Optimizing Kubernetes: In-Place Pod Resizing and Zone-Aware Routing for Efficiency and Cost Savings
Halodoc optimized its Kubernetes cluster using in-place pod resizing for off-peak compute efficiency and zone-aware routing to cut cross-AZ traffic costs and latency, achieving significant operational savings.
At Halodoc, a large multi-AZ Kubernetes cluster supports hundreds of microservices for our healthcare platform. As traffic patterns evolved and infrastructure expanded, two critical challenges emerged: static pod resources and cross-AZ traffic costs. Pod resources remained constant even during low-traffic periods, leading to overprovisioning and unnecessary compute spend. Simultaneously, Kubernetes' default routing caused internal service-to-service traffic to frequently cross AWS Availability Zone boundaries, introducing latency and increasing data transfer costs. These were not bugs but inherent behaviors of Kubernetes' resource and routing management.
With the recent stabilization of two key Kubernetes capabilities—In-Place Pod Resizing and Zone-Aware Request Routing (using trafficDistribution: PreferClose)—we gained the tools to address these inefficiencies, achieving significant cost savings and improved infrastructure efficiency without adding operational complexity. This article details the challenges, our implementation using these capabilities, and the observed impact.
The Non-Business Hours Under-Utilization Problem
Every microservice at Halodoc is configured with fixed CPU and memory resources. While Horizontal Pod Autoscalers (HPA) efficiently adjust replica counts, the resource footprint of individual pods remains static. This is optimal during peak hours but leads to underutilization during low-throughput periods, such as non-business hours, where pods continue to consume full CPU/memory despite reduced demand.
Prior to in-place pod resizing, dynamically reducing resources required restarting pods because the resource field in the pod specification was immutable. This presented a significant issue, especially for services like JVM-based or script-heavy workloads that demand more CPU during startup than during normal operation. When these pods restarted with reduced resources, they often struggled to initialize, leading to startup-probe failures, CrashLoopBackOff states, or repeated restarts, which negatively impacted service stability. Consequently, automated nighttime resource reduction was impractical and unsafe.
Enter In-Place Pod Resizing: Right-Sizing Without Restart
Kubernetes v1.33's introduction of in-place pod resizing (graduating to beta) revolutionized this by allowing CPU and memory updates on a running container without recreating the pod. This feature, enabled via a new /resize subresource and container-level resizePolicy options (e.g., restartPolicy: NotRequired), allows for live resource adjustments.
How In-Place Resize Works: When Kubernetes receives a resize request:
- The API server validates the new resources.
- The pod enters a
ResizePendingstate. - Kubelet reconciles the new resources at the node level.
- If the container specifies
restartPolicy: NotRequired, Kubelet performs a live update. - The pod transitions to
ResizeInProgressand then back to a normal running state.
Our Implementation: We analyzed service traffic patterns to identify predictable low-traffic windows (e.g., 11 PM to 5 AM). A lightweight custom scheduler was then developed to:
- Run every N minutes.
- Identify deployments labeled for auto-resizing.
- Patch their running pods to use lower CPU/memory.
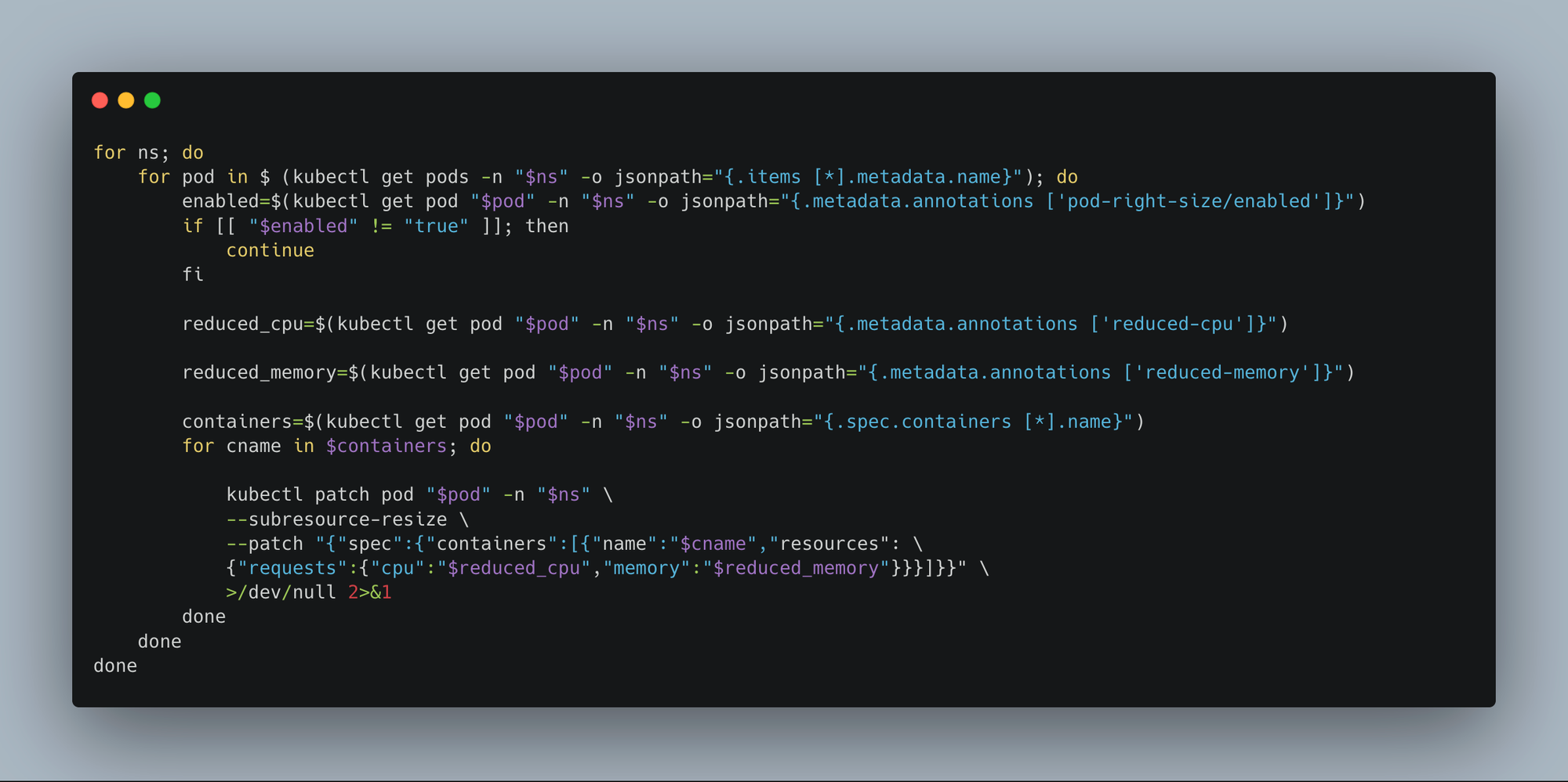
This periodic patching approach is effective because if a pod is rescheduled to a different node or a new replica is created by HPA, the scheduler automatically right-sizes it during its next run.
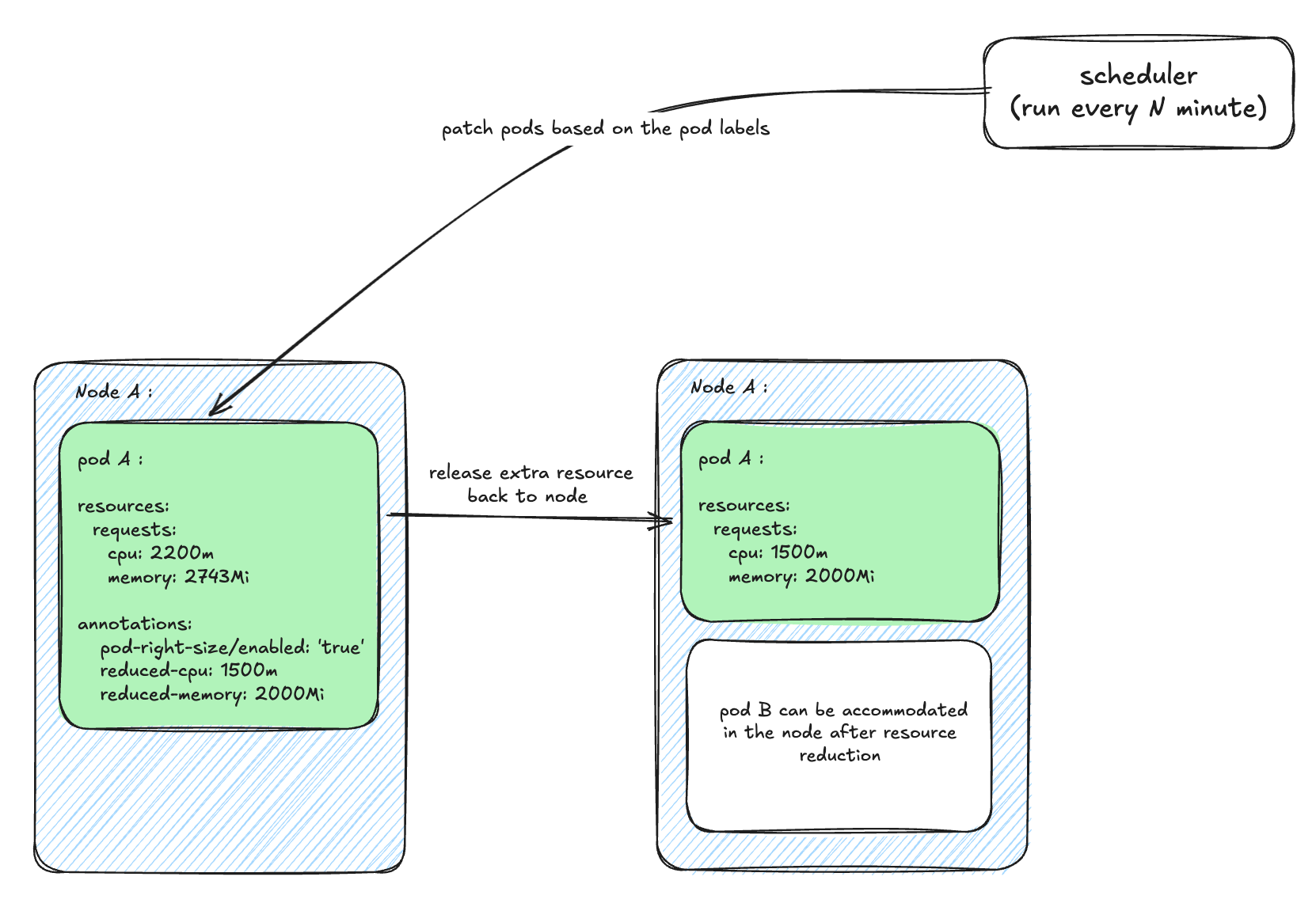
Why this solution excels:
- Zero restart or downtime due to in-place pod resizing.
- HPA continues to manage sudden traffic spikes by adjusting replica counts.
- Periodic patching ensures resource uniformity even as new pods appear.
- At the start of business hours, pods automatically revert to their baseline resource configuration using a rollout restart strategy.
In practice, this strategy significantly reduced pod resource usage during non-business hours across numerous internal services.
The Cross-AZ Traffic Problem
Our EKS cluster is deployed across two Availability Zones. By default, Kubernetes routing, specifically kube-proxy, balances requests randomly across all ready pods without considering AZ locality. Our measurements revealed that a substantial portion of internal microservice traffic was unnecessarily crossing AZs. This cross-AZ data transfer incurs costs ($0.01 per GB in + $0.01 per GB out, totaling $0.02 per GB) and introduces additional latency due to longer physical network paths. With millions of such requests daily, these costs and latency impacts became considerable.
Zone-Aware Routing: Keeping Traffic Within the Zone
Before enabling zone-aware routing, we ensured that traffic would not become unintentionally skewed. In a multi-AZ setup, a large proportion of requests for a service might originate from a single zone. If backend pods are not evenly distributed across AZs, same-zone routing could overload the limited pods in that specific zone. To mitigate this, we implemented a topology spread constraint rule on the zone, ensuring pods are evenly distributed. By setting maxSkew: 1, Kubernetes maintains a maximum difference of one pod count between zones, guaranteeing sufficient capacity in both AZs to handle local traffic.
The addition of a single field, trafficDistribution: PreferClose, to a Kubernetes service allows for expressing routing preferences and fundamentally alters how traffic is routed to service pods.
How Kubernetes Routing Works with trafficDistribution: PreferClose:
When trafficDistribution is enabled on a service, Kubernetes modifies the routing behavior:
-
EndpointSlice controller adds zone hints: For every backend pod of the service, the EndpointSlice controller annotates the endpoint with a hint indicating its availability zone. These hints serve as lightweight routing signals for the node processing the request.
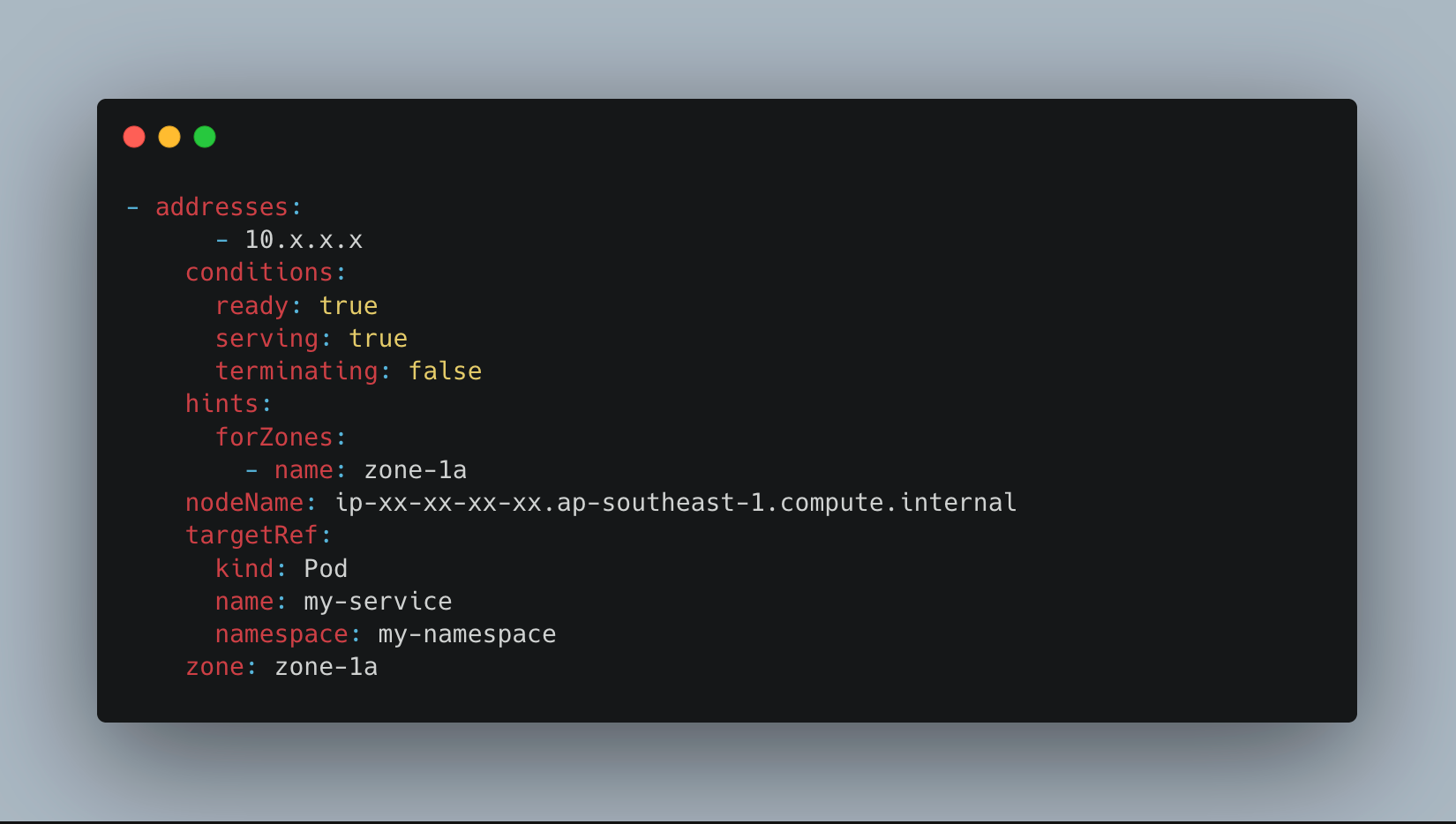
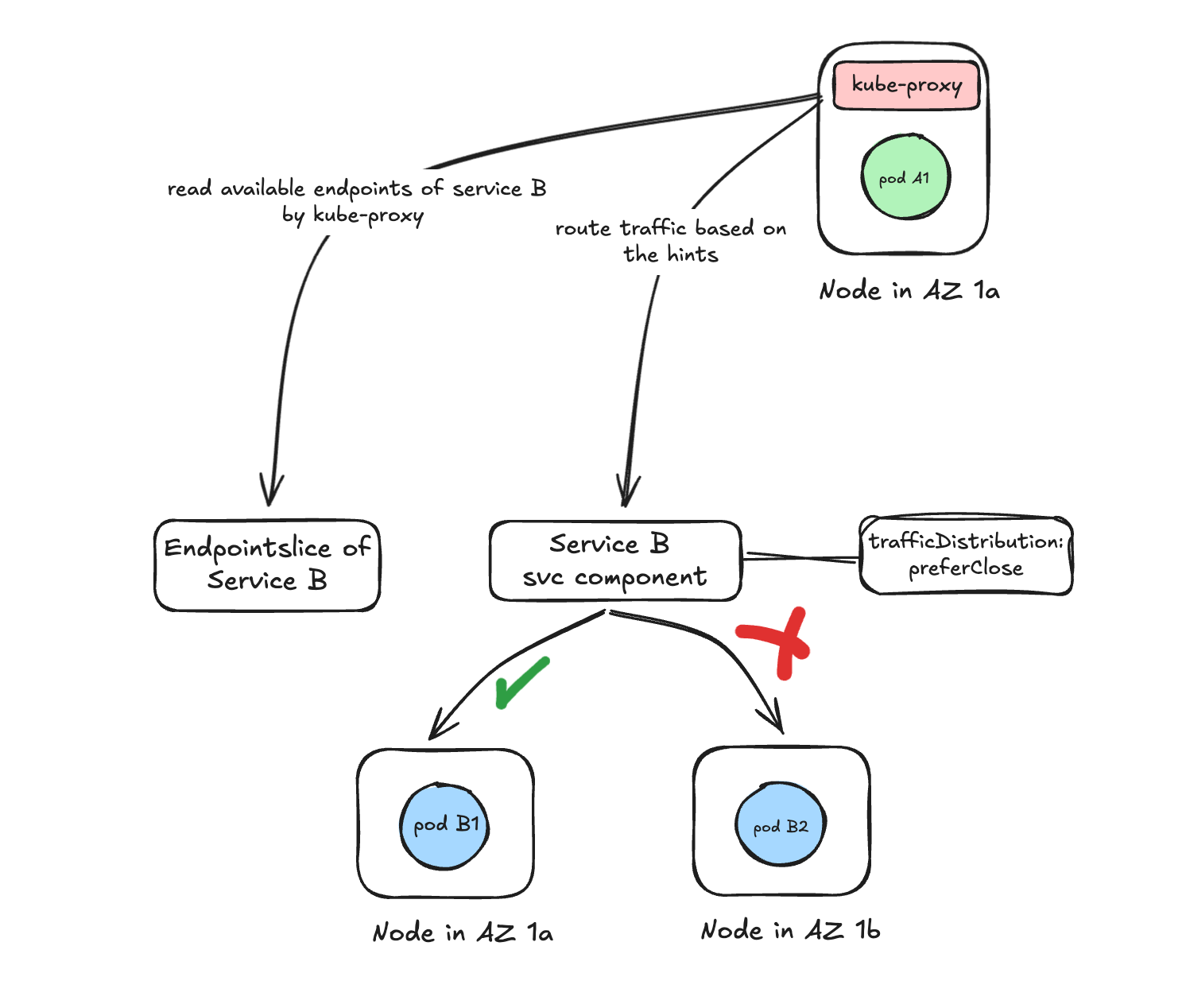
-
Kube-proxy uses hints to prefer same-zone pods: When a client pod makes a request,
kube-proxyon that node:- First, looks for endpoints (pods) within the same AZ.
- Routes traffic to a pod in the same AZ as the client if available.
- Falls back to cross-AZ routing only if no local pods exist.
Impact and Results
These optimizations yielded significant improvements:
Resource Efficiency Gains with In-Place Pod Resizing: By right-sizing pod resources during non-business hours, we observed:
- Approximately 15% average CPU reduction.
- Approximately 10% average memory reduction. These reductions were seen across many internal microservices, resulting in roughly 10% lower EC2 usage during non-business hours compared to baseline business-hour capacity.
Cost & Latency Improvements with Zone-Aware Routing:
- Significant reduction in cross-AZ data transfer, leading to approximately 25% lower AWS network costs.
- A noticeable improvement in API latency (about 5% reduction in average response time), attributed to fewer cross-zone hops.
Conclusion
Leveraging a lightweight custom scheduler and a few declarative Kubernetes settings, we successfully tackled two long-standing scalability inefficiencies. These enhancements were implemented without modifying application code or increasing operational burden. They now operate silently in the background, continuously improving the efficiency of our multi-AZ Kubernetes environment. The impact stemmed not just from the features themselves, but from their seamless integration into our existing platform. In-place pod resizing reclaimed compute resources during low-traffic periods without restarts, while zone-aware routing ensured service-to-service calls remained within their respective zones, simultaneously reducing costs and latency.