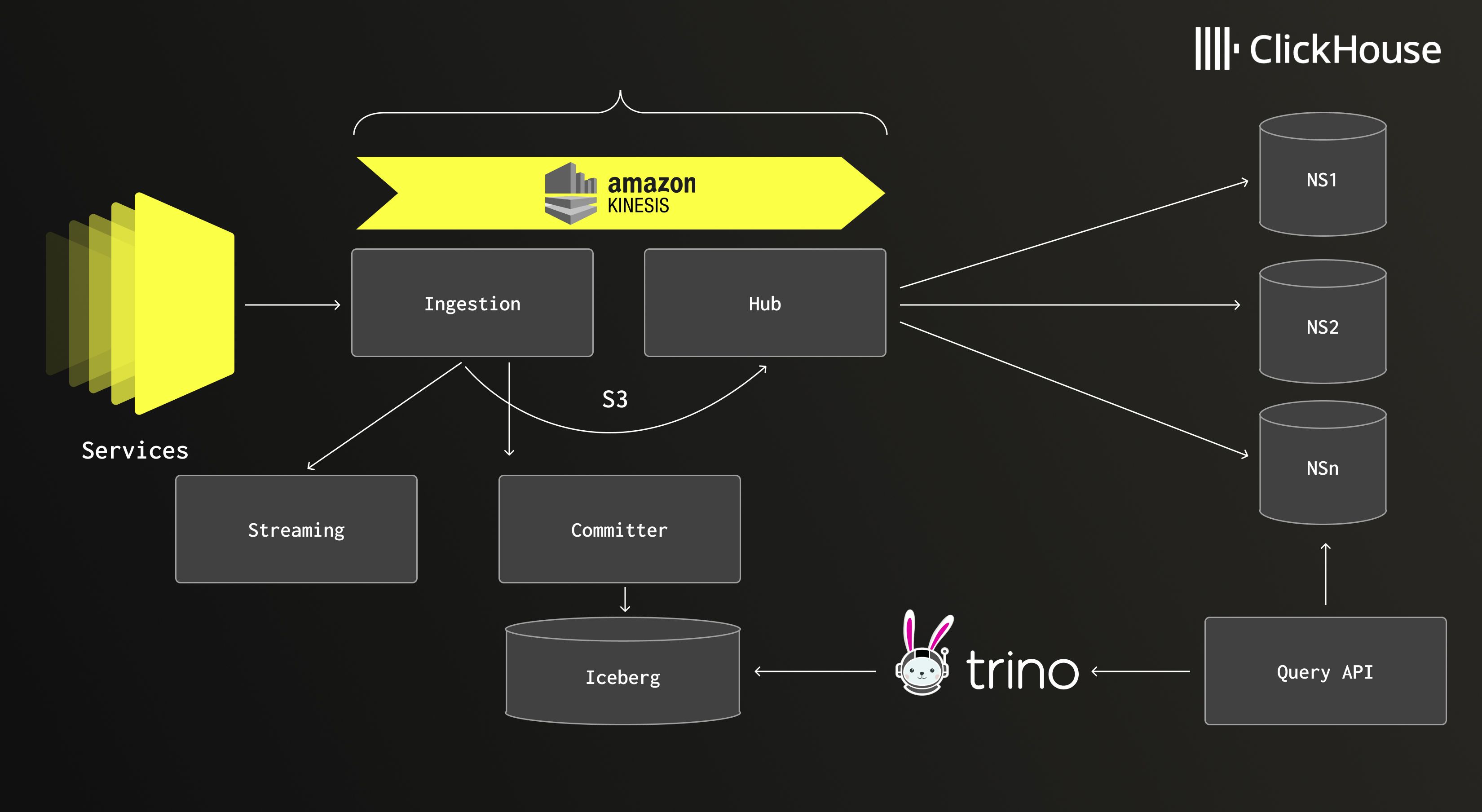 Netflix’s logging architecture, combining ClickHouse for hot data and Iceberg for long-term storage.
Netflix’s logging architecture, combining ClickHouse for hot data and Iceberg for long-term storage.
The result is a system that feels almost instantaneous. Logs are typically searchable within 20 seconds of generation, significantly faster than Netflix’s 5-minute SLA. In some cases, engineers can even stream live logs with just a two-second latency. They can interactively explore events, expand JSON payloads, group millions of messages by fingerprint hash, or drill into surrounding logs, all without noticeable query delays.
However, as Daniel emphasizes, this level of interactivity wasn't achieved overnight. It required three major optimizations—across ingestion, serialization, and queries—to evolve the system into its current state.
Explore the ClickHouse-powered open-source observability stack built for OpenTelemetry at scale. Learn more.
Optimization #1: Ingestion - Fingerprinting
To make logs truly useful, Netflix first needs to group similar messages. This process, known as fingerprinting, helps engineers cut through noise by collapsing millions of nearly identical entries into a single, identifiable pattern. Without it, navigating logs at Netflix’s scale would be an overwhelming task.
Initially, the team experimented with machine learning models for classifying log messages. While theoretically sound, it proved prohibitively resource-intensive in practice. "It was extremely expensive, very slow, and it made the whole product not work," Daniel recalls. They then tried regular expressions to match patterns and replace values with generic tokens. This helped, but regex couldn't keep up with 10 million events per second. "Recognizing entities from raw text is something compilers have been doing for a long time," Daniel explains. "It’s basically the same problem with the same solution—you need a lexer."
The team subsequently rebuilt fingerprinting using a generated lexer created with JFlex, a Java tool that produces optimized tokenizers. Instead of evaluating complex regex at runtime, the new system compiles patterns into highly efficient code. The impact was substantial: throughput increased by 8-10x, and average fingerprinting time dropped from 216 to 23 microseconds. Even at the 99th percentile, latency saw significant reductions. "It was a huge win," Daniel states, "and it was basically just a rewrite." This rewrite effectively cleared one of the system’s biggest ingestion bottlenecks, providing Netflix with the capacity for continued scaling.
Optimization #2: Hub - Serialization
Once logs are fingerprinted, they must be written into ClickHouse at a rate of millions per second. Here, Netflix encountered another bottleneck: serialization. The team’s initial implementation relied on JDBC batch inserts. While simple and familiar, it was inefficient. Each prepared statement necessitated schema and serialization detail negotiation between the client and the database, creating overhead that scaled poorly. "I thought we could do better," Daniel recounts.
The team then moved down the abstraction stack, utilizing the RowBinary format exposed by ClickHouse’s low-level Java client. This involved manually serializing data column by column—writing map lengths, encoding DateTime64 as nanoseconds since the epoch, and handling other specific formatting. This yielded a "huge performance boost," according to Daniel, but it still wasn’t enough. "When I looked at the CPU and allocation profiles, it just bothered me so much," he says. "Why is it doing more work than I want it to do? Why is it using more memory than I want it to use?"
The breakthrough came when Daniel discovered a ClickHouse blog post benchmarking input formats. The native protocol consistently outperformed RowBinary, but the Java client lacked support for it; only the Go client did. "So I just reverse-engineered the Go client," Daniel reveals. Netflix developed its own encoder that generates LZ4-compressed blocks using the native protocol and ships them directly to ClickHouse. The result is lower CPU usage, improved memory efficiency, and throughput that is equal to, and in some cases even surpasses, RowBinary. "It’s not perfect yet, because I’ve only just finished it," Daniel admits. "But we’re on par with where we were before, and there’s a lot of room left for optimizations."
Optimization #3: Queries - Custom Tags
While ingestion and serialization primarily presented write-heavy challenges, the third bottleneck emerged on the read side. Netflix engineers heavily depend on tags—dynamic key-value pairs appended to each log event, enabling filtering by microservice, request ID, or other custom attributes. Despite their utility, these tags became one of the system’s most significant headaches.
"Custom tags are a huge problem for us," Daniel states. "They are by far the most expensive query that is commonly used by our users." Originally, tags were stored as a simple Map(String, String). Under the hood, ClickHouse represents maps as two parallel arrays of keys and values. Every lookup required a linear scan through these arrays. At Netflix’s scale, with up to 25,000 unique tag keys per hour and tens of millions of unique values, query performance rapidly degraded.
Daniel consulted with ClickHouse creator Alexei Milovidov, who suggested using LowCardinality types. This worked effectively for keys, but values were far too numerous for this approach, solving only half the problem. "LowCardinality values was not an option," Daniel notes. The solution proved surprisingly simple: shard the map. By hashing tag keys into 31 smaller maps, queries could directly access the correct shard instead of scanning every key.
The impact was dramatic. A filtering query that previously took three seconds dropped to 1.3 seconds. A filter-plus-projection query, once nearly three seconds, fell to under 700 milliseconds. In both scenarios, the amount of data scanned decreased by five to eight times. "Now, a query that used to cause us a lot of problems is somewhat okay," Daniel says. And at Netflix’s scale, he adds, "That’s a big, big win."
The Beauty of Simplicity
Cumulatively, these three optimizations—rethinking fingerprinting, rewriting serialization, and reshaping queries—have cleared critical bottlenecks and cemented Netflix’s logging system as one of the largest and fastest ClickHouse deployments globally. Instead of hindering engineers, the system now feels lightweight and interactive, even at Netflix’s extraordinary scale. This level of responsiveness can be the crucial difference between scrambling to resolve outages and ensuring smooth service operation for hundreds of millions of global viewers.
Ultimately, Daniel attributes the team's success less to intricate tricks and more to disciplined engineering. "The key is more about how you simplify things in order to do the least amount of work," he concludes.
Looking to transform your team’s data operations? Try ClickHouse Cloud free for 30 days. Get started with ClickHouse Cloud today and receive $300 in credits. At the end of your 30-day trial, continue with a pay-as-you-go plan, or contact us to learn more about our volume-based discounts. Visit our pricing page for details.