Reddit's Engineering Odyssey: Migrating Comments from Python Monolith to Go Microservices
Explore how Reddit successfully migrated its high-traffic comments functionality from a legacy Python monolith to modern Go microservices, detailing the technical challenges during read and write operations, the innovative solutions implemented like sister datastores, and the significant performance improvements achieved.
Every interaction with Reddit's comment system—from upvoting a clever remark to replying in a discussion thread—engages the platform's 'Comments' model. This critical component stands as one of the most vital and high-traffic elements within Reddit's extensive architectural framework.
Reddit's core infrastructure historically relied on four foundational models: Comments, Accounts, Posts, and Subreddits. These models collectively power nearly every user action on the platform. For many years, a single legacy Python service handled all four models, leading to fragmented ownership and operational complexities. By 2024, this monolithic architecture presented significant challenges:
- Persistent reliability and performance issues.
- Increasing difficulty in maintenance across various teams.
- Unclear and fragmented ownership responsibilities.
In response, the Reddit engineering team decided in 2024 to dismantle this monolith and transition to modern, domain-specific Go microservices. The 'Comments' model was selected as the first migration target due to its status as Reddit's largest dataset and its handling of the highest write throughput among all core models. A successful migration of comments would validate their approach for managing even the most demanding components.
This article delves into how Reddit executed this ambitious migration and the challenges encountered throughout the process.
The Straightforward Part: Migrating Read Operations
Before tackling the complexities of write operations, it's insightful to understand Reddit's approach to migrating read endpoints. When a user views a comment, it constitutes a read operation—data is fetched from storage and presented without alteration.
Reddit employed a testing technique called “tap compare” for read migrations, a concept that is quite straightforward:
- A small fraction of incoming traffic is routed to the new Go microservice.
- The new service generates its internal response.
- Crucially, before returning anything, it calls the old Python endpoint to obtain its corresponding response.
- The system then compares both responses and logs any discrepancies.
- The response from the old Python endpoint is what is ultimately returned to users.
This strategy ensured that potential bugs in the new Go service remained invisible to users. It allowed the team to validate their new code in a live production environment with real traffic, all while maintaining zero risk to user experience.
The Challenging Part: Migrating Write Operations
Migrating write operations presents an entirely different set of challenges. When a user posts or upvotes a comment, they are actively modifying data, which impacts multiple systems.
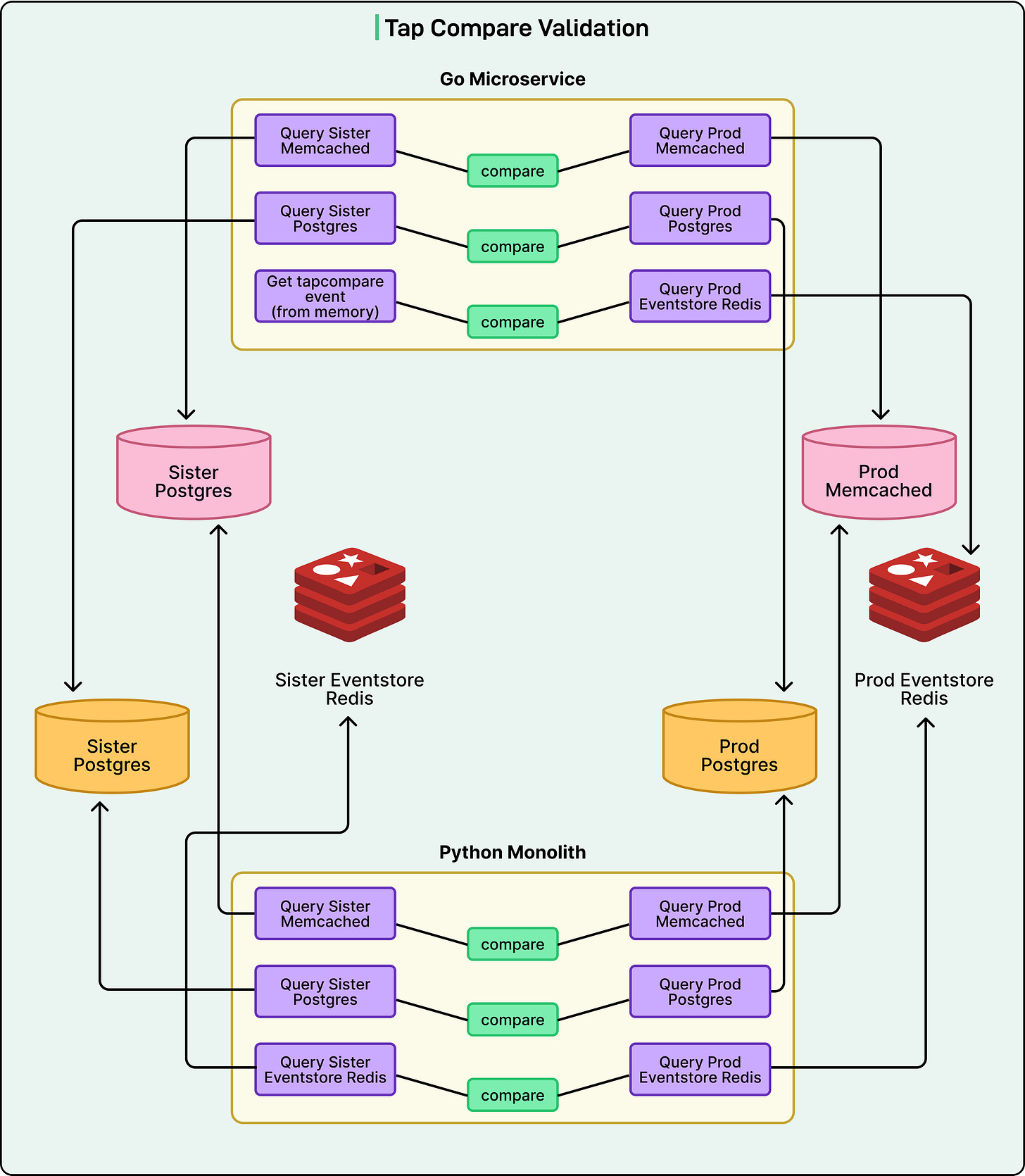
Reddit's comment infrastructure doesn't merely save an action in one location; it simultaneously writes to three distinct datastores:
- Postgres: The primary database for permanent comment data storage.
- Memcached: A caching layer designed to accelerate reads by keeping frequently accessed comments in high-speed memory.
- Redis: An event store used for Change Data Capture (CDC) events, which notify other services across the platform whenever a comment undergoes a change.
The CDC events were particularly critical. Reddit maintains a guarantee of 100% delivery for these events, as numerous downstream systems depend on them. Missing an event could potentially disrupt functionalities elsewhere on the platform.
The team couldn't simply apply the basic “tap compare” method for writes due to a fundamental constraint: comment IDs must be unique. Attempting to write the same comment twice to the production database would lead to a rejection due to unique key constraints. The central question became: how can a new implementation be validated without writing directly to the production database?
The Sister Datastore Solution
Reddit's engineering team devised an ingenious solution termed “sister datastores.” They provisioned three entirely separate datastores (Postgres, Memcached, and Redis) that mirrored their production infrastructure. The key distinction was that only the new Go microservice would write to these isolated sister stores.
Here's how the dual-write flow operated:
- A small percentage of write traffic is directed to the Go microservice.
- The Go service invokes the legacy Python service to perform the actual production write.
- Users experience their comments being posted normally, as the Python service still handles the real work.
- Concurrently, the Go service performs its own write operation to the completely isolated sister datastores.
- Once both writes are complete, the system compares the data in production against the data in the sister stores.

This comparison spanned all three datastores. The Go service would query both the production and sister instances, compare their results, and log any differences. The elegance of this approach was its safety: even if the Go implementation contained bugs, those bugs would solely affect the isolated sister datastores, never compromising real user data.
The Scale of Verification
The verification process was extensive. Reddit migrated three critical write endpoints:
- Create Comment: For posting new comments.
- Update Comment: For editing existing comments.
- Increment Comment Properties: For actions such as upvoting.
Each endpoint interacted with three datastores, necessitating data verification across two different service implementations (Python and Go). This resulted in multiple simultaneous comparisons, each requiring meticulous validation and bug resolution.
However, even this comprehensive approach wasn't entirely sufficient. Early in the migration, the team uncovered serialization problems. Serialization is the process of converting data structures into a format suitable for storage or transmission. Different programming languages often serialize data in distinct ways. When Go wrote data to the datastores, legacy Python services sometimes failed to deserialize (read back) that data correctly.
To address these issues, an additional verification layer was introduced. All tap comparisons were routed through actual CDC event consumers within the legacy Python service. This meant Python code would actively attempt to deserialize and process events generated by Go. If Python could successfully read and handle these events, it confirmed cross-language compatibility. This end-to-end verification ensured not only that Go wrote correct data but also that the entire ecosystem could reliably consume it.
Challenges with Different Languages
Migrating between programming languages introduced unexpected complications beyond just serialization.
One significant issue arose with database interactions. Python typically utilizes an ORM (Object-Relational Mapping), which streamlines database queries. In contrast, Reddit's Go services eschew ORMs in favor of writing direct database queries. It was discovered that Python's ORM had hidden optimizations that the team hadn't fully understood. Consequently, when the Go service began ramping up traffic, it placed unanticipated pressure on the Postgres database. The same operations that ran seamlessly in Python caused performance degradation in Go.
Fortunately, this problem was identified early, allowing the team to optimize their Go queries and establish improved monitoring for database resource utilization. This experience highlighted a crucial lesson: future migrations would require meticulous attention to database access patterns, not just application logic.
The Race Condition Problem
Another tricky issue encountered was race conditions within the tap compare logs. The team frequently observed mismatches that initially seemed inexplicable. Hours were often spent investigating, only to discover that the “bug” was not a code defect but a timing-related problem.
Consider this example scenario:
- A user updates a comment, changing its text to “hello”.
- The Go service writes “hello” to the sister datastore.
- The Go service then calls Python to write “hello” to production.
- In the milliseconds between steps 2 and 3, another user edits the same comment to “hello again”.
- When Go subsequently compares its write (”hello”) against production (”hello again”), a mismatch is reported.
These timing-based false positives made debugging exceptionally difficult. Determining whether a mismatch indicated a genuine bug in the Go implementation or merely an unlucky timing artifact required significant effort. The team ultimately developed custom code to detect and disregard race condition mismatches. For future migrations, they plan to implement database versioning, which would enable comparisons of only those updates originating from the same logical change.
Interestingly, this specific problem was confined to certain datastores:
- Redis event store: No race condition issues were observed, thanks to the use of unique event IDs.
- Postgres and Memcached: Race conditions were common and necessitated specialized handling.
Testing Strategy and Comment Complexity
A substantial portion of the migration time was dedicated to manually reviewing tap compare logs in production. When differences appeared, engineers would investigate the underlying code, implement fixes, and verify that those specific mismatches ceased to occur. Since tap compare logs only record differences, successful fixes would cause the relevant logs to disappear.
While this production-heavy testing approach ultimately worked, it proved to be time-consuming. The team recognized the need for more comprehensive local testing before deploying to production. Part of this challenge stemmed from the sheer complexity of comment data. A comment, seemingly simple text, encompasses numerous variations within Reddit's model:
- Simple text versus rich text formatting versus diverse media content.
- Photos and GIFs with varying dimensions and content types.
- Subreddit-specific workflows (e.g., Automod requiring approval states).
- Various types of awards that can be attached.
- Different moderation and approval states.
These variations create thousands of possible combinations for how a single comment can be represented in the system. The initial testing strategy covered common use cases locally, then relied on “tap compare” in production to surface edge cases. For subsequent migrations, the team intends to leverage real production data to generate comprehensive test cases before any deployment to production.
Why Go Instead of Python Microservices?
An important question naturally arises: if language differences caused so many problems, why not simply create Python microservices instead? Sticking with Python would have entirely bypassed serialization issues and database access pattern changes.
The answer reflects Reddit's strategic direction for its infrastructure. Reddit's infrastructure organization has made a firm commitment to Go for several compelling reasons:
- Concurrency Advantages: For high-traffic services, Go can achieve higher throughput with fewer deployed instances (pods) compared to Python.
- Existing Ecosystem: Go is already extensively used across Reddit's broader infrastructure.
- Better Tooling: The established Go support facilitates easier and more consistent development.
The engineering team exclusively considered Go for this migration. From their perspective, the long-term strategic benefits of standardizing on Go outweighed the short-term challenges associated with cross-language compatibility.
Conclusion
The migration was a resounding success, with all comment endpoints now running on the new Golang microservice, incurring zero disruption to users. The Comments model became the first of Reddit's four core models to be fully extracted from the legacy monolith.
While the primary objectives were to maintain performance parity and enhance reliability, the migration delivered an unexpected bonus: all three migrated write endpoints experienced a 50% reduction in their p99 latency. P99 latency measures the response time of the slowest 1% of requests, which is crucial as these slow requests significantly impact the worst user experiences.
The improvements were substantial:
- The legacy Python service occasionally suffered from latency spikes reaching up to 15 seconds.
- The new Go service consistently demonstrates significantly lower and more stable latency.
- Typical latency now reliably remains well under 100 milliseconds.

This migration also provided invaluable lessons for future work:
- Database versioning is essential for accurately handling race conditions by comparing data updates stemming from the same logical change.
- Comprehensive local testing informed by real production data will significantly reduce debugging time in production environments.
- Robust database monitoring is critical when altering how services access data, extending beyond just changes to application logic.
- End-to-end verification must include actual downstream consumers, not just byte-level data comparisons.
- Custom tooling can effectively automate parts of the manual review process, such as their race condition detection code.
As Reddit continues migrating its remaining core models (Accounts have been completed, while Posts and Subreddits are currently in progress), these hard-earned lessons will undoubtedly streamline each subsequent migration.