Why Strong Consistency? A Deep Dive into Database Architectures
Explore the crucial role of strong consistency in database systems. This article details how eventual consistency complicates development and operations, and explains how Aurora DSQL delivers a robust, consistent solution.
Why Strong Consistency?
Eventual consistency, while common, often complicates application development and database operations. When I joined AWS in 2008, the EC2 control plane relied on a tree of MySQL databases: a primary for writes, a secondary for failover, and multiple read replicas for scaling reads and latency-insensitive reporting. All of this was linked with MySQL’s statement-based replication. While it generally worked day-to-day, two significant pain points have remained with me: operational costs were high, and eventual consistency led to peculiar behaviors.
Since then, managed database services like Aurora MySQL have made relational database operations orders of magnitude easier. This is a tremendous improvement. However, eventual consistency remains a characteristic of most database architectures designed to scale reads. Today, I want to delve into why eventual consistency presents significant challenges and highlight our substantial investment in ensuring all reads are strongly consistent in Aurora DSQL.
Eventual Consistency Poses Challenges for Customers
Consider a common code pattern executed against an API backed by a database service:
id = create_resource(...)
get_resource_state(id, ...)
In systems utilizing read replicas, the latter get_resource_state call can produce a bewildering result: "id does not exist". The reason is straightforward: get_resource_state is a read-only operation, likely routed to a read replica, and it's racing against the write from create_resource. If replication completes before the read, the code behaves as expected. If the client’s read occurs first, it experiences the unusual sensation of data appearing to travel backward in time.
Application programmers lack a robust, principled method to counteract this. Consequently, they often resort to patterns like this:
id = create_resource(...)
while True:
try:
get_resource_state(id, ...)
return
except ResourceDoesNotExist:
sleep(100)
This "fixes" the problem, but only partially. Especially if ResourceDoesNotExist can also be thrown when an id is deleted, this loop could become infinite. Moreover, it imposes additional work on both client and server, introduces latency, and forces the programmer to arbitrarily choose a sleep duration that balances between performance and correctness. It's an inelegant solution.
The problem is even more subtle, as Marc Bowes highlighted:
def wait_for_resource(id):
try:
get_resource_state(id, ...)
return
except ResourceDoesNotExist:
sleep(100)
id = create_resource(...)
wait_for_resource(id)
get_resource_state(id)
The final get_resource_state call could still fail. This is because it might be routed to an entirely different read replica that hasn't yet received the latest updates from the primary (3).
Strong consistency completely bypasses these issues (1), ensuring that the initial, simpler code snippet functions reliably.
Eventual Consistency is a Pain for Application Builders
The teams developing the services behind these APIs encounter identical challenges. To maximize the benefits of read replicas, application builders aim to direct as much read traffic as possible to them. However, consider the following code:
block_attachment_changes(id, ...)
for attachment in get_attachments_to_thing(id):
remove_attachment(id, attachment)
assert_is_empty(get_attachments_to_thing(id))
This is a typical pattern within microservices—a small workflow designed for cleanup. Yet, in an eventually consistent environment, it harbors at least three potential bugs:
- The
assertcould trigger because the secondget_attachments_to_thinghasn't received updates about all theremove_attachments. remove_attachmentmight fail if it hasn't learned about one of the attachments previously listed byget_attachments_to_thing.- The initial
get_attachments_to_thingcould return an incomplete list due to stale data, leading to an incomplete cleanup operation.
Numerous other issues can arise. Application builders must prevent these by ensuring that any reads used to trigger subsequent writes are directed to the primary database. This demands more complex routing logic (a simple "this API is read-only" is insufficient) and diminishes the effectiveness of read scaling by reducing traffic that can be offloaded to replicas.
Eventual Consistency Makes Scaling Harder
This leads to our third point: read-modify-write is the quintessential transactional workload. This applies to explicit transactions (e.g., UPDATE or SELECT followed by a write within a transaction) and implicit transactions (like the example above). Eventual consistency reduces the efficacy of read replicas because reads used in read-modify-write operations generally cannot be routed to replicas without encountering unpredictable side effects.
Consider this SQL statement:
UPDATE dogs SET goodness = goodness + 1 WHERE name = 'sophie'
If the goodness value for this read-modify-write operation is sourced from a read replica, the update may not occur as intended. A database could internally attempt a pattern like:
SELECT goodness AS g, version AS v FROM dogs WHERE name = 'sophie'; -- To read replica
UPDATE sophie SET goodness = g + 1, version = v + 1 WHERE name = 'sophie' AND version = v; -- To primary
...and then verify that a row was indeed updated (2). However, this adds considerable overhead.
The distinct advantage of making scale-out reads strongly consistent is that the query processor can read from any replica, even within read-write transactions. Furthermore, it doesn't need to determine upfront whether a transaction is read-write or read-only to select an appropriate replica.
How Aurora DSQL Achieves Consistent Reads with Read Scaling
As previously stated, all reads in Aurora DSQL are strongly consistent. DSQL also enables read scaling by incorporating additional replicas for any hot shards. So, how does it guarantee strong consistency for all reads? Let's recap the fundamental architecture of DSQL.
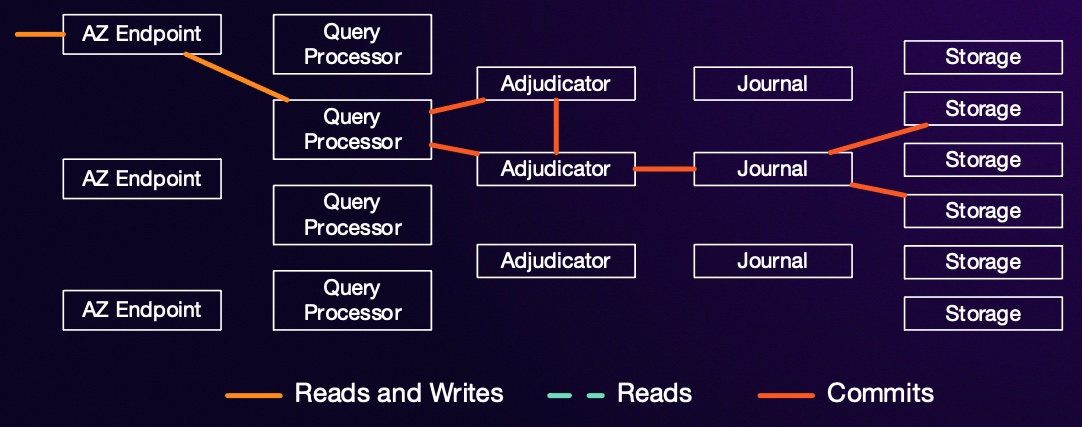
Each storage replica receives its updates from one or more journals. Writes on each journal are strictly monotonic, meaning once a storage node has processed an update from time $\tau$, it's guaranteed to have seen all updates for times $t \leq \tau$. Once it has observed updates up to $t \geq \tau$ from all subscribed journals, it can confidently return data for time $\tau$ without missing any updates. When a query processor initiates a transaction, it selects a timestamp $\tau_{start}$. For every subsequent read from a replica, it requests data "as of $\tau_{start}$". If the replica has already seen higher timestamps from all journals, it proceeds. If not, it blocks the read until the write streams have caught up.
I go into some detail on how $\tau_{start}$ is picked here.
Conclusion
While strong consistency might sound like an arcane topic for distributed systems specialists, it represents a very real challenge that applications built on traditional database replication architectures must confront at even modest scales, or at very small scales if high availability is a goal. DSQL undertakes significant internal engineering to ensure all reads are consistent, thereby sparing application builders and end-users from having to manage this inherent complexity.
This is not to say that eventual consistency is inherently bad. Latency and connectivity trade-offs certainly exist (though the "choose-two" framing of CAP is often misleading), and eventual consistency has its legitimate applications. However, its optimal place is likely not within your core services or critical APIs.
Footnotes
- This particular issue might be mitigated by weaker guarantees like "Read Your Writes," often provided by client stickiness. However, this approach quickly breaks down with more complex data models and scenarios like Infrastructure-as-Code (IaC), where "your writes" is less clearly defined.
- Yes, other methods for achieving this exist.
- Technically, this problem arises because typical database read replica patterns do not offer monotonic reads, where the set of writes a reader observes is consistently increasing over time. Instead, writes can appear and disappear arbitrarily as requests are routed to different replicas. For an accessible introduction to these concepts, refer to Doug Terry's Replicated Data Consistency Explained Through Baseball.
About the Author
Marc Brooker The opinions expressed on this site are solely my own and do not necessarily represent those of my employer. Contact: marcbrooker@gmail.com