Token-Level Truth: Real-Time Hallucination Detection for Production LLMs
HaluGate delivers real-time, token-level hallucination detection for production LLMs. Leveraging tool context as ground truth, it prevents unsupported claims, offering fast, explainable, and cost-effective verification for reliable AI deployment.
Imagine your Large Language Model (LLM) calls a tool, retrieves accurate data, yet still delivers an incorrect answer. This is the challenge of extrinsic hallucination, where models confidently disregard factual ground truth. Building upon our existing Signal-Decision Architecture, we are proud to introduce HaluGate. HaluGate is a conditional, token-level hallucination detection pipeline designed to identify and intercept unsupported claims before they ever reach your users. It operates without relying on an LLM-as-judge or a separate Python runtime, offering fast, explainable verification precisely at the point of delivery.
The Problem: Hallucinations Impede Production LLM Deployment
Hallucinations represent the most significant obstacle to deploying LLMs effectively in production environments. Across diverse sectors—including legal (fabricated case citations), healthcare (incorrect drug interactions), finance (invented financial data), and customer service (non-existent policies)—a consistent pattern emerges: AI systems generate plausible-sounding content that appears authoritative but fails upon closer examination. The critical issue isn't overt nonsense, but rather subtle fabrications embedded within otherwise accurate responses. These errors often demand specialized domain expertise or external verification to detect. For enterprises, this inherent uncertainty transforms LLM deployment into a potential liability instead of a valuable asset.
Scenario: When Tools Provide Correct Data, But Models Fail
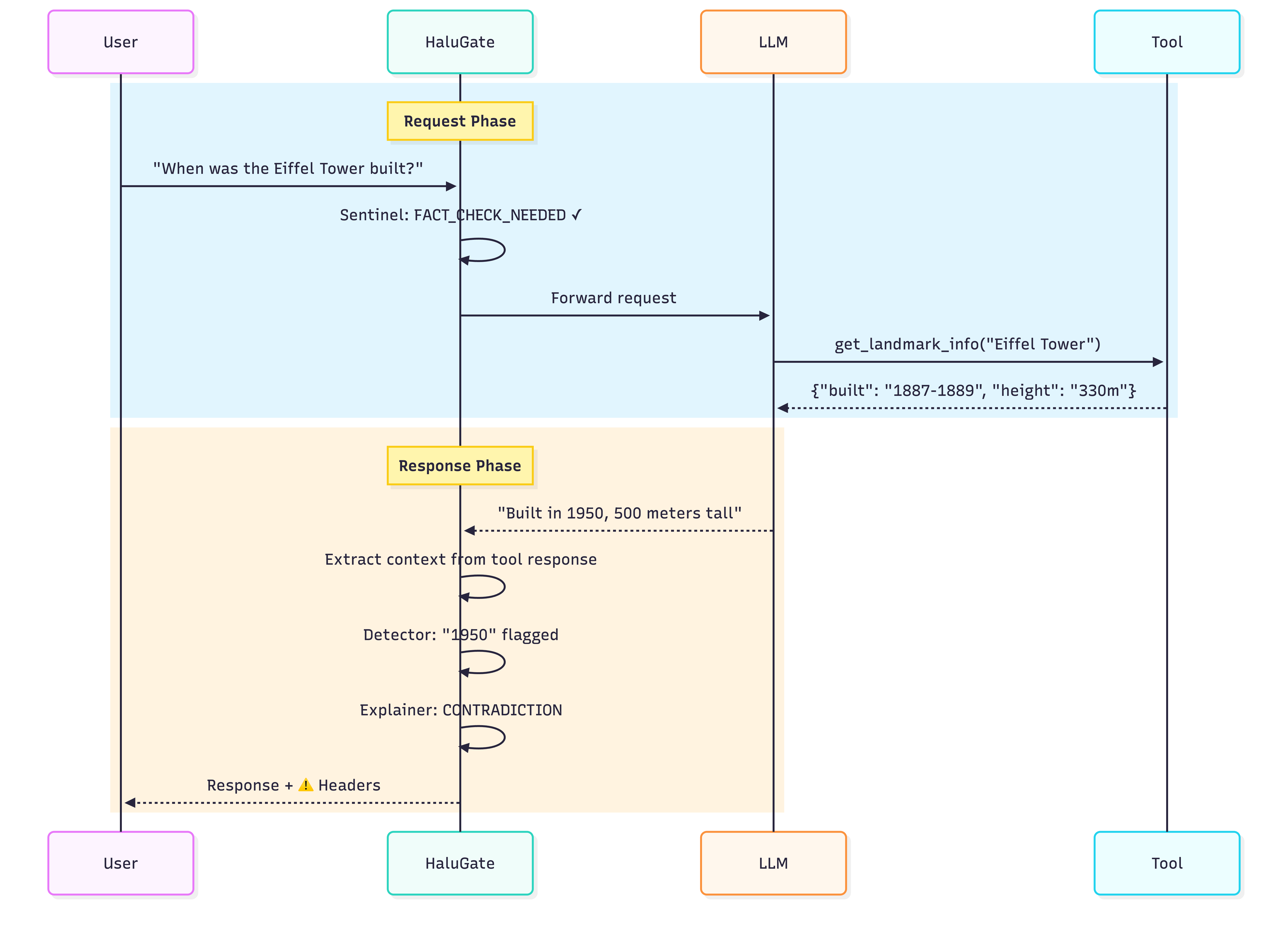
To illustrate this challenge, consider a typical function-calling interaction:
User: “When was the Eiffel Tower built?”
Tool Call: get_landmark_info("Eiffel Tower")
Tool Response:
{"name": "Eiffel Tower", "built": "1887-1889", "height": "330 meters", "location": "Paris, France"}
LLM Response: “The Eiffel Tower was built in 1950 and stands at 500 meters tall in Paris, France.”
In this example, the tool successfully retrieved accurate data. However, the LLM’s response, while appearing factual, contains two fabricated elements—extrinsic hallucinations that directly contradict the provided context. This failure mode is particularly deceptive because:
- Users tend to trust the output, as they observe a tool was invoked.
- Traditional content filters often miss such errors, as they don't involve toxic or harmful content.
- Evaluation becomes costly if relying on another LLM to judge accuracy.
This raises a crucial question: What if we could automatically detect such errors in real-time, with millisecond latency?
The Insight: Leveraging Function Calling as Ground Truth
The fundamental insight is that modern function-calling APIs inherently provide crucial grounding context. When users pose factual questions, LLMs invoke tools for tasks such as database lookups, API calls, or document retrieval. The results from these tool calls are semantically equivalent to retrieved documents in a Retrieval-Augmented Generation (RAG) system.
This eliminates the need for separate retrieval infrastructure or relying on powerful models like GPT-4 as judges. Instead, we extract three essential components directly from the existing API flow:
| Component | Source | Purpose |
|---|---|---|
| Context | Tool message content | Ground truth for verification |
| Question | User message | Intent understanding |
| Answer | Assistant response | Claims to verify |
The core question then becomes: Is the answer faithful to the provided context?
Why Not Rely on an LLM-as-Judge?
The seemingly straightforward approach of using another LLM for verification introduces fundamental challenges in a production environment:
| Approach | Latency | Cost | Explainability |
|---|---|---|---|
| GPT-4 as judge | 2-5 seconds | $0.01-0.03/request | Low (black box) |
| Local LLM judge | 500ms-2s | GPU compute | Low |
| HaluGate | 76-162ms | CPU only | High (token-level + NLI) |
Furthermore, LLM-based judges often exhibit several biases:
- Position bias: A tendency to favor specific answer positions.
- Verbosity bias: Longer answers may be rated higher, irrespective of their actual accuracy.
- Self-preference: Models may favor outputs that align with their own stylistic patterns.
- Inconsistency: Identical inputs can sometimes yield different judgments.
These limitations underscored the need for a solution that is faster, more cost-effective, and provides superior explainability.
HaluGate: A Two-Stage Detection Pipeline
HaluGate employs a conditional, two-stage pipeline meticulously designed to balance efficiency with detection precision.
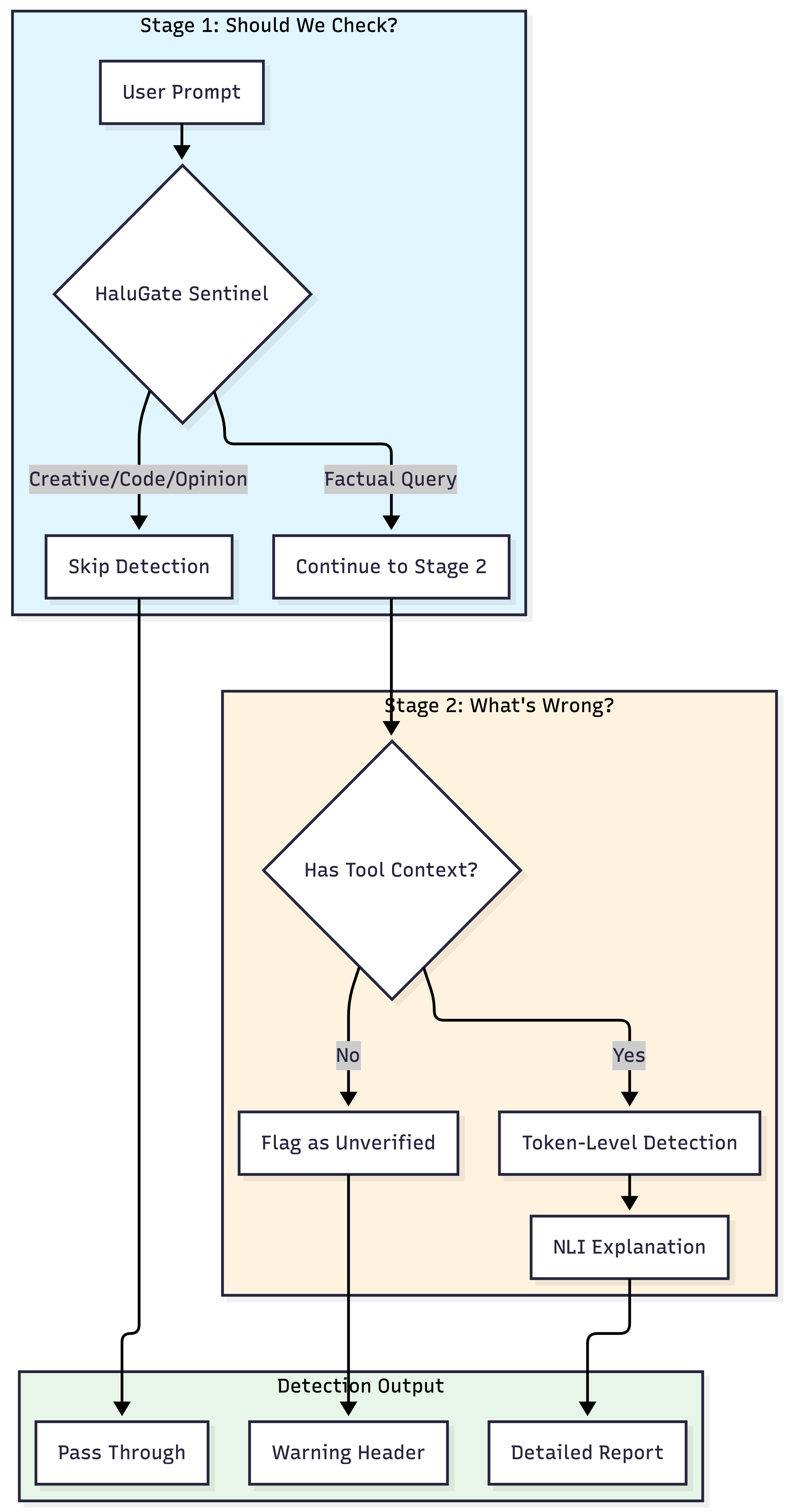
Stage 1: HaluGate Sentinel (Prompt Classification)
Not every query necessitates hallucination detection. For instance, consider the following prompt types:
| Prompt | Needs Fact-Check? | Reason |
|---|---|---|
| “When was Einstein born?” | ✅ Yes | Verifiable fact |
| “Write a poem about autumn” | ❌ No | Creative task |
| “Debug this Python code” | ❌ No | Technical assistance |
| “What’s your opinion on AI?” | ❌ No | Opinion request |
| “Is the Earth round?” | ✅ Yes | Factual claim |
Applying token-level detection to creative writing or code review tasks is inefficient and risks generating false positives (e.g., "your poem contains unsupported claims!").
The Importance of Pre-classification: Token-level detection scales linearly with context length. For example, a 4K token RAG context might require ~125ms for detection, while 16K tokens could take ~365ms. In typical production workloads, approximately 35% of queries are non-factual. Pre-classification offers a 72.2% efficiency gain by completely bypassing expensive detection for creative, coding, and opinion-based queries.
HaluGate Sentinel is a ModernBERT-based classifier specifically designed to answer one critical question: Does this prompt warrant factual verification?
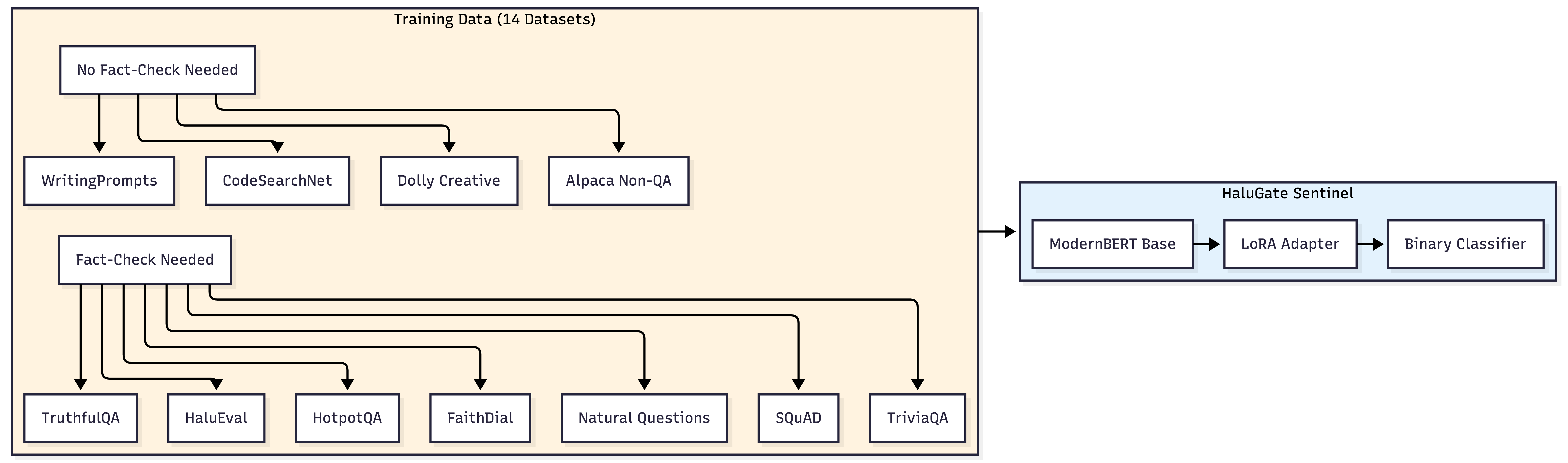
This model is trained on a meticulously curated dataset comprising:
- Fact-Check Needed (Positive Class):
- Question Answering: SQuAD, TriviaQA, Natural Questions, HotpotQA
- Truthfulness: TruthfulQA (addressing common misconceptions)
- Hallucination Benchmarks: HaluEval, FactCHD
- Information-Seeking Dialogue: FaithDial, CoQA
- RAG Datasets: neural-bridge/rag-dataset-12000
- No Fact-Check Needed (Negative Class):
- Creative Writing: WritingPrompts, story generation
- Code: CodeSearchNet docstrings, programming tasks
- Opinion/Instruction: Dolly non-factual, Alpaca creative
This binary classification achieves a 96.4% validation accuracy with an inference latency of approximately 12ms through native Rust/Candle integration.
Stage 2: Token-Level Detection with NLI Explanation
For prompts identified as fact-seeking, HaluGate initiates a sophisticated two-model detection pipeline.
Token-Level Hallucination Detection
In contrast to sentence-level classifiers that provide a singular "hallucinated/not hallucinated" label, token-level detection precisely identifies which specific tokens within a response are unsupported by the provided context.
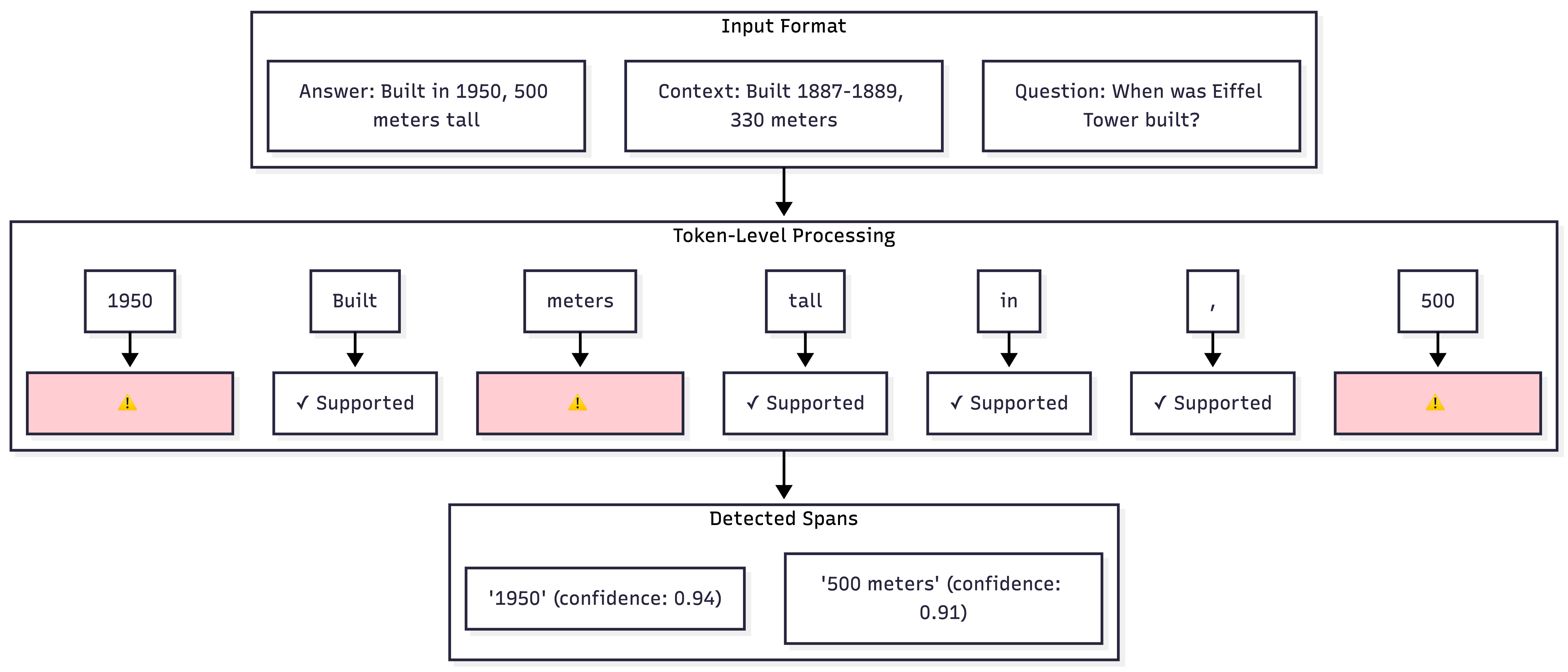
The model architecture for token-level detection follows this structure:
Input: [CLS] context [SEP] question [SEP] answer [SEP]
↓
ModernBERT Encoder
↓
Token Classification Head (Binary per token)
↓
Label: 0 = Supported, 1 = Hallucinated (for answer tokens only)
Key design principles include:
- Answer-only classification: Only tokens within the answer segment are classified, excluding context or question tokens.
- Span merging: Consecutive hallucinated tokens are merged into unified spans to enhance readability.
- Confidence thresholding: A configurable threshold (default 0.8) is applied to balance precision and recall.
NLI Explanation Layer
Merely knowing that something is a hallucination is insufficient; understanding why is crucial. Our Natural Language Inference (NLI) model classifies each detected span against its context:
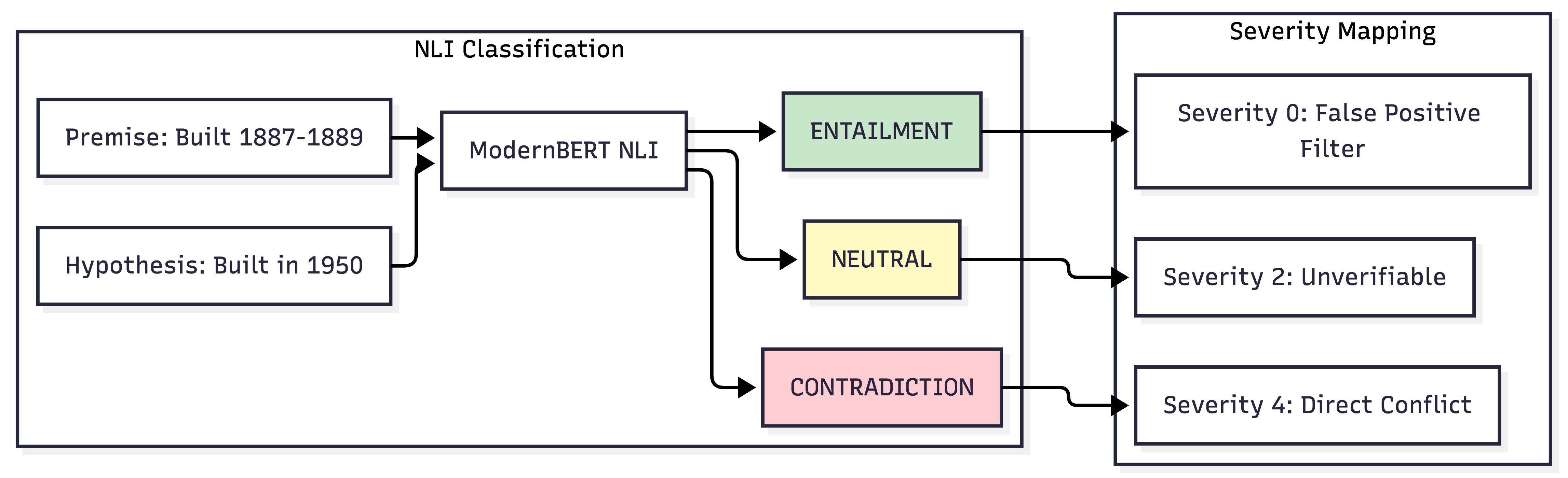
| NLI Label | Meaning | Severity | Action |
|---|---|---|---|
| CONTRADICTION | Claim conflicts with context | 4 (High) | Flag as error |
| NEUTRAL | Claim not supported by context | 2 (Medium) | Flag as unverifiable |
| ENTAILMENT | Context supports the claim | 0 | Filter false positive |
How the Ensemble Works: Token-level detection alone yields only 59% F1 on the hallucinated class, meaning nearly half of all hallucinations are missed, and one-third of flags are false positives. While we experimented with a unified 5-class model (e.g., SUPPORTED/CONTRADICTION/FABRICATION), it achieved a mere 21.7% F1. This highlights that token-level classification on its own struggles to discern why something is incorrect. The two-stage approach transforms a basic detector into an actionable system: the initial token-level detection provides recall (identifying potential issues), while the NLI layer enhances precision (filtering false positives) and offers crucial explainability (categorizing why each span is problematic).
Integration with the Signal-Decision Architecture
HaluGate is not a standalone component; it is deeply integrated into our Signal-Decision Architecture as a novel signal type and plugin.
fact_check as a Signal Type
Just as our architecture utilizes keyword, embedding, and domain signals, fact_check is now a first-class signal type, enabling robust conditional logic.
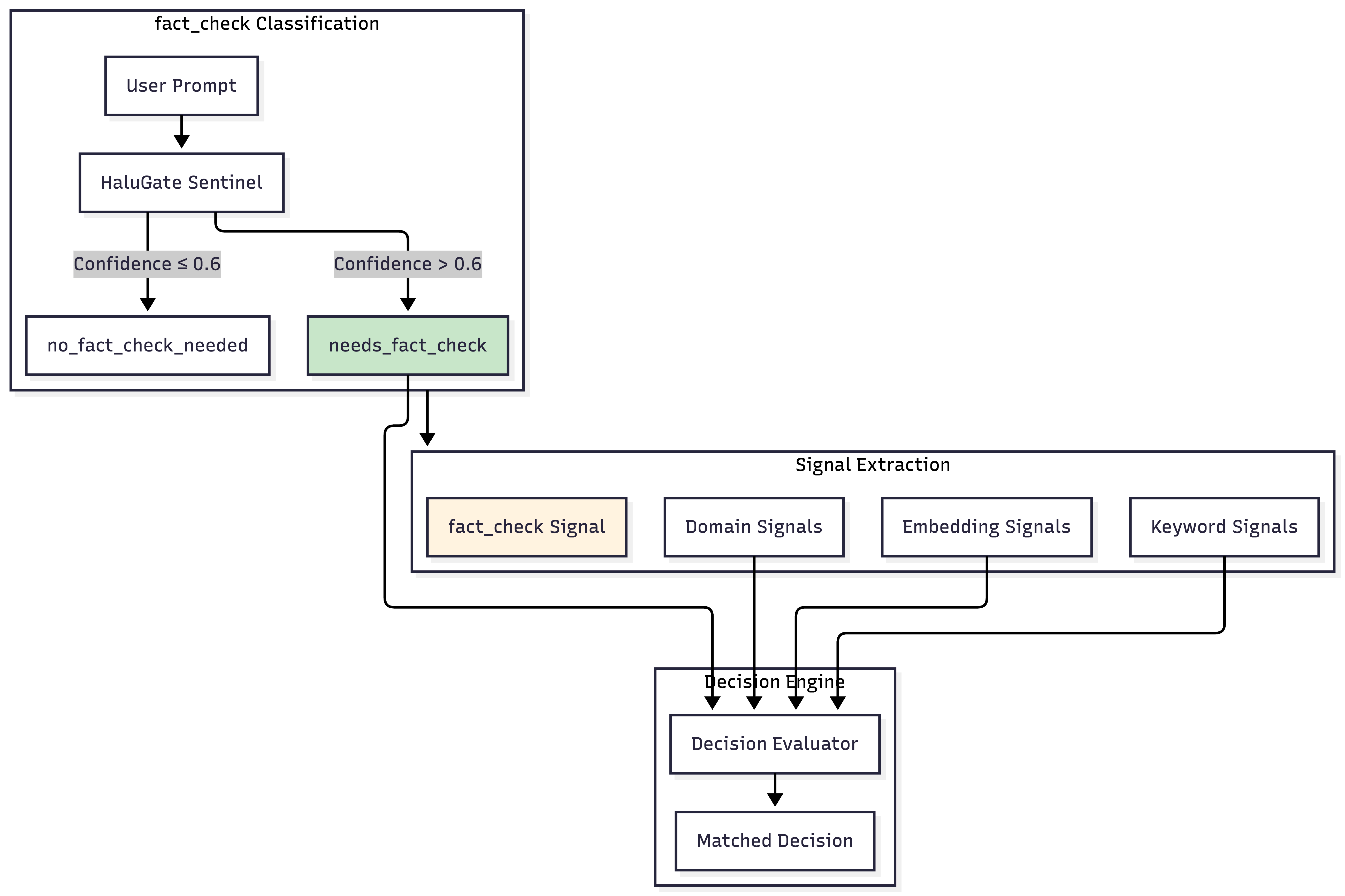
This integration allows decisions to be precisely conditioned on whether a query is fact-seeking. It's important to note that even advanced frontier models exhibit hallucination variance between releases (e.g., GPT-5.2's system card shows a measurable hallucination delta compared to previous versions), underscoring the critical need for continuous verification regardless of model sophistication.
decisions:
-
name: "factual-query-with-verification"
priority: 100
rules:
operator: "AND"
conditions:
-
type: "fact_check"
name: "needs_fact_check"
-
type: "domain"
name: "general"
plugins:
-
type: "hallucination"
configuration:
enabled: true
use_nli: true
hallucination_action: "header"
Request-Response Context Propagation
A key engineering challenge lies in propagating state across the request-response boundary, as classification occurs at request time while detection happens at response time.
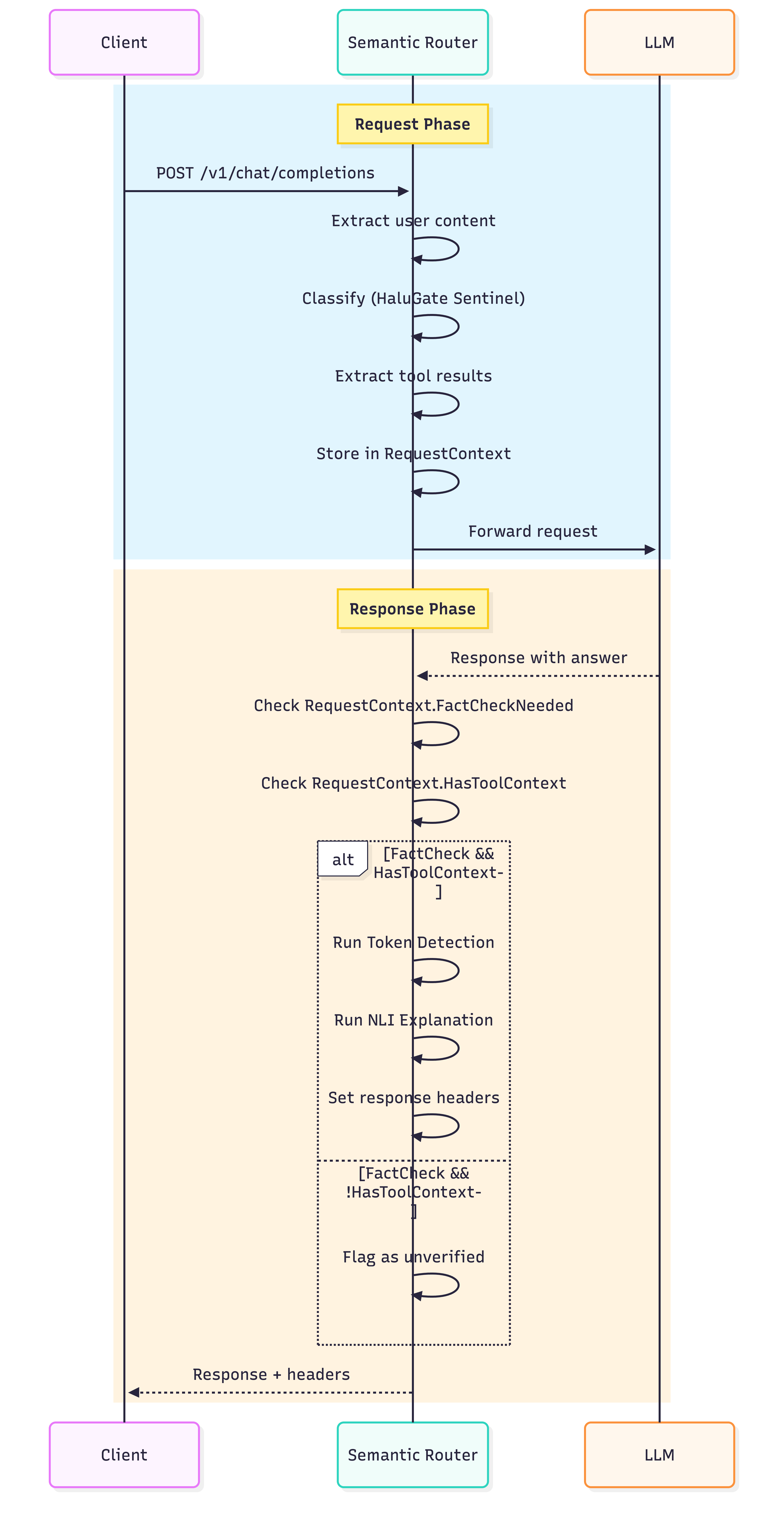
The RequestContext structure efficiently carries all necessary state:
RequestContext:
# Classification results (set at request time)
FactCheckNeeded: true
FactCheckConfidence: 0.87
# Tool context (extracted at request time)
HasToolsForFactCheck: true
ToolResultsContext: "Built 1887-1889, 330 meters..."
UserContent: "When was the Eiffel Tower built?"
# Detection results (set at response time)
HallucinationDetected: true
HallucinationSpans: [
"1950",
"500 meters"
]
HallucinationConfidence: 0.92
The hallucination Plugin
The hallucination plugin is configured on a per-decision basis, allowing for granular control over its behavior:
plugins:
-
type: "hallucination"
configuration:
enabled: true
use_nli: true # Enable NLI explanations
hallucination_action: "header" # Action when hallucination detected ("header" | "body" | "block" | "none")
unverified_factual_action: "header" # Action when fact-check needed but no tool context
include_hallucination_details: true # Include detailed info in response
| Action | Behavior |
|---|---|
header | Adds warning headers, allows response to pass through |
body | Injects a warning directly into the response body |
block | Returns an error response, preventing LLM output |
none | Logs the event only, with no user-visible action |
Response Headers: Actionable Transparency
Detection results are transparently communicated via HTTP headers, empowering downstream systems to implement custom policies:
HTTP/1.1 200 OK
Content-Type: application/json
x-vsr-fact-check-needed: true
x-vsr-hallucination-detected: true
x-vsr-hallucination-spans: 1950; 500 meters
x-vsr-nli-contradictions: 2
x-vsr-max-severity: 4
For factual responses that cannot be verified due to a lack of available tools, specific headers provide transparency:
HTTP/1.1 200 OK
x-vsr-fact-check-needed: true
x-vsr-unverified-factual-response: true
x-vsr-verification-context-missing: true
These headers facilitate various actions:
- UI Disclaimers: Display warnings to users when confidence levels are low.
- Human Review Queues: Route flagged responses for manual expert review.
- Audit Logging: Track unverified claims for compliance and analytical purposes.
- Conditional Blocking: Automatically block responses containing high-severity contradictions.
The Complete Pipeline: Three Distinct Paths
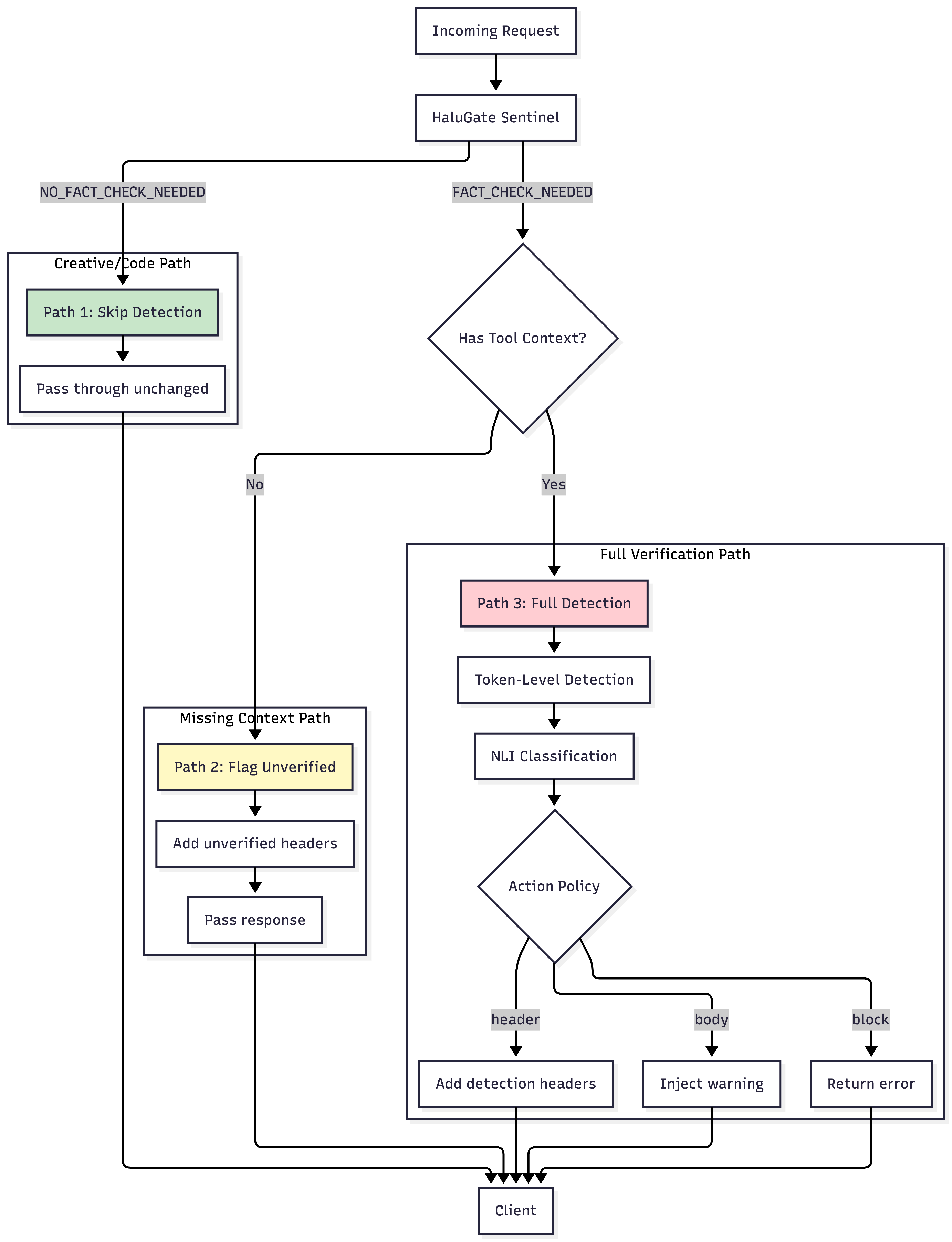
The HaluGate pipeline manages requests through three distinct paths:
| Path | Condition | Latency Added | Action |
|---|---|---|---|
| Path 1 | Non-factual prompt | ~12ms (classifier only) | Passes through |
| Path 2 | Factual + No tools | ~12ms | Adds warning headers |
| Path 3 | Factual + Tools available | 76-162ms | Full detection + headers |
Model Architecture Deep Dive
Let's examine the three specialized models that collectively power HaluGate:
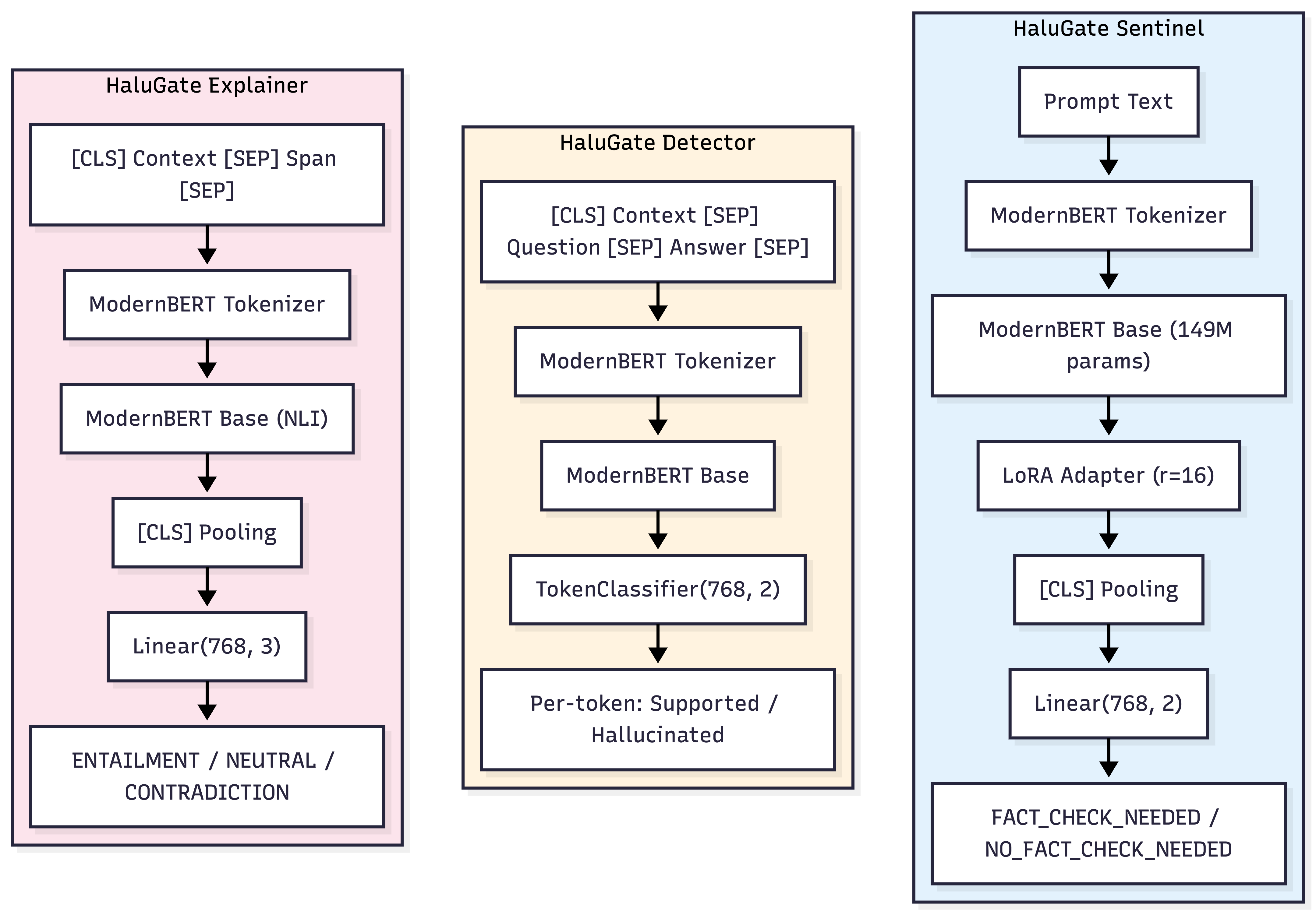
HaluGate Sentinel: Binary Prompt Classification
- Architecture: ModernBERT-base with a LoRA adapter and a binary classification head.
- Training:
- Base Model:
answerdotai/ModernBERT-base - Fine-tuning: LoRA (rank=16, alpha=32, dropout=0.1)
- Training Data: 50,000 samples meticulously gathered from 14 diverse datasets.
- Loss Function: CrossEntropy with class weights to address data imbalance.
- Optimization: AdamW, learning rate=2e-5, trained over 3 epochs.
- Base Model:
- Inference:
- Input: Raw prompt text.
- Output: (class_id, confidence).
- Latency: Approximately 12ms on CPU.
The LoRA (Low-Rank Adaptation) approach enables efficient fine-tuning, preserving the vast pre-trained knowledge while only updating a small fraction of parameters (2.2%, or 3.4M out of 149M) during training.
HaluGate Detector: Token-Level Binary Classification
- Architecture: ModernBERT-base coupled with a token classification head.
- Input Format:
[CLS] The Eiffel Tower was built in 1887-1889 and is 330 meters tall. [SEP] When was the Eiffel Tower built? [SEP] The Eiffel Tower was built in 1950 and is 500 meters tall. [SEP]^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Answer tokens (classification targets) - Output: A binary label (0=Supported, 1=Hallucinated) for each token within the answer.
- Post-processing Steps:
- Predictions are filtered to apply only to the answer segment.
- A configurable confidence threshold (default: 0.8) is applied.
- Consecutive hallucinated tokens are merged into unified spans.
- The system returns these spans along with their confidence scores.
HaluGate Explainer: Three-Way NLI Classification
-
Architecture: ModernBERT-base, specifically fine-tuned for Natural Language Inference (NLI).
-
Input Format:
[CLS] The Eiffel Tower was built in 1887-1889. [SEP] built in 1950 [SEP]^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^ Premise (context) Hypothesis (span) -
Output: A three-way classification with confidence scores:
- ENTAILMENT (0): The context unequivocally supports the claim.
- NEUTRAL (1): The claim cannot be definitively determined from the context.
- CONTRADICTION (2): The context directly conflicts with the claim.
-
Severity Mapping:
| NLI Label | Severity Score | Interpretation |
|---|---|---|
| ENTAILMENT | 0 | Likely false positive—filter out |
| NEUTRAL | 2 | Claim is unverifiable |
| CONTRADICTION | 4 | Direct factual error |
The Advantages of Native Rust/Candle Implementation
All three HaluGate models execute natively using Candle, Hugging Face’s machine learning framework written in Rust, leveraging CGO bindings for Go integration.

This architectural choice provides significant benefits:
| Aspect | Python (PyTorch) | Native (Candle) |
|---|---|---|
| Cold start | 5-10 seconds | <500ms |
| Memory | 2-4GB per model | 500MB-1GB per model |
| Latency | +50-100ms overhead | Near-zero overhead |
| Deployment | Python runtime required | Single binary |
| Scaling | GIL contention | True parallelism |
This native implementation eliminates the need for a separate Python service, sidecar containers, or external model servers, ensuring that all processing runs efficiently in-process.
Latency Breakdown
The following table outlines the measured latency for each component within the HaluGate production pipeline:
| Component | P50 | P99 | Notes |
|---|---|---|---|
| Fact-check classifier | 12ms | 28ms | ModernBERT inference |
| Tool context extraction | 1ms | 3ms | JSON parsing |
| Hallucination detector | 45ms | 89ms | Token classification |
| NLI explainer | 18ms | 42ms | Per-span classification |
| Total overhead (when detection runs) | 76ms | 162ms |
This total overhead of 76-162ms is remarkably low and negligible when compared to typical LLM generation times, which range from 5 to 30 seconds. This makes HaluGate a practical solution for synchronous request processing.
Configuration Reference
Below is a complete reference for configuring HaluGate's hallucination mitigation:
hallucination_mitigation:
# Stage 1: Prompt classification
fact_check_model:
model_id: "models/halugate-sentinel"
threshold: 0.6 # Confidence threshold for FACT_CHECK_NEEDED
use_cpu: true
# Stage 2a: Token-level detection
hallucination_model:
model_id: "models/halugate-detector"
threshold: 0.8 # Token confidence threshold
use_cpu: true
# Stage 2b: NLI explanation
nli_model:
model_id: "models/halugate-explainer"
threshold: 0.9 # NLI confidence threshold
use_cpu: true
# Signal rules for fact-check classification
fact_check_rules:
-
name: needs_fact_check
description: "Query contains factual claims that should be verified"
-
name: no_fact_check_needed
description: "Query is creative, code-related, or opinion-based"
# Decision with hallucination plugin
decisions:
-
name: "verified-factual"
priority: 100
rules:
operator: "AND"
conditions:
-
type: "fact_check"
name: "needs_fact_check"
plugins:
-
type: "hallucination"
configuration:
enabled: true
use_nli: true
hallucination_action: "header"
unverified_factual_action: "header"
include_hallucination_details: true
Beyond Production: HaluGate as an Evaluation Framework
While HaluGate is primarily engineered for real-time production deployment, its robust pipeline is equally effective for offline model evaluation. Rather than intercepting live requests, HaluGate can process benchmark datasets to systematically quantify hallucination rates across various LLMs.
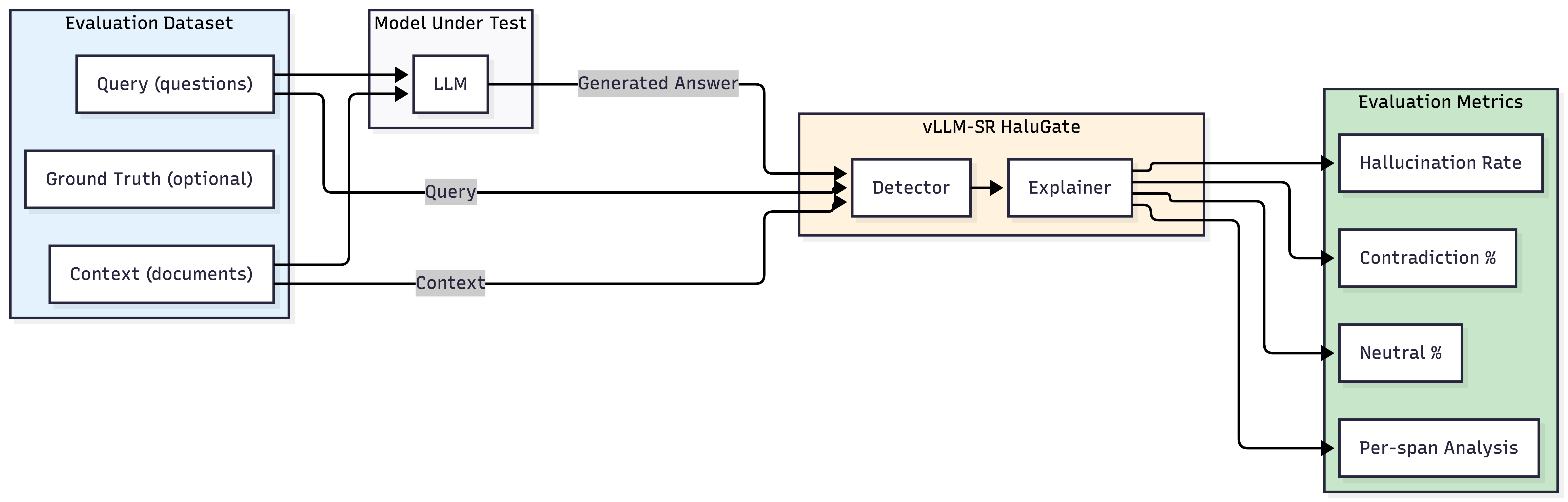
Evaluation Workflow
- Load Dataset: Utilize established QA/RAG benchmarks (e.g., TriviaQA, Natural Questions, HotpotQA) or integrate custom enterprise datasets featuring context-question pairs.
- Generate Responses: Execute the LLM under test against each query, providing the relevant context.
- Detect Hallucinations: Feed the (context, query, response) triples through the HaluGate Detector.
- Classify Severity: Employ the HaluGate Explainer to categorize the severity and type of each identified hallucinated span.
- Aggregate Metrics: Calculate crucial metrics such as overall hallucination rates, contradiction ratios, and detailed breakdowns by category.
Limitations and Scope
HaluGate is specifically designed to address extrinsic hallucinations, which occur when verification can be grounded by tool or RAG context. It has specific limitations:
What HaluGate Cannot Detect
| Limitation | Example | Reason |
|---|---|---|
| Intrinsic hallucinations | Model states “Einstein was born in 1900” without any tool call | No external context for verification |
| No-context scenarios | User asks a factual question, but no tools are defined | Absence of ground truth |
Transparent Degradation
For requests classified as fact-seeking but where tool context is unavailable, HaluGate explicitly flags responses as “unverified factual” instead of silently permitting them. This is indicated by specific HTTP headers:
x-vsr-fact-check-needed: true
x-vsr-unverified-factual-response: true
x-vsr-verification-context-missing: true
This transparent approach empowers downstream systems to manage uncertainty and unverified claims appropriately.
Conclusion
HaluGate introduces a principled and robust approach to hallucination detection for production LLM deployments, characterized by:
- Conditional Verification: Non-factual queries are intelligently skipped, while factual ones undergo rigorous verification.
- Token-Level Precision: It precisely identifies which specific claims within a response are unsupported by the context.
- Explainable Results: The NLI classification provides clear insights into why a particular claim is deemed problematic.
- Zero-Latency Integration: Leveraging native Rust inference, HaluGate integrates seamlessly without the need for Python sidecars, ensuring minimal overhead.
- Actionable Transparency: Rich HTTP headers empower downstream systems to enforce custom policies and actions.
HaluGate ensures that if your LLM calls a tool, receives accurate data, yet still generates an incorrect answer, it will be detected and addressed proactively—before it ever reaches your users.