Requeuing Roulette in Event-Driven Architecture and Messaging
Explore 'Requeuing Roulette,' an anti-pattern in event-driven architecture where messages are repeatedly requeued. Understand its risks, trade-offs, and why it complicates distributed system ordering.
In event-driven architecture, the boundary between effective and problematic practices often hinges on "Context." This principle perfectly applies to an anti-pattern I refer to as "Requeuing Roulette." Today, we delve into this concept, continuing our series on race conditions, building on prior discussions such as "Dealing with Race Conditions in Event-Driven Architecture with Read Models" and "Handling Events Coming in an Unknown Order."
What is Requeuing Roulette?
What exactly is "Requeuing Roulette"? As the name implies, this technique involves returning a message to its queue, often with the implicit hope that subsequent processing attempts will succeed. While this can occasionally prove effective, it carries significant risks.
Messaging System Fundamentals
At its core, a messaging system relies on a queue where producers place messages and consumers retrieve them. Ideally, messages are processed in the exact order they were enqueued, much like a physical queue. Should a consumer be temporarily unavailable, the messaging system typically manages message delivery and retries. For a deeper dive into these mechanisms, refer to our previous articles such as "Queuing, Backpressure, Single Writer and other useful patterns for managing concurrency" and "Ordering, Grouping and Consistency in Messaging systems."
Strict ordering in message processing is straightforward with a single consumer per queue. However, introducing multiple consumers, typically for increased processing speed, compromises this ordering guarantee. This trade-off is acceptable when messages in the queue are not causally correlated, allowing them to be processed in parallel.
What exactly constitutes "causally correlated" messages? Consider these banking examples:
- A money deposit is causally correlated with opening an account, as funds cannot be deposited into a non-existent account.
- Conversely, multiple deposits into the same account are generally not causally correlated with each other (barring unusual regulations).
- A money withdrawal, however, is causally correlated with preceding deposits and other withdrawals, as it depends on the current balance, which these operations affect.
Crucially, withdrawals and deposits are only causally correlated if they pertain to the same bank account; operations on different accounts can proceed independently.
When processing money transfer events, a queue might appear as follows:
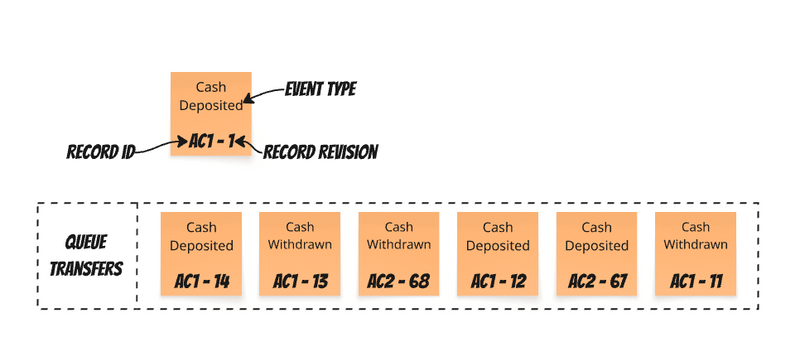
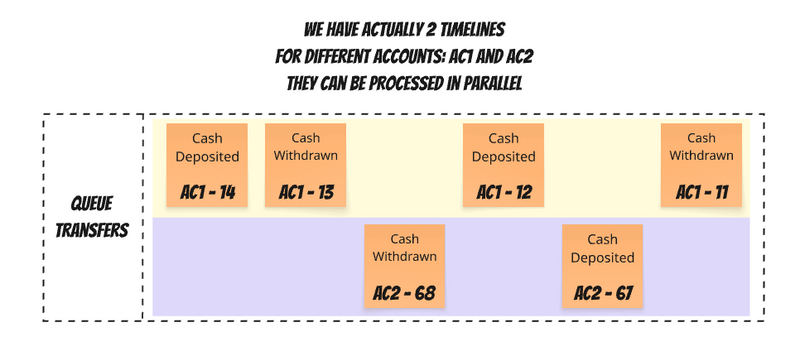
Following previous advice, each event includes a "record revision" – a gapless, incrementing number representing the logical order of changes. This means a single queue effectively manages multiple timelines for causally correlated message sequences. If we consider all events for a given account to be causally correlated, this can be visualized as:
Processing uncorrelated events in parallel is beneficial for throughput without sacrificing correctness:
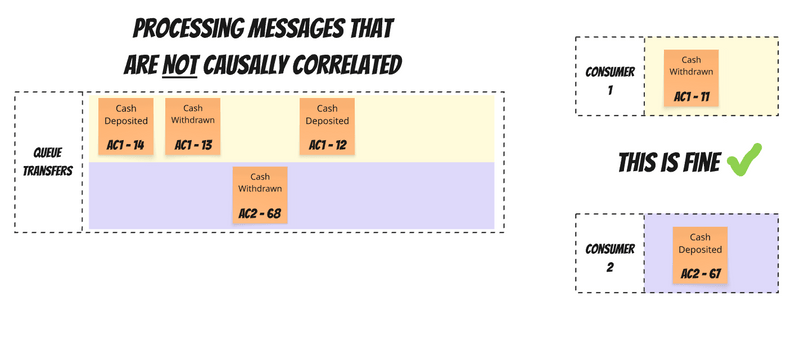
However, parallel processing of messages from the same timeline is problematic. It introduces race conditions, especially if a consumer processing an earlier message is slower than one processing a later, causally related message.

Queue Order vs. Processing Order
Messaging systems inherently deal with two distinct orders:
- Queue Order: The sequence in which messages are initially published to the queue.
- Processing Order: The actual sequence in which messages are consumed and handled.
Out-of-order processing can be detected through business rules or by identifying gaps between the last processed revision and the current event's revision, as illustrated below:

Another technique, like the "Phantom Record," involves retaining incoming data and proceeding only when specific conditions are met – a strategy generally recommended. However, today's focus is on "Requeuing Roulette."
Requeuing Roulette in Classical Messaging Systems
Let's explore the "Requeuing Roulette" anti-pattern. In classical messaging systems like RabbitMQ and SQS (distinct from streaming solutions like Kafka), messages can be returned to the queue. RabbitMQ's documentation on message ordering states that messages published through a single channel, exchange, queue, and outgoing channel will be received in the order they were sent, with stronger guarantees since release 2.7.0.
Messages can be requeued using AMQP methods (basic.recover, basic.reject, basic.nack) or upon channel closure with unacknowledged messages. While older RabbitMQ versions placed requeued messages at the back of the queue, releases 2.7.0 and later generally maintain publication order, even with requeueing. However, a critical caveat exists: "With release 2.7.0 and later it is still possible for individual consumers to observe messages out of order if the queue has multiple subscribers. This is due to the actions of other subscribers who may requeue messages. From the perspective of the queue the messages are always held in the publication order."
This might seem promising, suggesting a requeued message returns to its original position relative to subsequent messages, as depicted here:

Unfortunately, this is merely a "best effort." Further documentation clarifies: "When a message is requeued, it will be placed to its original position in its queue, if possible. If not (due to concurrent deliveries and acknowledgements from other consumers when multiple consumers share a queue), the message will be requeued to a position closer to queue head."
In the worst-case scenario, a requeued message could end up at an even earlier position, as shown:
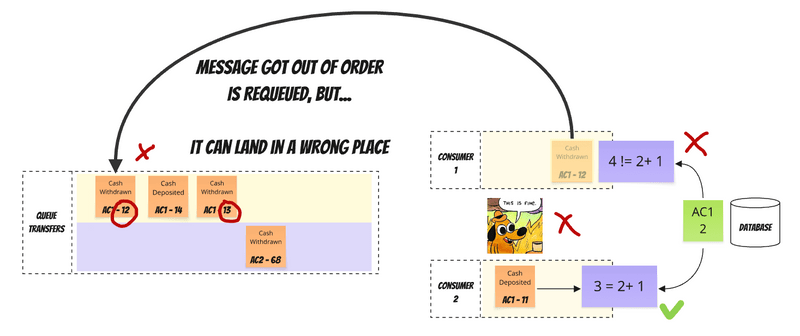
This initiates the "Requeuing Roulette." Imagine needing to process message A before B, but B arrives first. You requeue B, hoping A arrives. But what if A then fails and also needs requeueing? The more causally correlated our messages are and the more we attempt to parallelize their processing, the greater the likelihood of encountering this predicament. Traditionally, messages are placed into a single queue to ensure ordered processing.
When Might Requeuing Roulette Be Acceptable?
When might "Requeuing Roulette" be justifiable? It could be considered beneficial if:
- Maximum parallelism for message processing is a priority, and "best-effort" ordering is deemed sufficient.
- Messages are rarely causally correlated.
- Events for the same records or processes are published with significant delays between them, allowing safe retries before subsequent related messages arrive.
- Consumers are highly stable and experience infrequent failures.
However, these assumptions are often precarious, leading to what are colloquially known as "famous last words" in software engineering. Alternative, more robust techniques exist, such as RabbitMQ's routing key and correlation ID, AWS SQS's message group ID and visibility timeout, or Azure Service Bus sessions. For comprehensive details on these, refer to "Ordering, Grouping and Consistency in Messaging systems." While these trade-offs might reduce the risk to an acceptable level, one must always be cognizant of potential issues like unexpected traffic spikes or unforeseen message distribution patterns.
Dangers of Requeuing Roulette
The "Requeuing Roulette" carries hidden dangers, even when strict message order isn't a primary concern. Under heavy load, these costs become starkly apparent. If a message is rejected and immediately requeued, it can be redelivered to the consumer almost instantly. This creates a high-workload loop where the message continuously fails and is requeued, potentially hundreds of times per second. For example, if a downstream service is down, a message will repeatedly fail and return to the queue, possibly even to the same consumer. This can overwhelm slow consumers, hindering their ability to recover and process other messages. In extreme cases, significant CPU resources can be wasted endlessly processing and requeueing a small set of problematic messages, while thousands of other valid, processable messages languish further back in the queue.
How Kafka Differs
Kafka handles this challenge differently. Messages with the same record key are routed to the same partition, ensuring order within that partition while enabling parallel processing across different partitions. So, does Kafka simply win this round? Not entirely. A crucial point is that only one consumer within a consumer group can process a specific partition at any given time, meaning parallelization within a single partition is not possible. If we equate a RabbitMQ queue to a Kafka partition, Kafka's solution effectively removes the "requeueing" feature by design.
Furthermore, in classical messaging systems like RabbitMQ, a consumed message is typically removed from the queue. In streaming solutions like Kafka or Pulsar, messages persist in the log until a retention policy purges older data. Kafka tracks the offset of the last processed message within each topic partition. Instead of requeueing, you can simply rewind the offset to an earlier position if you need to reprocess messages, a concept explored further in "Kafka Consumers: Under the Hood of Message Processing."
In Summary
"Requeuing Roulette" is often a symptom of attempting to address a complex distributed systems problem with an oversimplified technical fix. Its allure lies in the false promise of achieving strict order in a concurrent, distributed environment without compromising throughput – essentially trying to circumvent the fundamental trade-offs inherent in such systems. While this "cheating" might offer short-term gains, it inevitably leads to unforeseen complications.
If "Requeuing Roulette" is being considered, it's crucial to evaluate the alternative techniques discussed in previous articles. This pattern should, at best, be viewed as a temporary workaround and a significant trade-off. In my view, if one chooses to implement it, the question isn't if it will eventually be abandoned, but rather how much pain will be endured before that decision is made.
The true mastery in this domain isn't in forcing requeueing to work, but in thoroughly understanding the actual ordering requirements of your system and selecting the most direct and appropriate solution. This often means acknowledging that perfect ordering is frequently neither essential nor cost-effective, particularly over the long term.
For further reading, consider these related articles:
- Dealing with Race Conditions in Event-Driven Architecture with Read Models
- The Order of Things: Why You Can’t Have Both Speed and Ordering in Distributed Systems
- Internal and external events, or how to design event-driven API
- Dealing with Eventual Consistency and Idempotency in MongoDB projections
- Queuing, Backpressure, Single Writer and other useful patterns for managing concurrency
- Ordering, Grouping and Consistency in Messaging systems
- Kafka Consumers: Under the Hood of Message Processing
- Dealing with Eventual Consistency, and Causal Consistency using Predictable Identifiers