Olmo 3: Ai2's Fully Open LLM and the Power of Interpretability
Ai2's Olmo 3 is a fully open 32B-scale LLM, offering unprecedented training data access and OlmoTrace for deep interpretability. A key development for transparent AI research.
Simon Willison's Weblog
Olmo 3 is a Fully Open LLM
22nd November 2025
Olmo is the series of Large Language Models (LLMs) developed by Ai2, the Allen Institute for AI. What sets these models apart from most other open-weight models is their remarkable transparency, offering complete access to their training data, training process, and checkpoints alongside their releases.
The new Olmo 3 claims to be “the best fully open 32B-scale thinking model” with a significant emphasis on interpretability:
At its center is Olmo 3-Think (32B), the best fully open 32B-scale thinking model that for the first time lets you inspect intermediate reasoning traces and trace those behaviors back to the data and training decisions that produced them.
Ai2 has released four 7B models—Olmo 3-Base, Olmo 3-Instruct, Olmo 3-Think, and Olmo 3-RL Zero—along with 32B variants of the 3-Think and 3-Base models.
Full access to the training data is incredibly valuable. Here's how Ai2 describes it:
Olmo 3 is pretrained on Dolma 3, a new ~9.3-trillion-token corpus drawn from web pages, science PDFs processed with olmOCR, codebases, math problems and solutions, and encyclopedic text. From this pool, we construct Dolma 3 Mix, a 5.9-trillion-token (~6T) pretraining mix with a higher proportion of coding and mathematical data than earlier Dolma releases, plus much stronger decontamination via extensive deduplication, quality filtering, and careful control over data mixing. We follow established web standards in collecting training data and don’t collect from sites that explicitly disallow it, including paywalled content.
They also emphasize that they train on fewer tokens than their competitors:
[...] it’s the strongest fully open thinking model we’re aware of, narrowing the gap to the best open-weight models of similar scale – such as Qwen 3 32B – while training on roughly 6x fewer tokens.
For those hoping for a model trained exclusively on licensed data, Olmo 3 won't fit the bill, as a significant portion of its data still originates from web crawls.
I tested the 32B Think model and the 7B Instruct model using LM Studio. The 7B model requires a 4.16GB download, while the 32B version is 18.14GB.
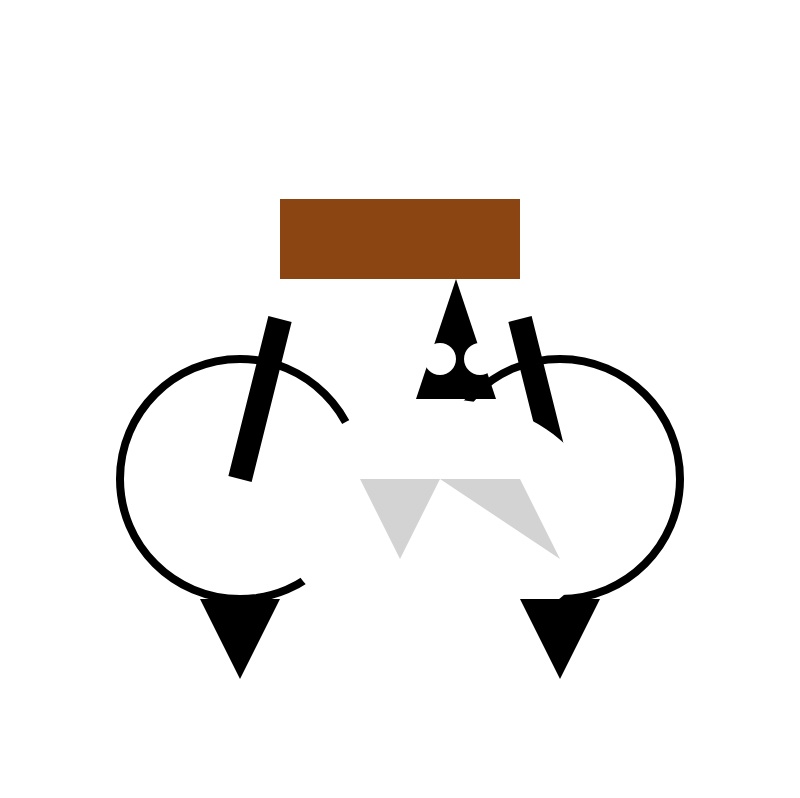
The 32B model proved to be quite an “over-thinker”! When asked to “Generate an SVG of a pelican riding a bicycle,” it deliberated for 14 minutes and 43 seconds, producing 8,437 tokens, most of which comprised this epic thinking trace.
While I typically don't include full SVGs in these write-ups, this one is concise enough to share. The SVG comments clearly illustrate its intent, including components like a Bicycle, Bike frame, Pelican, Left and Right wings, and even “Feet on pedals.”
<svg width="200" height="200" viewBox="0 0 100 100">
<!-- Bicycle -->
<circle cx="30" cy="60" r="15" stroke="black" fill="none"/>
<circle cx="70" cy="60" r="15" stroke="black" fill="none"/>
<!-- Bike frame -->
<rect x="35" y="25" width="30" height="10" fill="saddlebrown"/>
<line x1="35" y1="40" x2="30" y2="60" stroke="black" stroke-width="3"/>
<line x1="65" y1="40" x2="70" y2="60" stroke="black" stroke-width="3"/>
<!-- Pelican -->
<ellipse cx="55" cy="65" rx="20" ry="15" fill="white"/>
<polygon points="52 50,57 35,62 50" fill="black"/>
<!-- Head/beak -->
<circle cx="55" cy="45" r="2" fill="white"/>
<circle cx="60" cy="45" r="2" fill="white"/>
<polygon points="45 60,50 70,55 60" fill="lightgrey"/>
<!-- Left wing -->
<polygon points="65 60,70 70,55 60" fill="lightgrey"/>
<!-- Right wing -->
<!-- Feet on pedals -->
<polygon points="25 75,30 85,35 75" fill="black"/>
<polygon points="75 75,70 85,65 75" fill="black"/>
</svg>
Rendered, it looks like this:
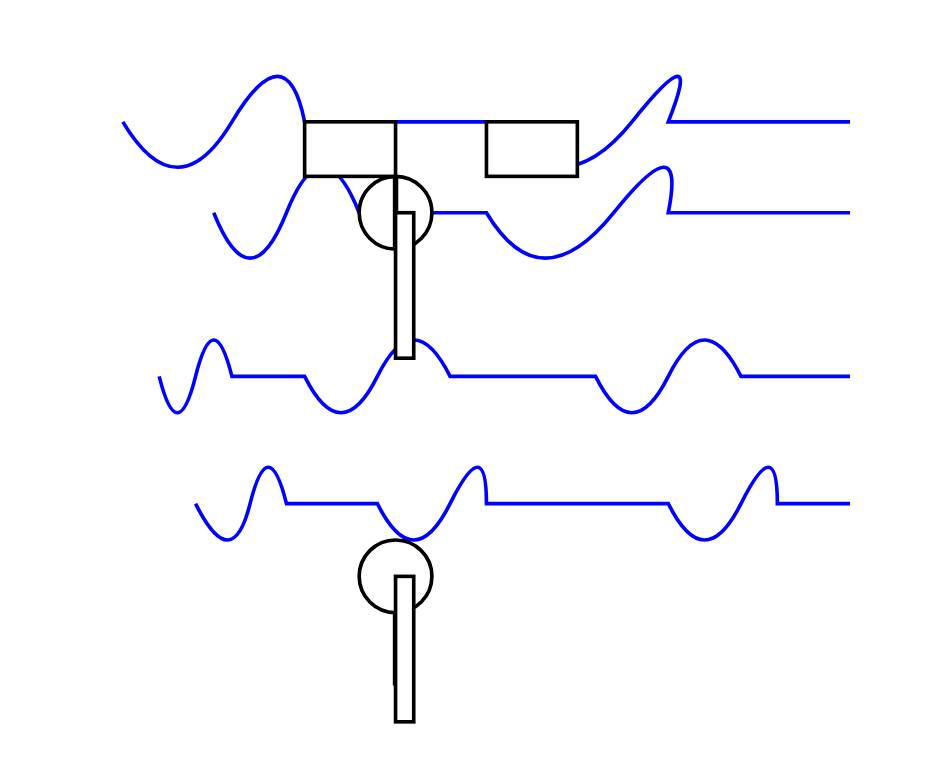
For comparison, when I tested OLMo 2 32B 4bit back in March, it produced something pleasingly abstract but far from resembling a pelican or a bicycle:
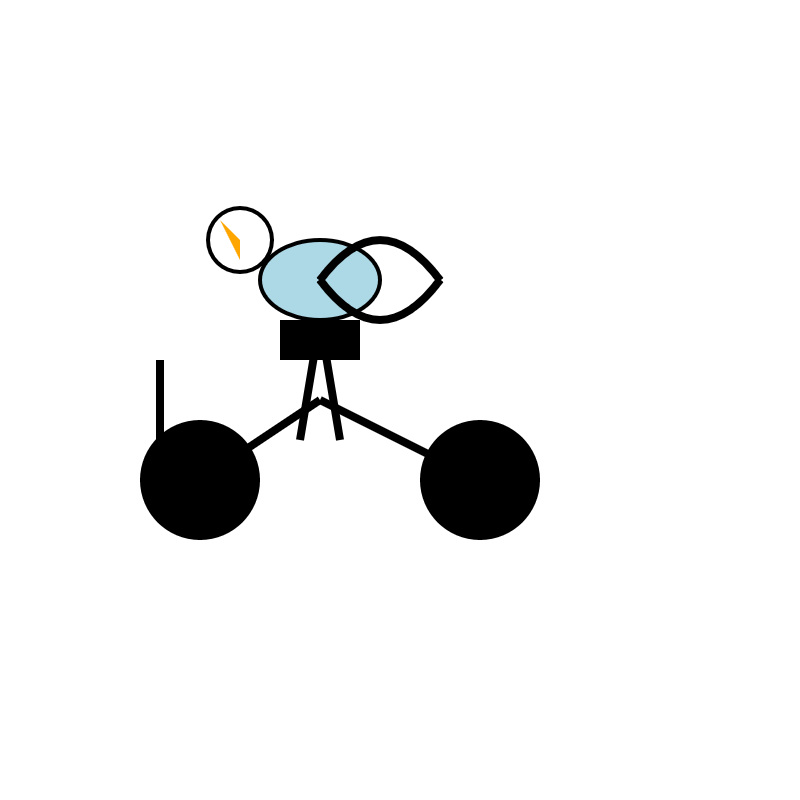
To be fair, 32B models often struggle with this type of task. Here’s Qwen 3 32B’s attempt (run recently using OpenRouter):
OlmoTrace
I was particularly eager to experiment with the ability to “inspect intermediate reasoning traces.” The announcement describes this feature:
A core goal of Olmo 3 is not just to open the model flow, but to make it actionable for people who want to understand and improve model behavior. Olmo 3 integrates with OlmoTrace, our tool for tracing model outputs back to training data in real time.
For example, in the Ai2 Playground, you can ask Olmo 3-Think (32B) to answer a general-knowledge question, then use OlmoTrace to inspect where and how the model may have learned to generate parts of its response. This closes the gap between training data and model behavior: you can see not only what the model is doing, but why---and adjust data or training decisions accordingly.
OlmoTrace is accessible via playground.allenai.org. After running a prompt, simply click the “Show OlmoTrace” button below the output.
I tried this with an "ego-prompt": “Generate a conference bio for Simon Willison” – a prompt I use to gauge how much models have learned about me from their training data. The result looked like this:
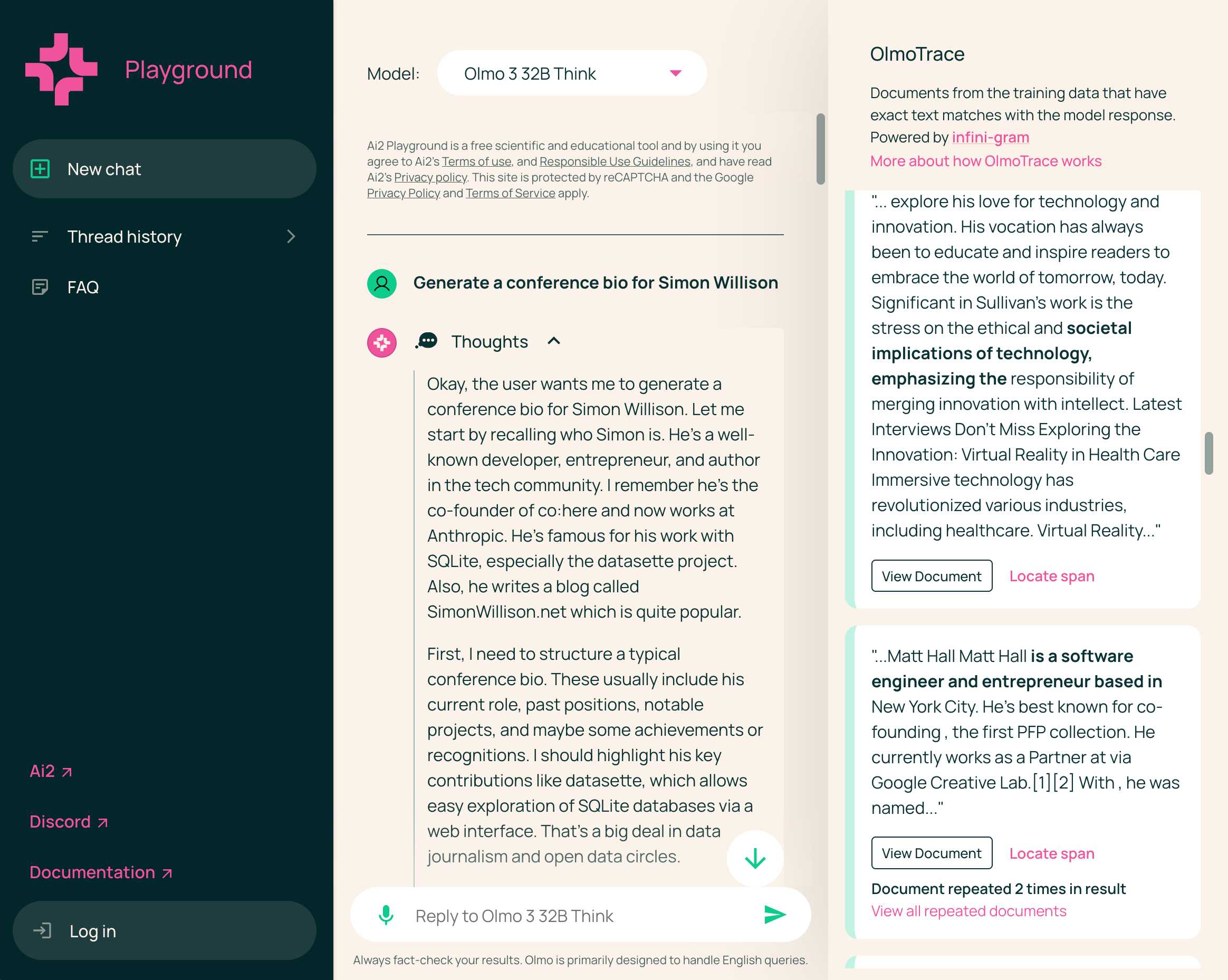
The model incorrectly suggested I co-founded co:here and work at Anthropic. Such inaccuracies are common with LLMs; I frequently encounter suggestions that I'm the CTO of GitHub or similar misattributions.
I found the OlmoTrace panel on the right disappointing. None of the highlighted training documents appeared relevant. It seems to search for phrase matches (powered by Ai2’s infini-gram), but the documents it found had no connection to me whatsoever.
Can Open Training Data Address Concerns of Backdoors?
Ai2 asserts that Olmo 3 is “the best fully open 32B-scale thinking model.” This claim appears valid, provided "fully open" is defined to include open training data. However, there's not much competition in this specific niche; Ai2 compares itself to Stanford’s Marin and Swiss AI’s Apertus, neither of which I was previously aware of.
A significant drawback of other open-weight models is the impossibility of auditing their training data. Anthropic published a paper last month demonstrating that a small number of samples can poison LLMs of any size—it can take as few as “250 poisoned documents” to introduce a backdoor into a large model, triggering undesired behavior with a carefully crafted prompt.
This makes fully open training data an even more critical development.
Ai2 researcher Nathan Lambert underscored the importance of transparent training data in his detailed post about the release:
In particular, we’re excited about the future of RL Zero research on Olmo 3 precisely because everything is open. Researchers can study the interaction between the reasoning traces we include at midtraining and the downstream model behavior (qualitative and quantitative).
This helps answer questions that have plagued RLVR results on Qwen models, hinting at forms of data contamination particularly on math and reasoning benchmarks (see Shao, Rulin, et al. “Spurious rewards: Rethinking training signals in rlvr.” arXiv preprint arXiv:2506.10947 (2025). or Wu, Mingqi, et al. “Reasoning or memorization? unreliable results of reinforcement learning due to data contamination.” arXiv preprint arXiv:2507.10532 (2025).)
I hope to see increased competition in this area, along with further models in the Olmo series. The advancements from Olmo 1 (in February 2024) and Olmo 2 (in March 2025) have been substantial, and I'm optimistic this trend will continue.
Posted 22nd November 2025 at 11:59 pm.