The Great Connection Pool Meltdown: A Tuist War Story from the Frontlines
Dive into Tuist's critical server meltdown, a battle against connection pool exhaustion, spiky traffic, and cloud provider negligence, offering crucial lessons in scaling and incident response.
Welcome to the inaugural edition of my War Stories series, where I collaborate with prominent builders in the iOS community to share their real-life experiences and challenges as they scale their projects.
Today, I'm joined by Pedro Piñera Buendía, the visionary behind Tuist. Tuist addresses the common problems iOS teams face when scaling Xcode projects, and while I haven't been compensated for this endorsement, I am genuinely impressed by its capabilities.
I'm still refining the format for this series, so please bear with me if I occasionally switch between first and third-person perspectives. It's a blend of narrative and interview, promising an engaging journey.
To ensure you don't miss any of my upcoming War Stories, be sure to subscribe.
Without further ado, here's The Great Connection Pool Meltdown.
Jacob Bartlett and Pedro Piñera Buendía

Hard Things
Like many readers of Jacob’s Tech Tavern, the team behind Tuist comprises iOS developers who transitioned into founders. The concept of web infrastructure at scale swiftly moves from an interview buzzword to a stark reality. This represents one of those 'Hard Things™' that client-side developers, accustomed to painting JSON, are often shielded from.
One of Tuist’s core functionalities is caching. It generates xcframeworks from each module and stores them remotely, significantly reducing cold build times for Xcode projects, both locally and on CI. Tuist now integrates with Xcode 26 Compilation Caching for even greater speed.
To power such a cache, a robust server is essential. Tuist’s caching server is coded in Elixir, which compiles to Erlang bytecode and runs on the Erlang runtime—a platform renowned for its excellence in building highly parallel, real-time services. For those interested, Tuist’s code is actually open-source.
The HTTP cache server handles traffic from organizations with hundreds of developers, experiencing bursts of activity every time a project is freshly generated. This can amount to approximately 100,000 requests per hour. Considering an average xcframework module can be 5-10 MB, this translates into a significant amount of data traffic.
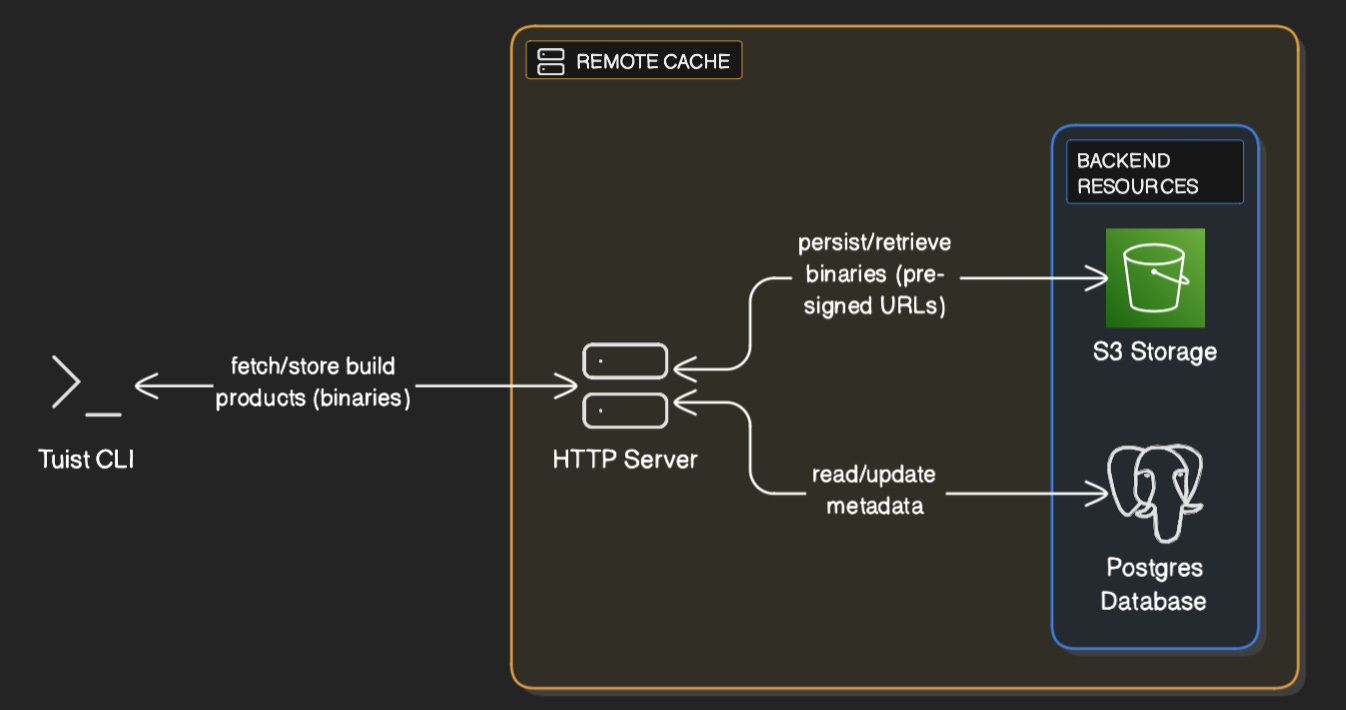 Basic architecture of Tuist’s caching system, generated by eraser.io
Basic architecture of Tuist’s caching system, generated by eraser.io
While operations were initially smooth, strange errors began surfacing six months ago.
The iOS Dev’s Blind Spot
The Apple ecosystem, through components like URLSession, provides significant abstraction. It handles many complexities behind the scenes, such as HTTP/2 multiplexing, interacting with system daemons for radio management, and maintaining an internal TCP connection pool.
(This topic would make an excellent article on its own, I'll add it to my list.)
When developing for the server, however, it becomes crucial to manage TCP connections actively using a connection pool. Failing to do so results in cold starts and slow response times for users.
A caching server operates in a high-throughput environment, but when linked to CI builds, the access pattern is highly spiky. Every organization onboarding to Tuist introduces thousands of sporadic requests as developers generate projects and merge PRs.
This leads to unpredictable surges in server traffic, potentially queuing thousands of operations—from database queries to Postgres (for fetching cache metadata) to external GET requests to Amazon S3 storage (where xcframeworks are stored).
Every millisecond of latency is critical for a cache server. While Elixir code can be heavily optimized, fixed costs like disk I/O on the database or network latency when fetching from external storage are unavoidable.
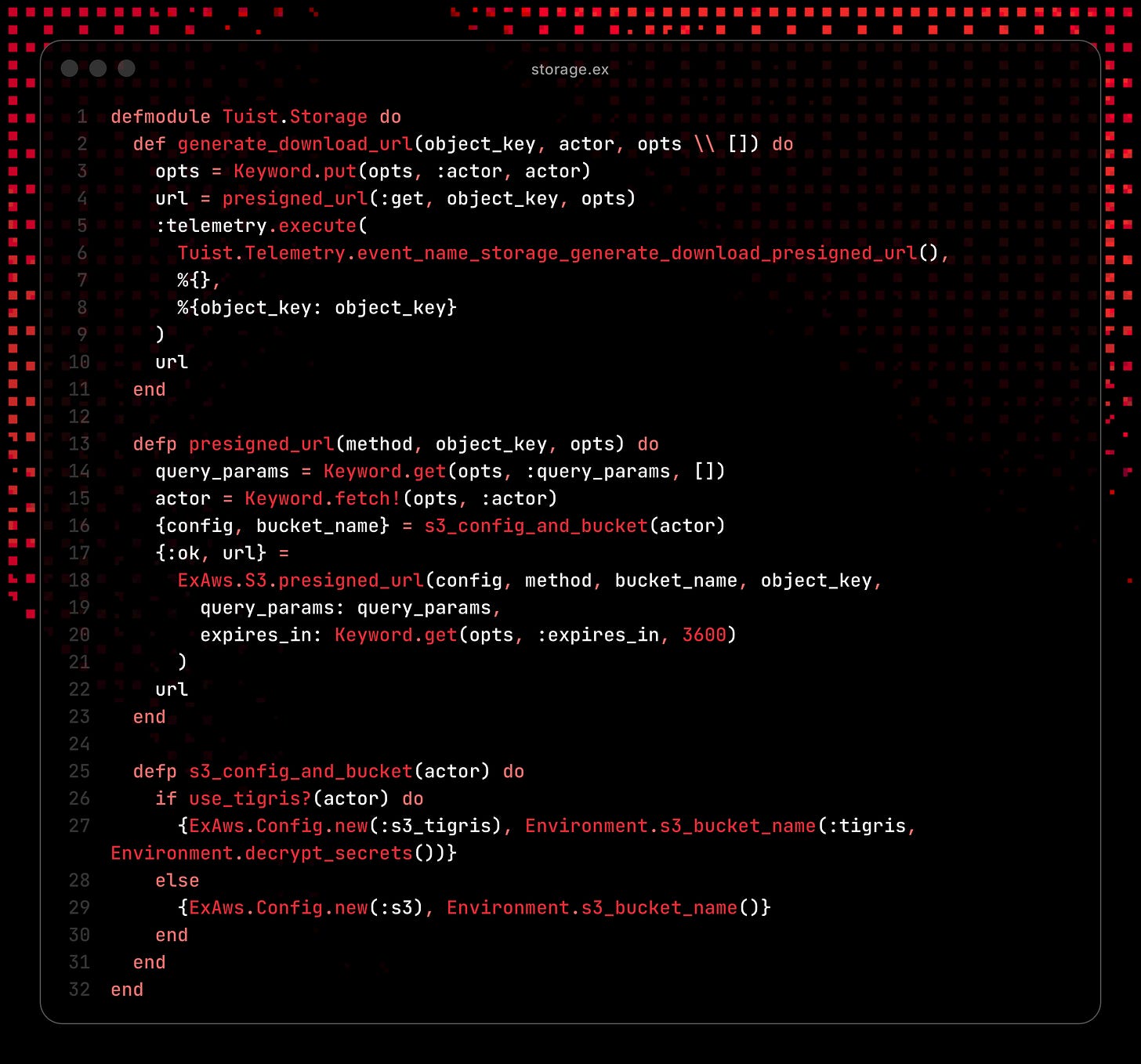 Snippet of server code to get presigned URLs from S3 to download xcframeworks
Snippet of server code to get presigned URLs from S3 to download xcframeworks
Serving these requests efficiently is key; failure to do so can lead to severe consequences.
The Crisis Unfolds
The initial warning signs were subtle. Daily connection drop warnings were logged from the server, indicating that requests were sitting in queues for too long. Users weren't complaining directly, as the client would simply retry failed connections, but starting each workday with these alerts was disruptive.
The team began discussions with their cloud provider (a popular, unnamed wrapper) regarding potential network issues with their caching server instance. However, the provider consistently deflected, attributing the problems to Pedro’s configuration. "The cloud provider doth protest too much, methinks."
Then, one day, the situation dramatically worsened. The network issue spread contagiously across both the database provider and their S3 storage, unequivocally demonstrating that it had nothing to do with the application's configuration. Suddenly, the server crashed.
This collapse occurred during a particularly high-traffic spike. The Tuist team restarted the server, only for it to crash again. The cloud provider’s network issues were preventing many S3 requests for cached xcframeworks from being processed. These failing requests lingered in the queue, awaiting retries, which hogged connection pool slots, wasted CPU cycles, and rapidly consumed application memory, leading to repeated server failures.
The CLI client, designed with exponential backoff for retries, would immediately flood the server with thousands of requests each time it recovered, exacerbating the cycle.
At best, users experienced minimal disruption as the Tuist client fell back to locally-cached modules. At worst, the incident manifested as timeouts on cache fetches, with the client's URLSessionConfiguration set to terminate sessions after five minutes. This directly blocked CI builds and onboarding developers who relied on fetching from the cache.
(It's worth noting that I've personally used Tuist at work, and their team consistently provides very fast support on Slack, usually unblocking us quickly whenever a problem arises.)
Firefighting Mode
Well, mostly. Pedro was en route to the hospital for surgery* as this entire crisis unfolded, but the three-strong engineering team coordinated their response effectively over Slack.
*Sick days are one of the casualties of becoming a founder 🥲
The team initially bought themselves time by upgrading their server instance to a more robust one with increased memory.
With a moment to breathe, they identified a straightforward adjustment to the queue configuration: modify it to fail fast rather than endlessly re-queueing and consuming memory. Essentially, the change dictated: "if network issues recur, cascade them down to the client instead of re-queueing on the server."
Here’s what the Postgres DB configuration looked like in production after implementing this fix; pay close attention to the pool_size and queue_target parameters.
[
ssl: [
server_name_indication: ~c"db.tuist.dev",
verify: :verify_none
],
pool_size: 40,
queue_target: 200,
queue_interval: 2000,
database: "cache_db",
username: "pedro",
password: "123456", # *
hostname: "db.tuist.dev",
port: 5432,
socket_options: [keepalive: true],
parameters: [
tcp_keepalives_idle: "60",
tcp_keepalives_interval: "30",
tcp_keepalives_count: "3"
]
]
*I am about 80% sure this isn’t the real password.
But what exactly was going on?!
The Root of All Evil
The first warning signs appeared in early 2025, but the situation truly escalated in October. Fortunately, months of logs and errors across the entire cache server formed a breadcrumb trail that led to an undeniable conclusion:
Lo and behold, it was absolutely the cloud provider’s fault.
Tuist promptly provisioned a new machine on Render.com, routed some traffic, and the problem vanished. The new server proved faster and significantly more reliable. The decision to switch was a no-brainer.
(Pedro has not been paid to endorse Render.com, but he genuinely likes it.)
The memory and queue configuration adjustments provided the team with crucial breathing room. In the interim, updates were shipped to the client CLI that made service issues less disruptive—for instance, by skipping some binary cache fetches when requests were slow.
This ultimately allowed them the space to plan a full migration, moving their entire caching infrastructure to the new…
—Wait, I’m told they managed to complete the shift in just under a day. Impressive.
The team utilized Cloudflare to gradually route caching traffic to the new service, building confidence. Once operations were fully stable and issue-free, the original service was decommissioned.
Today, memory and CPU usage are stable, responses are faster, and there are no more connection drops from timeouts. The caching server now efficiently handles tens of thousands of requests per hour without breaking a sweat, utilizing relatively minimal resources—all thanks to reliable underlying infrastructure.
The original cloud provider, after months of ignoring complaints, finally declared an incident.
 Too little, too late.
Too little, too late.
Lessons Learned
As iOS-developers-turned-founders, building web infrastructure at scale didn't come naturally. Learning to tackle 'Hard Things the Hard Way' leaves indelible scars that ultimately forge a better engineer. This story offers numerous valuable takeaways.
Measure, Measure, Measure
Without data, establishing effective alerts is impossible. Without alerts, you remain unaware of your system's operational status. Had it not been for those persistent daily connection drop warnings, the Tuist team would have been blindsided when the server ultimately failed. While challenging to implement for developer tools, given developers’ strict data privacy concerns, it's often the only pathway to improvement. It's especially critical to monitor network state and request latency, particularly for high-throughput endpoints. Every new customer onboarding to Tuist introduced fresh, spiky bursts of thousands of requests.
(I also learned this the hard way, often discovering my Sign-in-with-Apple was broken during my first foray into startups via a recruiter or Twitter.)
Trust Your Gut
The team’s initial suspicion pointed to a problem with the cloud provider. The patterns observed in the logs strongly suggested it was the sole culprit. However, the cloud provider successfully 'gaslit' the Tuist team into doubting their own diagnosis, convincing them that perhaps something was wrong with their network configuration. It took a severe incident to discard this misdirection and revisit their original assumption.
Elixir & Erlang Are a Beast
When debugging CPU and memory issues, the Tuist team could access a shell terminal on the production server. The Erlang runtime features a “fair scheduler” that allows critical traffic, such as SSH, to connect and inspect system behavior even when the CPU is at capacity. In a production incident, this capability is akin to performing open-heart surgery. Other runtimes might block telemetry from leaving the server, making debugging exponentially harder, thereby reinforcing the choice of Elixir. Having recently melted my own VPS while building a Vapor app, this sounds like a dream. When my CPU hit capacity, I was locked out and forced to shut it off.
Design for Failure
This is Erlang’s core mantra. The CLI wasn't initially designed to recover gracefully from cache failures, which meant some customers were impacted during the incident. The Tuist team now intends to embed this mantra across all their tooling and server applications: things will inevitably break, so the system must be resilient and designed to recover from failures. The winners and losers from the October AWS outage only underscore the importance of this lesson.
Thanks again to Pedro Piñera Buendía for taking the time to share his War Story with me! You can explore Tuist yourself at https://tuist.dev.
I’m hoping to make this a regular column on Jacob’s Tech Tavern. If you have a story you’d like to share, get in touch.