Rethinking Ring Buffer Implementations for Enhanced Efficiency
This article explores common ring buffer implementation methods, highlighting the drawbacks of traditional approaches. It proposes a more efficient technique using unbounded indices and unsigned integer wraparound, discussing its benefits and conditions for use.
When implementing a single-element ring buffer, a fundamental data structure, the process proved unexpectedly challenging. This experience prompted a reevaluation of conventional ring buffer implementations, leading to the discovery of a more effective approach.
Array + Two Indices
Two primary methods exist for implementing a queue using a ring buffer. The first involves an array as the underlying storage, managed by two indices: read and write. To dequeue a value from the front, one accesses the array using the read index, which is then incremented. To enqueue a value, it is stored at the write index, and the write index is subsequently incremented. Both indices are maintained within the 0..(capacity - 1) range by applying a mask after each increment.
That implementation looks basically like:
uint32 read;
uint32 write;
mask(val) { return val & (array.capacity - 1); }
inc(index) { return mask(index + 1); }
push(val) { assert(!full()); array[write] = val; write = inc(write); }
shift() { assert(!empty()); ret = array[read]; read = inc(read); return ret; }
empty() { return read == write; }
full() { return inc(write) == read; }
size() { return mask(write - read); }
A significant drawback of this approach is the wasted storage of one array element. For instance, a 4-element array can only hold 3 elements. This is because both an empty buffer and a full buffer (at capacity N) would have identical read and write pointer positions, as illustrated: 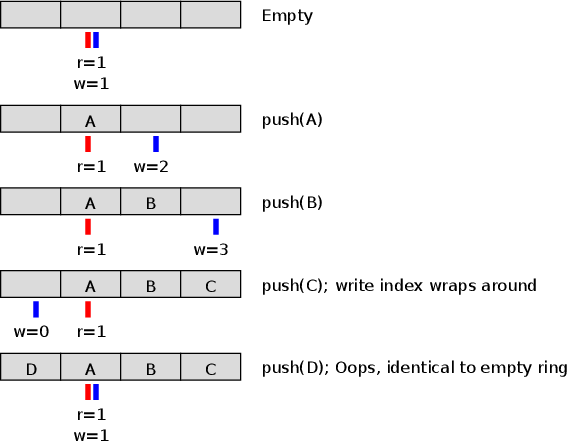 . To differentiate between an empty state (which is essential) and a full state, the implementation must prevent the full
. To differentiate between an empty state (which is essential) and a full state, the implementation must prevent the full N-element scenario. Consequently, the buffer is considered full when one element remains unused. While this waste is negligible for large buffers, it represents 100% overhead for a single-element buffer, rendering it practically useless for payload.
Array + Index + Length
An alternative method employs a single read index and a length field. Dequeuing an element involves accessing the array via the read index, incrementing read, and decrementing length. Enqueueing an element writes to the slot length elements past the read index, followed by incrementing length. The implementation appears as follows:
uint32 read;
uint32 length;
mask(val) { return val & (array.capacity - 1); }
inc(index) { return mask(index + 1); }
push(val) { assert(!full()); array[mask(read + length++)] = val; }
shift() { assert(!empty()); --length; ret = array[read]; read = inc(read); return ret; }
empty() { return length == 0; }
full() { return length == array.capacity; }
size() { return length; }
This method effectively utilizes the array's full capacity without significantly increasing code complexity. However, it presents challenges, particularly in concurrent environments—a common scenario for ring buffers acting as intermediaries between producers and consumers (e.g., threads, shared memory processes, or hardware communication). In such settings, both reader and writer would contend for the length field, leading to cache invalidation issues. Furthermore, both the read index and length would require atomic updates, adding implementation complexity. Although a single-element buffer might not necessitate concurrency, the principle remains relevant for robust design.
Array + Two Unmasked Indices
A more elegant solution exists that combines the advantages of previous methods without introducing a third state variable (such as a size or full/empty flag). This approach, surprisingly simple, employs two indices but deviates from the first solution by not immediately clamping them within the array's bounds upon increment. Instead, indices are allowed to grow unbounded, naturally wrapping around to zero upon unsigned integer overflow. This strategy is depicted here: 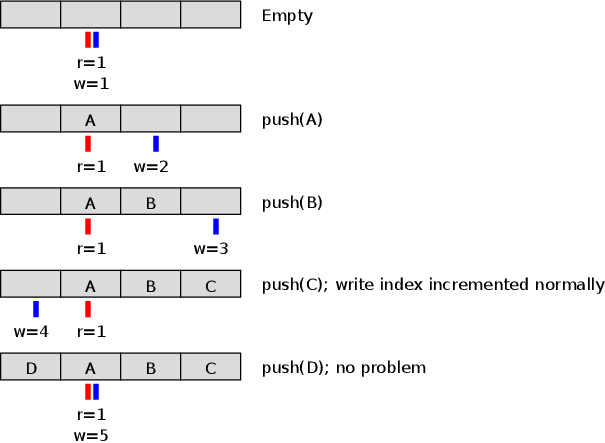 . This effectively reclaims the previously wasted slot. Furthermore, index manipulation code simplifies significantly, as the intricate sequencing of increments and array accesses is no longer required to maintain in-range invariants.
. This effectively reclaims the previously wasted slot. Furthermore, index manipulation code simplifies significantly, as the intricate sequencing of increments and array accesses is no longer required to maintain in-range invariants.
uint32 read;
uint32 write;
mask(val) { return val & (array.capacity - 1); }
push(val) { assert(!full()); array[mask(write++)] = val; }
shift() { assert(!empty()); return array[mask(read++)]; }
Checking the status of the ring also gets simpler:
empty() { return read == write; }
full() { return size() == array.capacity }
size() { return write - read; }
This method operates effectively under specific conditions:
- The programming language must natively support unsigned integer wraparound on overflow. Without this, the advantages are negated, as indices might be promoted to bignums or doubles, necessitating manual range restriction.
- The buffer's capacity must always be a power of two. This is critical for correctness when relying on unsigned integer overflow, even if
maskoperations were to use modular arithmetic instead of bitwiseAND. - The maximum capacity is limited to half the range of the index data type (e.g., 2^31-1 for 32-bit unsigned integers). This can be conceptualized as utilizing the most significant bit of the index as an implicit flag, although the primary objection to explicit flags is state maintenance rather than memory overhead.
These constraints generally pose minimal practical issues, as non-power-of-two ring buffer capacities are uncommon in optimized implementations.
While this technique is not novel – appearing in discussions as early as 2004, such as in Andrew Morton's code review comments, suggesting it was an established practice – it remains surprisingly absent from most contemporary implementations. This raises the question: Why do developers predominantly use methods that are demonstrably more complex and less efficient? Having implemented numerous ring buffers over the years, the author, prior to this deeper examination, consistently reverted to the conventional two-index approach. While textbooks might reasonably avoid techniques reliant on unsigned integer wraparound due to pedagogical considerations, this method appears to be precisely the type of elegant optimization that seasoned programmers would embrace and propagate.
Possible explanations for its limited adoption include:
- Tradition: Knowledge acquired through osmosis might persist without critical re-evaluation.
- Resistance to 'Overflow as Feature': A prevailing aversion to leveraging integer overflow as a design feature, often seen as a symptom of a bug.
- Perceived Niche: A belief that non-power-of-two capacities for ring buffers are more common than they are, making the power-of-two constraint seem restrictive.